目录
默认的calico-node之间是full mesh形式的,即所有calico-node之间都会建立BGP连接,如果有200个节点就在整个集群一共建立了4w个BGP连接,当集群节点数量比较多时,路由信息的变更都会带来集群流量的激增,在混合云环境中会带来额外的成本开销,也会对集群应用造成影响。参考网络上的文档,如果集群规模超过100个节点就推荐使用route reflector,本篇记录下我对于集群中自有节点和公有云节点部署route reflector的过程。
Update: 新增了calico跨集群通信的测试方案。
实施过程
我期望的形式自由节点和公有云节点各自都是用route reflector,route reflector之间full mesh同步路由。基本的网络拓扑如下:
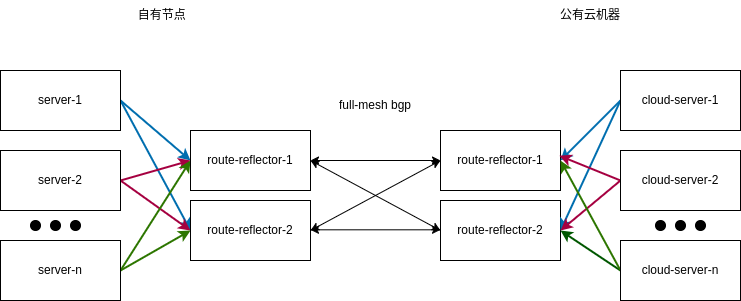
自有节点的rr节点划分为rr-partition=A,公有云节点划分为rr-parition=B(用kubectl label对这些节点打标签,下面对左侧成为分区1,右侧称为分区2),所有的rr节点之间都应该是full mesh的(图中有些线条没画,作了一定简化),实施过程直接按照文档。
第一步: 对所有的rr节点设置Cluster ID,分区1和分区2的rr节点多共享Cluster ID,在实践中多个rr节点是否共享Cluster ID都是可行的,这块内容后面还有讨论。使用命令:
kubectl annotate node my-node projectcalico.org/RouteReflectorClusterID=244.0.0.1
第二步: 按照你的网络结构对节点进行划分
kubectl label node my-node rr-partition=A
第三步:分区1的client节点(非rr节点)需要和rr节点建立BGP关系,rr节点之间需要full mesh,分区2也是同理。所有的rr节点之间full mesh,这样只有公有云和私有云之间只有rr节点需要交换路由信息,节省了不少带宽费用。BGP peer的配置支持各式各样的 selector,能够帮助我们实现灵活的网络配置。
shell# non-public cloud
# 私有云节点设置route reflector
calicoctl apply -f - << EOF
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: node-rr-partition-a
spec:
nodeSelector: cloud-type != 'public'
peerSelector: rr-partition == 'A'
EOF
# public cloud
# 公有云节点设置route reflector
calicoctl apply -f - << EOF
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: node-rr-partition-b
spec:
nodeSelector: cloud-type == 'public'
peerSelector: rr-partition == 'B'
EOF
# rr-full-mesh
# 所有rr节点之间full mesh
calicoctl apply -f - << EOF
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: rr-full-mesh
spec:
nodeSelector: has(rr-partition)
peerSelector: has(rr-partition)
EOF
第四步:从full mesh切换到route reflector
shellcalicoctl patch bgpconfiguration default -p '{"spec": {"nodeToNodeMeshEnabled": false}}'
默认情况下这个bgpconfiguration是不存在的,可以用示例的创建一个default bgpconfiguration(创建该配置需要用cailcoctl,而不是kubectl),移除它的其他各种配置,只保留nodeToNodeMeshEnabled这项就好。路由的变更可能会导致应用的连接中断,按照文档的做法可以避免中断的情况。
上述步骤执行完了以后,在各个节点可以确认用calicoctl node status确认下bgp 连接的状态。如果需要从rr 模式切换回ful mesh,执行以下操作:
- 开启 full mesh,
calicoctl patch bgpconfiguration default -p '{"spec": {"nodeToNodeMeshEnabled": true}}' - 将 route-reflector 节点的ClusterId移除,
kubectl annotate node $NODE projectcalico.org/RouteReflectorClusterID- - 删除所有bgppeer配置,运行
calicoctl node status确认bgp状态
配置文件的变更
route-reflector 节点会与每个client都建立bgp peer关系,因此calico-node中配置文件有相当多的bgp配置,基本和下面配置类似:
shellprotocol bgp Node_10_246_205_113 from bgp_template {
ttl security off;
multihop;
neighbor 10.246.205.113 as 64512;
source address 10.246.201.47; # The local address we use for the TCP connection
import filter {
accept; # Prior to introduction of BGP Filters we used "import all" so use default accept behaviour on import
};
export filter {
calico_export_to_bgp_peers();
reject; # Prior to introduction of BGP Filters anything not explicitly exported through calico_export_to_bgp_peers()
# was rejected so use default reject behaviour on export
}; # Only want to export routes for workloads.
