目录
本篇想要介绍一下calico的基本原理,阐述以Calico作为CNI时pod间是如何通信的。总的来说,CNI实现主要有两种:
- 使用 overlay network,如 Flannel,它将pod与pod间的报文包裹在VXLAN报文里面,VXLAN报文会在宿主机之间流动,实际的网络链路不需要感知overlay network的任何信息。
- 使用纯路由方案,额外配置好一些路由信息,让pod与pod间流量可以被正确的转发,将宿主机作为一个路由器(文档描述是vRouter),使用BGP来同步宿主机之间的路由信息。
虽然总体上可以这样划分,但是各个CNI的功能都比较多,Flannel的host-gw方案将宿主机作为路由器,只要保证宿主机之间可以直接互通。
抓包初体验
百闻不如一见,先直接对跨节点之间pod通信抓个包,看下calico跨节点通信的基本原理。从一个pod(192.168.142.65)往另一个pod(192.168.21.13)发送报文,在他们的宿主机上抓包报文。
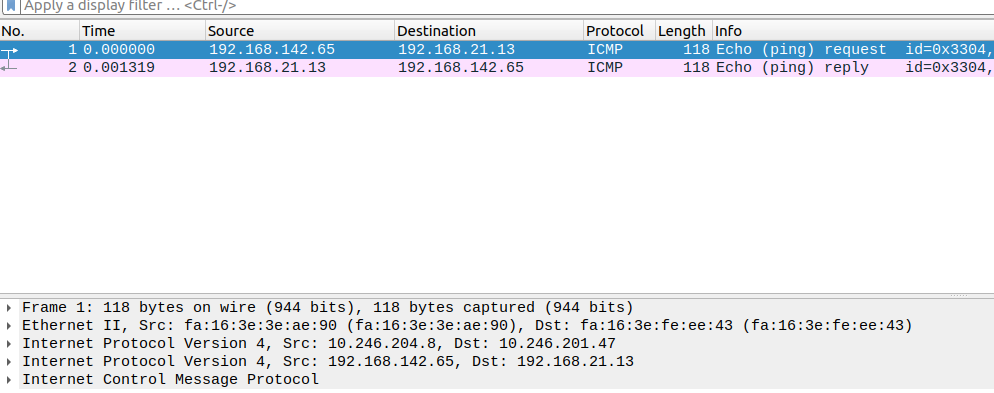
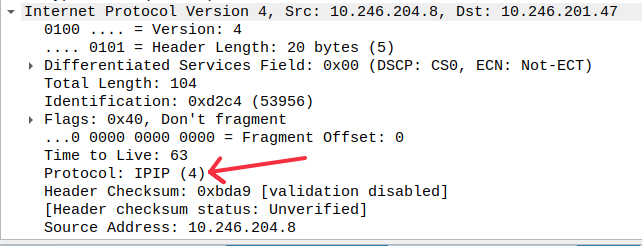
很明显可以看到pod间的报文被包在IPIP报文内。进一步查看外部IP报文的内容:
Calico 通信的基本原理
同节点内Pod间通信
如果探究过docker容器间或者是以Flannel作为CNI的pod容器间通信依赖于 bridge,calico却不依赖于bridge,它是pure layer 3的实现。要弄清楚报文的流向,不外乎从路由表、interface等信息入手,先看网络设备:
shell$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether fe:b4:13:fb:2a:28 brd ff:ff:ff:ff:ff:ff link-netnsid
tunl0是因为当ipip module被加载的时候,内核会在每一个namespace下都创建一个tunl0设备,不过它在Pod内没啥作用。eth0是老熟人了,eth0是veth pair,一端位于容器内另一端位于容器外,如同一条导线将两个namespace串起来,让它们之间可以相互通信。eth0@if7的if7表示它相对应的veth pair的另外一段位于另一个namespace(也就是root namespace)的index 7,可以自行查看。再来看看路由表的内容:
shell$ ip route
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
169.254.1.1是一个link local address,只能用于子网内通信,它的作用是当DHCP服务器还没有给机器分配IP的时候操作系统会分配这样一个地址,显然pod内没有一个网卡有这样的地址,以这样一个奇怪的地址作为网关,容器内的报文如何转发出去呢?奥秘在于 Proxy ARP,它的作用是让一个proxy server响应目标并不是给它的ARP请求。在宿主机上,calico-node会将每个calicoxxx设备的arp proxy 设置为1。示例如下:

