目录
初次接触k8s最让我感到复杂的是网络,CNI所涉及的技术名词太多,每种不同类型的CNI都有一套各自的实现。本篇的目的是flannel为切入点对k8s集群pod之间通信有个基本的理解。当然我也不是专业的网工,所以内容不够详尽,只能尽可能描述我所理解的内容。本篇参考了不少网上其他人的博客,更像是内容的缝合。
环境准备
下面是一些命令所对应的包。
ip:
shellapt -y install iproute2
route,arp命令:
shellapt -y install net-tools
ping:
shellapt -y install iputils-ping
brctl:
shellapt -y install bridge-utils
nslookup,dig命令:
shellapt -y install dnsutils
集群搭建使用的是minikube,因为minikube支持各种类型的cni,是学习cni很好的一个解决方案,之前的某个版本的minikube(1.26.x)使用flannel有问题,更新到新版本以后就可以避免,相关issue:https://github.com/kubernetes/minikube/issues/14965
使用minikube创建一个以flannel为cni双节点集群,如果尝试不同模式(UDP,host-gw)的flannel,应该可以手动制定flannel的yaml配置文件,不过未尝试,至少minikube的文档是有该内容的。
shell$ minikube start --nodes=2 --cni=flannel
K8s的网络模型
这一段描述主要参考自《k8s in action》书有点老并且内容上有些偏差,书里边描述同节点pod间通信会经过bridge,实际上这在不同的CNI之间有不同的实现方式。至少,calico不是这样的,flannel则确实使用bridge。
k8s 所要求的网络是每一个pod都有自己独立的IP地址,并且这中间不存在NAT转换,不过 k8s 本身并不负责 pod 之间的网络通信,这些工作都交给了网络查件(Ccontainer Network Interafce,CNI)。各个网络插件的实现各不相同,这里暂时不对网络插件做过多介绍,只介绍k8s 要求的网络模型。
k8s 并不要求pod之间是如何进行网络通信的,它唯一的要求是 pod 之间的 必须是独立的,无论他们是否运行在相同的节点当中,并且不能存在NAT转换。换而言之,一个网络包由发送方发给接收方,接收方看到的源IP就是发送方的IP地址。示意图如下:
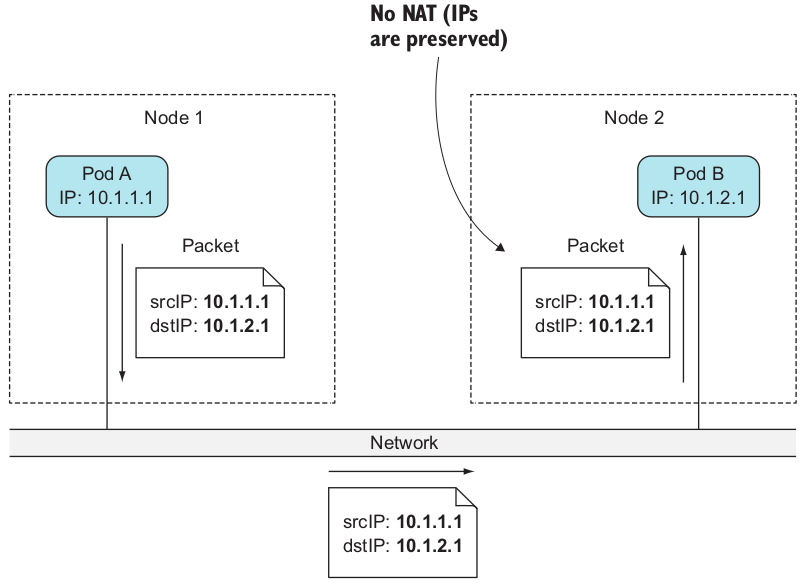
并且pod->node,node->pod这些通信都要求不存在任何NAT转发。不过当一个pod需要访问集群外的服务的时候,此时它所发出的网络包的源IP地址是私有的,因此该IP地址要被修改为宿主机的IP才可以从网卡出去。
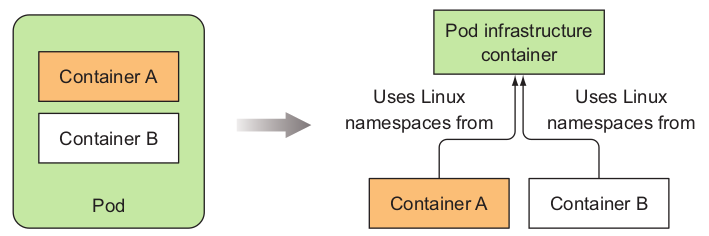