# 与full-mesh相比就是多了下面两行配置
rr client;
rr cluster id 10.246.201.47;
}
配置 rr client表示该节点成为了一个 route reflector,配置rr cluster id表示route reflector所属的 Cluster ID是10.246.201.47,Cluster ID并不一定是一个节点的IP地址,它只是一个标识,对于Cluster ID的讨论可以看参考资料的第三和第四篇文档。
我简要的概括一下,如果多个节点共享一个 Cluster ID,那么所有的 rr client(不是指bird 配置文件中的 rr client,而是实际与route reflector建立 bgp peer关系的client节点)都需要与route reflector 建立 BGP peer,因为共享 Cluster ID会导致 rr节点之间丢弃他们同步的路由,反过来说。如果client只与一部分 rr 节点建立了 BGP peer,又因为 rr 节点之间直接同步的路由会被丢弃,那么部分节点的路由永远无法到达部分 rr 节点。
另外一个策略就是不共享 Cluster ID,缺点是配置稍微复杂些,如果每个rr节点独占 Cluster ID,这似乎会引入单点风险(第四篇文档说这会降低单点风险,没有明白其中逻辑)。
跨集群的网络互通
calico 建立与 BGP 之上,这让组网也带来了很多可能。这里我介绍一下跨集群互通的方案:
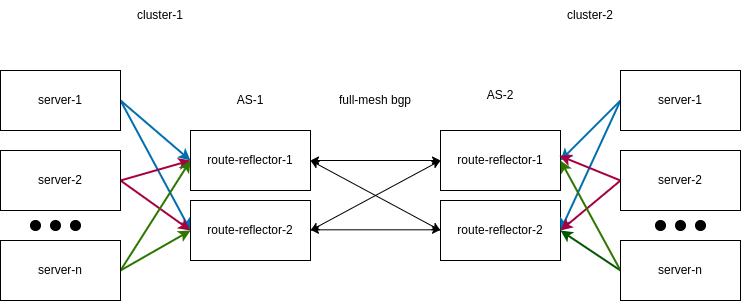
总体的结构与前面的差不多,关键的是跨集群互通时路由反射器之间要用不同的ASN,每个集群使用各自的路由反射器,route reflector之间 full mesh,限于节点数量,我的实验中每个集群的route reflector都只有一个。
shell# 设置两个集群的 asNumber
calicoctl patch bgpconfiguration default -p '{"spec": {"asNumber": "63400"}}'
calicoctl patch bgpconfiguration default -p '{"spec": {"asNumber": "63401"}}'
# 创建 bgppeer
calicoctl apply -f - << EOF
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: rr-external-node
spec:
node: $NODE_NAME
peerIP: $TARGET_NODE_IP
asNumber: $ASN
EOF
node: $NODE_NAME是集群中实际的route reflector节点的hostname,peerIP: $TARGET_NODE_IP对端集群的route reflector的IP地址,asNumber: $ASN对端集群的ASN,两个集群需要使用不同的ASN,并且asNumber一定需要设置,否则会出现错误:
shellbird: /etc/calico/confd/config/.bird.cfg3257572033: 114:1 remote as number must be set
接下来创建ippool,目的是告诉calico-node需要通告哪些子网的路由,跨集群互通的目的是节点需要有到达对端集群的路由记录。calico-node pod的bird_ipam.cfg里面有一个函数calico_export_to_bgp_peers,控制着那些路由需要广播出去。
shellfunction calico_export_to_bgp_peers () {
# filter code terminates when it calls `accept;` or `reject;`, call reject_disabled_pools() first, then apply_communities() and then calico_aggr()
reject_disabled_pools();
apply_communities();
calico_aggr();
if ( net ~ 172.16.0.0/16 ) then {
accept;
}
# 如果不增加 ippool,calico-node就不会增加下面的语句,导致对端集群的路由无法同步到集群的所有节点。
if ( net ~ 172.28.0.0/16 ) then {