所以,当容器访问外部网络的时候,所发起的ARP请求会被宿主机上的calixxxx设备响应,一个完整的以太网帧就在pod内组装好了,经过veth pair来到宿主机的root namespace,再查找宿主机的路由表决定它接下来应该去哪儿。这样做的好处是,将ARP广播限制在了宿主机上,不会广播到实际的集群。在任意节点上查看宿主机的路由:

192.168.x.x为首的IP地址都是当前机器上pod的IP地址,网关地址为0.0.0.0这表示这可以直接到达的host,不需要经过网关。对于不在本机的pod,需要经过本机的tunl0封装为IPIP报文再由实际的网络转发。因此,同节点内pod通信的流量的流向为: pod -> host -> pod,宿主机起到了路由器的功能,为了这一过程能够正常工作,还需要设置ip_forward。
介绍了完了基本内容以后,来模拟这个过程,下面是实验的网络拓扑图:
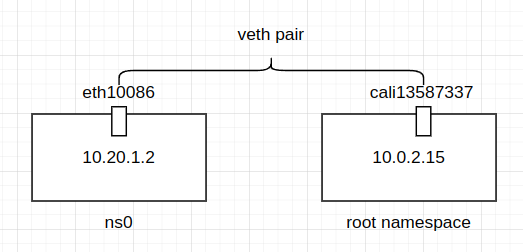
shell命令:
shell# !/bin/bash
set -e
ip link add eth10086 type veth peer name cali13587337
ip netns add ns0
ip link set eth10086 netns ns0
# 给 pod 内的veth设置ip地址
ip netns exec ns0 ip a add 10.20.1.2/24 dev eth10086
ip netns exec ns0 ip link set eth10086 up
# 设 pod 设置路由
ip netns exec ns0 ip route add 169.254.1.1 dev eth10086 scope link
ip netns exec ns0 ip route add default via 169.254.1.1 dev eth10086
ip link set cali13587337 up
# 在宿主机上路由
ip route add 10.20.1.2 dev cali13587337 scope link
echo 1 > /proc/sys/net/ipv4/ip_forward
echo 1 > /proc/sys/net/ipv4/conf/cali13587337/proxy_arp
最后在两端测试:
shell$ sudo ip netns exec ns0 ping -c 1 10.0.2.15
PING 10.0.2.15 (10.0.2.15) 56(84) bytes of data.
64 bytes from 10.0.2.15: icmp_seq=1 ttl=64 time=0.038 ms
--- 10.0.2.15 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.038/0.038/0.038/0.000 ms
$ ping -c 1 10.20.1.2
PING 10.20.1.2 (10.20.1.2) 56(84) bytes of data.