一个pod内都会有一个基本容器(infrastructure container)叫做pause容器,它是该pod内的各种namespace实际的创建者,其他容器都处于这些namespace内部,这也解释了为什么pod内的容器之间可以直接通过 localhost 通信,因为它们都处于同一个network namespace。示意图如下:
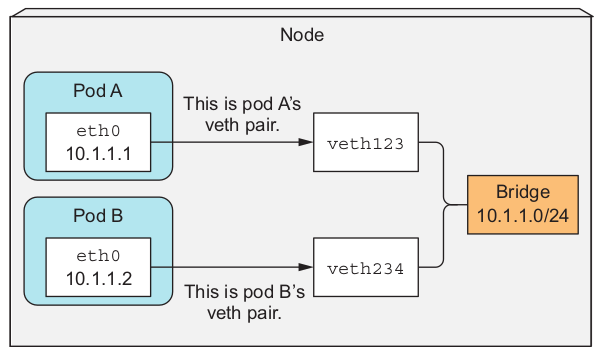
对于同一节点内的所有pod,他们之间的通信就是依赖于bridge,就好像docker 容器之间的通信那样。pod 内容器的流量先发到自己的 eth0(veth),然后在从宿主机的 veth 出来,接着流量再被转发到 bridge。注意,docker 容器所分配到的 IP 地址是由bridge指定的。总体这个过程示意图如下:
不同节点pod之间通信可以经过overlay网络或者是underlay网络,下面演示了两个位于不同节点的pod经过三层网络转发的情景(这里指代的意思应该是不借助任何网络插件?类似于路由直连)。这种情况需要将宿主机的网卡也加入到网桥当中,并且需要将Node A 的路由表进行配置,将10.1.2.0/24流量直接转发到NodeB,相类似的在NodeB中将10.1.1.0/24直接转发到NodeA。
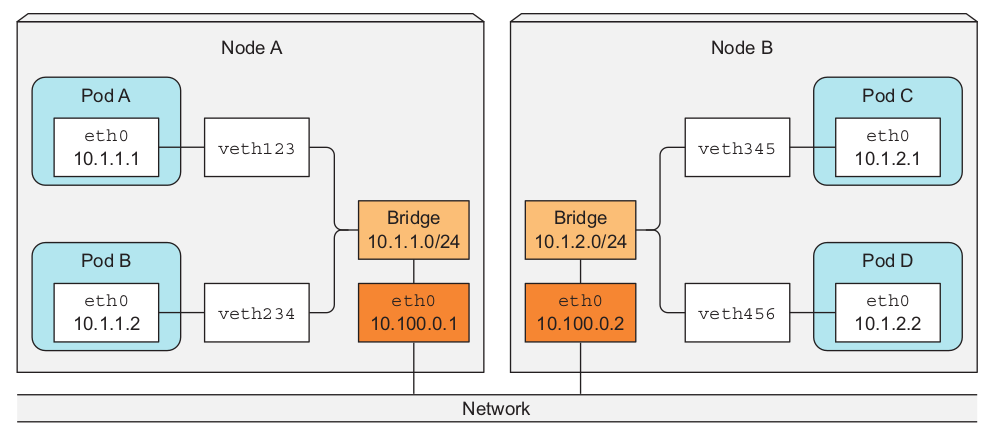
当假如Pod A的流量需要到达Pod D,那么路径就是: 流量 -> veth -> 另一端 veth pari -> bridge -> 宿主机物理网卡,然后以相反的链路到达目的pod。
概括的来说,k8s点网络模型有四个基本的保证:
- 集群里的每个pod的ip地址是唯一的
- pod内的所有容器共享这个IP地址
- 集群内的pod同属于一个网段
- Pod与Pod之间是不存在NAT
抓包初体验
在正式介绍flannel以及相关的技术以前,先试用tcpdump来对minikube来抓个包,对它有基本的认识。
shell# 启动一个 nginx daemonset
$ k applly -f nginx-ds.yaml
$ k get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-4d89j 1/1 Running 0 106s 10.244.1.2 minikube-m02 <none> <none>
nginx-b859d 1/1 Running 0 106s 10.244.0.3 minikube <none> <none>
# 进入到一个pod,并且往另外一个pod 发送数据
# 我们要抓取的流量是: minikube-m02 -> minikube
$ k exec -it nginx-4d89j -- bash
# 进入到节点抓包
$ minikube ssh -n minikube-m02
$ sudo tcpdump -i eth0 -n udp -w
09:59:12.716877 IP 192.168.49.3.48927 > 192.168.49.2.8472: OTV, flags [I] (0x08), overlay 0, instance 1 IP 10.244.1.2 > 10.244.0.5: ICMP echo request, id 89, seq 15, length 64