accept;
}
}
如果没有增加ippool,会导致route reflector虽然可以学习到对端集群的路由信息(可以在route reflector节点看到路由记录,但是其他节点没有这些记录)。默认情况下,calico-node的felix会在节点的iptables插入一些规则:
shell# 这条规则位于第二条个规则之前,目的是只接受那些处于 ipset cali40all-hosts-net 所允许的IP地址的IPIP报文
-A cali-INPUT -p ipencap -m comment --comment "cali:PajejrV4aFdkZojI" -m comment --comment "Allow IPIP packets from Calico hosts" -m set --match-set cali40all-hosts-net src -m addrtype --dst-type LOCAL -j ACCEPT
# 丢弃任何来自非calico-node节点的IPIP
-A cali-INPUT -p ipencap -m comment --comment "cali:_wjq-Yrma8Ly1Svo" -m comment --comment "Drop IPIP packets from non-Calico hosts" -j DROP
对calico-node的环境变量增加FELIX_EXTERNALNODESCIDRLIST,加上对端集群的CIDR。
yaml- name: FELIX_EXTERNALNODESCIDRLIST
value: "10.246.0.0/16" # 以你实际的CIDR为准,仅作示例
或者是在felixconfiguration中设置:
yamlapiVersion: projectcalico.org/v3
kind: FelixConfiguration
metadata:
name: default
spec:
externalNodesList:
- 10.219.204.207/32 # node CIDR from other clusters
两者是等效的,只是环境变量具有更高的优先级。 查看ipset的内容:
shell$ sudo ipset --list cali40all-hosts-net
Name: cali40all-hosts-net
Type: hash:net
Revision: 6
Header: family inet hashsize 1024 maxelem 1048576
Size in memory: 704
References: 2
Number of entries: 4
Members:
10.246.0.0/16 # 对端集群的CIDR
10.246.205.113
10.246.204.8
10.246.201.47
一个新学习到的内容是,可以在calico-node内用birdcl查看路由的一些内容,这部分还是参考issue。
注意点:
每个集群的ippool的网段需要不存在重叠,calico 默认的ippool是172.16.0.0/16。如果ippool重叠,两个集群会出现相同的PodIP,显然这是有问题的。
参考资料
https://www.tigera.io/blog/configuring-route-reflectors-in-calico/ 一篇比较老的文章,介绍了rr的基本配置过程
https://docs.tigera.io/calico/latest/networking/configuring/bgp 配置rr的官方文档
https://orhanergun.net/bgp-route-reflector-clusters 介绍了和cluster ID有关的内容
https://networkdirection.net/articles/routingandswitching/routereflectordesign/ 介绍了和cluster ID有关的内容
https://bird.network.cz/?get_doc&v=20&f=bird-6.html#ss6.3 BIRD 配置文件文档
https://github.com/projectcalico/calico/issues/1942 calico 跨集群互通相关的issue
本文作者:strickland
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!