64 bytes from 10.20.1.2: icmp_seq=1 ttl=64 time=0.018 ms
--- 10.20.1.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.018/0.018/0.018/0.000 ms
同节点之间pod通信再创建一个 namespace、添加路由记录就好。
有一个疑问是: 从 pod发送到host应该没有路由中转的过程,感觉不需要ip_forward,但是如果不设置ip_forward实验却无法进行。
不同节点的Pod间通信
不同节点pod间通信主要依赖于IPIP,同样的要弄清楚报文的流转方向还是从路由表入手。

首先要阐述的是为什么tunl0分配的都是以 192.168.x.x为首的IP地址?这是因为每个节点都分配到了一个192.168.0.0/26(/26对应的掩码就是255.255.255.192)的网段,而这个IP地址又被设置为了tunl0的IP地址,形成了对应关系。另外一个注意的地方是,tunl0设备并不是一个点对点的tunnel设备,使用ip addr命令查看tunl0并没有设置peer,因此为了将报文能够转发,还需要将对端的tunnel所处的宿主机的IP地址配置为gateway。以上述为例:
shell192.168.142.64 10.246.204.8 255.255.255.192 UG 0 0 0 tunl0
表示 ip tunnel: 192.168.142.64 所处的宿主机的IP地址为10.246.204.8。总结一下跨节点的pod间通信的过程: Pod发送一个ARP报文查找169.254.1.1的mac地址,因为proxy ARP的关系被宿主机上的calixxx设备所相应,pod报文被流转到了root namespace。下一步查路由表得知需要经过tunl0,并且得知对端的tunnel0位于某个宿主机,于是一个IPIP报文被封装完毕,进过实际的物理网络转发到了目的主机,然后拆包、查路由表、转发给某一calixxx设备、经过veth设备转发进入到Pod内。
接下来使用 ip 命令模拟IPIP tunnel,IPIP tunnel可以是点对点的,也可以是full-mesh的。下面演示下点对点的IPIP tunnel:
shell# 宿主机
$ ip tunnel add tunl4399 mode ipip remote <remote_ip> local <local_ip> ttl 255
$ ifconfig tunl4399 10.42.2.1
$ route add -net 10.42.1.0/24 dev tunl4399
# 虚拟机
$ ip tunnel add tunl4399 mode ipip remote <remote_ip> local <local_ip> ttl 255
$ ifconfig tunl4399 10.42.1.1
$ route add -net 10.42.2.0/24 dev tunl4399
local_ip指代的是机器上实际可以同外部网络交互的IP地址,remote_ip是需要建立IPIP tunnel的对端机器IP地址,然后给tunnel 设备配置IP地址,以及相对应的路由记录,才能需要经过tunnel的转发到tunnel4399设备然后被封装为IPIP报文,最后经过默认路由离开机器。点对点的IPIP tunnel显著的特征是用ip addr查看设备信息可以看到有一个peer 关系:

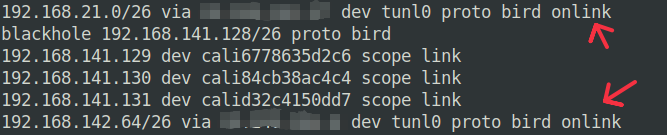
calico-node的实际操作有些不同,它没有创建额外的tunnel,而是使用了默认的tunl0(tunl0会在加载ipip module的时候默认启用),ip link查看tunl0设备会发现它没有peer关系,如下图。问题是,IPIP报文的实际物理地址应该是谁?这篇博客提到了,当内核收到 IPIP报文以后,如果内层的src ip和dst ip不符合任何一个tunnel设备的 local ip和 remote ip,那么会fallback到tunl0。tunl0再根据网关地址来决定IPIP报文往哪儿转发,calico-node将每个宿主机实际的IP地址作为IPIP tunnel的网关地址写入到了路由表,各个宿主机之间又使用 BIRD 来同步路由记录(虽然实际工作的还是BGP协议),这样各个节点就知道如何转发IPIP报文了。

下面一个节点的路由举例,tunl0后面的bird表示这条路由是由BIRD写入的:
calico的基本组件
calico的关键组件作用都可以从文档找到,这里结合自己的理解描述一些组件的基本作用,但是不一定完全正确。
- Fliex: 1. 管理节点上的网络设备,设置 ARP proxy让节点能够相应来自容器的ARP报文,并且设置ip_forward让报文能在节点的网络设备之间流转。2.管理节点的路由表,让流量去到它该去的地方,但是不同节点之间的路由信息由Fliex管理的而是BGP。
- Confd: 从calico datastore关注集群的变化(比如说一个新节点加入了集群),并且将相对应的变化刷写到BIRD的配置文件中,然后让BIRD重新加载配置文件,把路由信息通过BGP广播到集群中的其他节点。源码里
reload函数会发送一个SIGHUP信号给bird程序,calilco fork了一份bird,翻阅bird源码就可以看到bird对于SIGHUP的处理函数是更新路由信息。 - Typha: 每个calico-node容器都需要和apiserver(在文档中称为datastore,当然也可以是etcd)进行通信工作,关注各种资源的变化。所以在节点很多的集群当中,这会给apiserver带来不少压力。Typha的作用是在calico-node和apiserver之间充当一个媒介,calico-node直接与Typha通信,降低apiserver压力,文档建议是超过100个节点就要弃用typha。
- kube-controllers: 包含Policy controller,Namespace controller等几个controller,关注集群变化并且采取相应的动作,文档对于这块内容描述的比较简略的。我的理解是,比如说当创建了一个network policy时, controller将policy转为iptables规则。
cross subnet 模式
默认情况下calico都会启用IPIP,查看默认的ippool配置:
shell$ k describe ippool default-ipv4-ippool
# ... 省略了一些内容
Spec:
Allowed Uses:
Workload
Tunnel
Block Size: 26
Cidr: 192.168.0.0/16
Ipip Mode: Always
Nat Outgoing: true
Node Selector: all()
Vxlan Mode: Never
Events: <none
设置Ipip Mode: CrossSubnet或者在manifest里边设置环境变量CALICO_IPV4POOL_IPIP,同子网内的pod通信的时候直接以对方主机作为网关,省去了IPIP header的额外开销,文档。设置为cross subnet查看宿主机的路由表,以第一行为例表示172.18.6.0/26这个网段内的pod都转发给192.168.1.68节点,直接走eth0设备,这些路由信息也是由BIRD同步的。
shell$ ip route | grep 172.18 | grep --color 192.168.1
172.18.6.0/26 via 192.168.1.68 dev eth0 proto bird
172.18.14.128/26 via 192.168.1.66 dev eth0 proto bird
172.18.15.128/26 via 192.168.1.63 dev eth0 proto bird
172.18.17.192/26 via 192.168.1.5 dev eth0 proto bird
calico-node BIRD配置文件
calico 的manifest会创建一个名为calico-node的daemonset,每个calico-node pod里面都包含了必须的 BRID(一个BGP,OSPF等协议的开源实现)必要的配置文件,所处的路径是/etc/calico/confd/config,这些文件都可以从calico repo内找到。
shell$ls -l /etc/calico/confd/config
-rw-r--r-- 1 root root 4307 Jun 25 07:53 bird.cfg
-rw-r--r-- 1 root root 1965 Feb 18 08:50 bird6.cfg
-rw-r--r-- 1 root root 173 Feb 18 08:50 bird6_aggr.cfg
-rw-r--r-- 1 root root 375 Feb 18 08:50 bird6_ipam.cfg
-rw-r--r-- 1 root root 419 Feb 18 08:50 bird_aggr.cfg
-rw-r--r-- 1 root root 1505 Jun 14 11:49 bird_ipam.cfg
calico-node 将其中关键的进程都使用runsv管理的,进入路径/etc/service/enabled可以看到这些进程的信息:
shell$ls -l /etc/service/enabled
drwxrwxr-x 3 root root 4096 Aug 3 08:31 allocate-tunnel-addrs
drwxrwxr-x 3 root root 4096 Aug 3 08:31 bird
drwxrwxr-x 3 root root 4096 Aug 3 08:31 bird6
drwxrwxr-x 3 root root 4096 Aug 3 08:31 cni
drwxrwxr-x 3 root root 4096 Aug 3 08:31 confd
drwxrwxr-x 3 root root 4096 Aug 3 08:31 felix
drwxrwxr-x 3 root root 4096 Aug 3 08:31 monitor-addresses
drwxrwxr-x 3 root root 4096 Aug 3 08:31 node-status-reporter
进入到每个子目录,以confd为例/etc/service/enabled/confd/supervise,内有一个pid文件包含的是进程的pid,在进入到/proc/$PID可以查阅该进程的各种信息。一篇 tigera 的写于 2019年的老文的描述是 confd 直接从 etcd 读取一些数据,并且将其转为对应的BIRD配置文件。查阅了现在版本的calico源码,calico-node现在的实现是watch 机制从apiserver读取相关数据的。本小节不过多介绍confd本身的内容,着重学习几个BIRD 配置文件,本小节描述的配置文件内容都是默认配置(full-mesh bgp,calico还支持route-reflector)。
bird_aggr.cfg
bird相关的配置文件中,最重要的是bird.cfg,剩下的bird_aggr.cfg和bird_ipam.cfg将会作为头文件形式被引入到bird.cfg,所以我们先来看这两个文件的内容。
shell# Generated by confd
protocol static {
# IP blocks for this host.
route 192.168.141.128/26 blackhole;
}
# Aggregation of routes on this host; export the block, nothing beneath it.
function calico_aggr ()
{
# Block 192.168.141.128/26 is confirmed
if ( net = 192.168.141.128/26 ) then { accept; }
if ( net ~ 192.168.141.128/26 ) then { reject; }
}
protocol static 配置的作用是: 任何dst ip 为 192.168.141.128/26 网段的ip报文都会被直接丢弃。192.168.141.128/26这个网段是calico分配给当前节点上pod的IP段,使用kubectl describe node查阅即可确认,在节点上用ip route 查看路由记录。使用ping -I eth0 192.168.141.128可以发现ICMP报文是回不来的,因为发送到了一个blackhole。
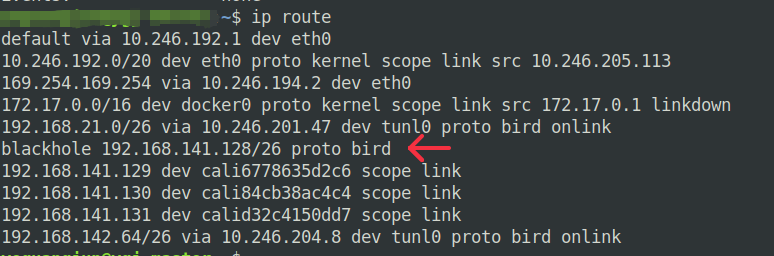
192.168.141.128又是节点上IP tunnel的ip地址,因此函数function calico_aggr ()的作用是只通告IP地址等于net = 192.168.141.128/26的路,任何其他位于该网段内的路由记录都拒绝。结合到实际的网络情况,就是将每个宿主机的tunl0广播到集群的各个宿主机,但是将每个节点上的Pod 路由记录限定在了它们所处的宿主机上。
bird_ipam.cfg
shellfunction reject_disabled_pools ()
{
}
function calico_export_to_bgp_peers () {
# filter code terminates when it calls `accept;` or `reject;`, call reject_disabled_pools() first, then apply_communities() and then calico_aggr()
reject_disabled_pools();
apply_communities();
calico_aggr();
if ( net ~ 192.168.0.0/16 ) then {
accept;
}
}
filter calico_kernel_programming {
if ( net ~ 192.168.0.0/16 ) then {
krt_tunnel = "tunl0";
accept;
}
accept;
}
calico 支持多个ippool,可以将一批节点划分到ippool-1,另外一批节点划分到ipool-2,也支持ippool的切换。这两部分可以参考文档:划分不同pod到不同的ippool和ippool迁移,在ippool迁移的场景中,原先的ipool被废弃(处于disable状态),相关的路由记录就会注册到function reject_disabled_pools这个函数体内。function calico_export_to_bgp_peers这个函数会被bird.cfg内进一步被调用,它的作用是控制哪些路由记录将会被通告到其他bgp peer。
在默认的配置下,calico用的是IPIP,filter calico_kernel_programming 这是一个过滤器,会在bird.cfg内被使用,它的目的是位于192.168.0.0/16网段内的路由都走tunl0设备。如果配置了 cross subnet,那么这里会有些许变化,下面是一个 cross subnet 的配置示例:
shellif ( net ~ 172.17.0.0/16 ) then { if defined(bgp_next_hop) && ( bgp_next_hop ~ 192.168.1.0/24 ) then krt_tunnel = ""; else krt_tunnel = "tunl0"; accept; }
这份配置的意思是,如果下一跳 bgp peer的地址位于192.168.1.0/24,就不需要经过 tunl0设备,否则需要进行IPIP的封装。问题是,为什么同子网不需要使用tunl0设备?两个节点如果位于同一个子网内,那么它们二层直接可达,因此不需要封装为IPIP报文可以直接通信,跨子网的话就只能通过IPIP才能时间pod间通信了。
bird.cfg
这是整个BIRD配置文件的关键部分。
shellfunction apply_communities ()
{
}
# Generated by confd
include "bird_aggr.cfg";
include "bird_ipam.cfg";
router id 10.246.205.113;
# Configure synchronization between routing tables and kernel.
protocol kernel {
learn; # Learn all alien routes from the kernel
persist; # Don't remove routes on bird shutdown
scan time 2; # Scan kernel routing table every 2 seconds
import all;
export filter calico_kernel_programming; # Default is export none
graceful restart; # Turn on graceful restart to reduce potential flaps in
# routes when reloading BIRD configuration. With a full
# automatic mesh, there is no way to prevent BGP from
# flapping since multiple nodes update their BGP
# configuration at the same time, GR is not guaranteed to
# work correctly in this scenario.
merge paths on; # Allow export multipath routes (ECMP)
}
# Watch interface up/down events.
protocol device {
debug { states };
scan time 2; # Scan interfaces every 2 seconds
}
protocol direct {
debug { states };
interface -"cali*", -"kube-ipvs*", "*"; # Exclude cali* and kube-ipvs* but
# include everything else. In
# IPVS-mode, kube-proxy creates a
# kube-ipvs0 interface. We exclude
# kube-ipvs0 because this interface
# gets an address for every in use
# cluster IP. We use static routes
# for when we legitimately want to
# export cluster IPs.
}
# Template for all BGP clients
template bgp bgp_template {
debug { states };
description "Connection to BGP peer";
local as 64512;
gateway recursive; # This should be the default, but just in case.
graceful restart; # See comment in kernel section about graceful restart.
connect delay time 2;
connect retry time 5;
error wait time 5,30;
}
# -------------- BGP Filters ------------------
# No v4 BGPFilters configured
# ------------- Node-to-node mesh -------------
# For peer /bgp/v1/host/ygj-master/ip_addr_v4
# Skipping ourselves (10.246.205.113)
# For peer /bgp/v1/host/ygj-worker-1/ip_addr_v4
protocol bgp Mesh_10_246_204_8 from bgp_template {
neighbor 10.246.204.8 as 64512;
source address 10.246.205.113; # The local address we use for the TCP connection
import all; # Import all routes, since we don't know what the upstream
# topology is and therefore have to trust the ToR/RR.
export filter {
calico_export_to_bgp_peers();
reject;
}; # Only want to export routes for workloads.
}
# For peer /bgp/v1/host/ygj-worker-2/ip_addr_v4
protocol bgp Mesh_10_246_201_47 from bgp_template {
neighbor 10.246.201.47 as 64512;
source address 10.246.205.113; # The local address we use for the TCP connection
import all; # Import all routes, since we don't know what the upstream
# topology is and therefore have to trust the ToR/RR.
export filter {
calico_export_to_bgp_peers();
reject;
}; # Only want to export routes for workloads.
}
# ------------- Global peers -------------
# No global peers configured.
# ------------- Node-specific peers -------------
# No node-specific peers configured.
整个配置文件的内容比较长,BIRD实现了很多路由协议,除此以外还有一些假的路由协议,有kernel,device,direct等。每种protocol的意义各不相同,详细的需要参阅文档,这里以kernel 为例, protocol kernel 的作用是持续不断的将BIRD自己的路由表(位于内存中)和内核的路由表同步(ip route查看到的内容),文档的描述是:
he Kernel protocol is not a real routing protocol. Instead of communicating with other routers in the network, it performs synchronization of BIRD's routing tables with the OS kernel. Basically, it sends all routing table updates to the kernel and from time to time it scans the kernel tables to see whether some routes have disappeared (for example due to unnoticed up/down transition of an interface) or whether an
alien' route has been added by someone else (depending on thelearn` switch, such routes are either ignored or accepted to our table).
其余的各种protocol 不在一一赘述,下面解释配置文件本身的内容:
-
router id 10.246.205.113: 本机 id,但是它实际的值就是本机的ipv4地址。
-
protocol kernel: 同步BIRD和内核之间的路由表,
export filter calico_kernel_programming;是将满足过滤器条件的路由记录全都通告出去,结合前面的内容,目的是bgp 邻居之间相互通告,所有192.168.0.0/16之间的流量都走tunl0设备,这就是calico实现跨节点pod通信的基本。 -
protocol device: 扫描宿主机的网络设备,BIRD会固定的时间间隔从这些网络设备获取所需信息。
-
protocol direct: 自动导入所有内核创建的内核记录。它的作用是将
protocol device扫描到的所有设备所生成的默认路由导入,可以参考这篇博客。但是忽略了interface -"cali*", -"kube-ipvs*"这些设备。 -
template bgp bgp_template:
procotol bgp的模板,默认情况下的calico使用的是full mesh,每个节点之间都是互相为 BGP 邻居关系,节点越多就会有越多的bgp 邻居,而这些节点之间的 bgp 配置都是由这个模板生成。neighbor 10.246.201.47 as 64512表示与10.246.201.47互为邻居,as(Autonomous System) 为64512.BGP 是基于 tcp,配置项source address 10.246.205.113;设定了 tcp 连接的 src ip。import all;从邻居那边导入所有的路由记录。bgp 所有的端口号是 179,在节点上也可以查阅到相关的tcp 连接:
shell$ sudo netstat -atnp | grep 179 tcp 0 0 0.0.0.0:179 0.0.0.0:* LISTEN 64716/bird tcp 0 0 10.246.205.113:37279 10.246.201.47:179 ESTABLISHED 64716/bird tcp 0 0 10.246.205.113:52781 10.246.204.8:179 ESTABLISHED 64716/bird
参考资料
https://bird.network.cz/?get_doc&f=bird.html&v=20 BIRD的文档
https://blog.kintone.io/entry/bird 一篇介绍BIRD各种配置项的博客,比BRID官网好懂
https://www.tigera.io/blog/kubernetes-networking-with-calico/ 19年的文章,介绍了calico的基本工作原理,但是当中的部分内容有些过时
https://docs.tigera.io/calico/latest/reference/architecture/overview 来自calico文档,介绍了calico的基本架构,不过有些粗略
https://www.tigera.io/blog/configuring-route-reflectors-in-calico/ 介绍了如何配置BGP route reflector 来减少集群网络压力
https://liuhangbin.netlify.app/post/virtual-iface-tunnels/ 这篇提到了如果IPIP tunnel 配置了 any将会作为任何IPIP报文的 fallback
https://morven.life/posts/networking-3-ipip/ IPIP相关博客,模拟了full-mesh形式的IPIP tunnel。
https://medium.com/@samueldarwin/full-mesh-ipip-tunnels-d16888913e40
https://www.cnblogs.com/janeysj/p/14804986.html 介绍了配置BGP节点来进行跨集群通信
本文作者:strickland
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!