# 将数据从 minikube复制到本地用 wireshark 打开
$ minikube cp minikube-m02:/home/docker/log.pcap log.pcap
$ wireshark log.pcap
wireshark的截图如下:
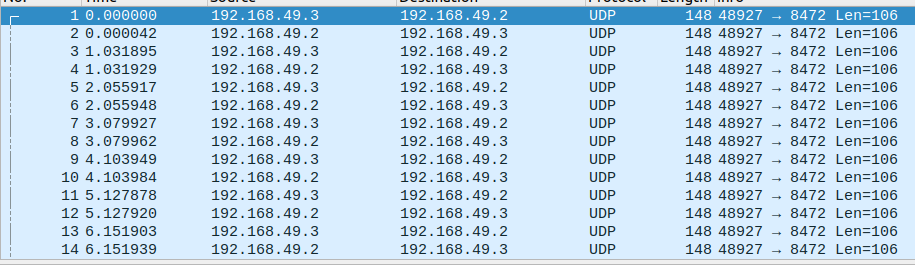
之所以我们抓取的是udp报文而不是icmp报文,是因为flannel所使用的vxlan是以udp为承载协议的,右键点击任意一条报保温,decode as 然后选择vxlan就可以看到imcp报文。
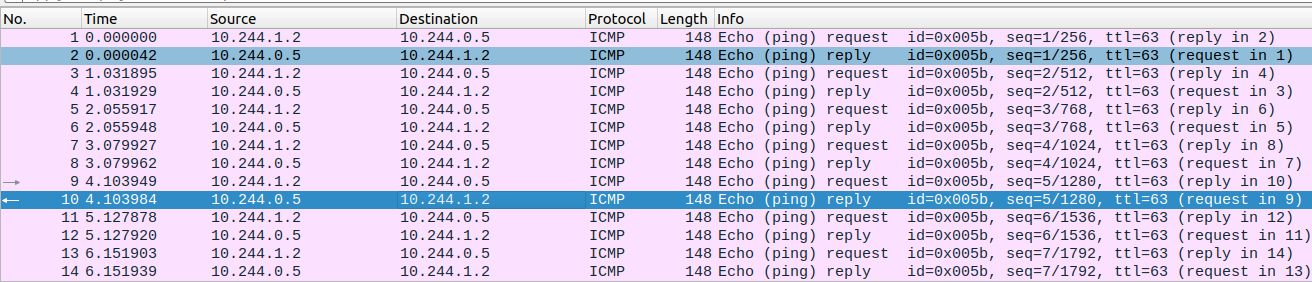
从这个短暂的体验,有几个问题是呼之欲出的:
- 为什么icmp报文会被包在udp内部,进而在两个node之间通信?
- 什么是vxlan?
本篇的内容也正是围绕着这两个问题展开的。
网络基础
overlay network
所谓overlay network是指网络建立在另外一种网络之上的虚拟网络。
An overlay network is a computer network that is layered on top of another network. -- wiki
比如说两个不同节点上的 pod,两者之间可以直接通过ip访问,但是这个ip是虚拟网络IP地址,没有一个实际的物理设备与这个IP地址所绑定。两个pod通信还是依赖于他们所在的物理节点之间的物理意义上的网络交互,使用的还是TCP或者UDP。用于实现虚拟网络的协议有很多,知名的有GRE、VXLAN、STT。Flannel默认就是采用VXLAN,后续我们也会继续介绍VXLAN的内容。
Note:
overlay 与 tunneling有些概念上的类似,从我的理解来看,tunneling很明确指的是一种网络协议将作为数据部分被另外一种协议所发送,一个例子就是如何在往不支持IPv6协议的网络设备上转发IPv6报文,一个可行的方法就是将IPv6包在IPv4报文里边,这种被称为IPv6 over IPv4 tunneling。
overlay network 更加强调的是,基于现有的网络之上构建的一种新的虚拟网络协议,需要引入了额外的header来完成对报文的封装,虽然也将不同一种网络协议的报文作为数据内容放到其他协议的报文。
VLAN
VXLAN全称为Virtual Extensible LAN (VXLAN) ,显而易见是在一定程度上对VLAN的过程,所以简单的学习下VLAN,以及VLAN的缺陷。VLAN(Virtual LAN)是一个广播域的概念,广播域是指广播报文(多播也是如此)可以直接到达(我的理解是不经过路由器)的范围(也就是LAN的范围)。如果LAN的范围相当大,那么各种广播报文会对交换机和其他主机都会造成影响。VLAN的作用是对这些主机进行划分,将广播报文可以到达范围缩小,一个主机都会有与自己像绑定的VLAN ID,如下图-来自《趣谈网络协议-极客时间-刘超》:
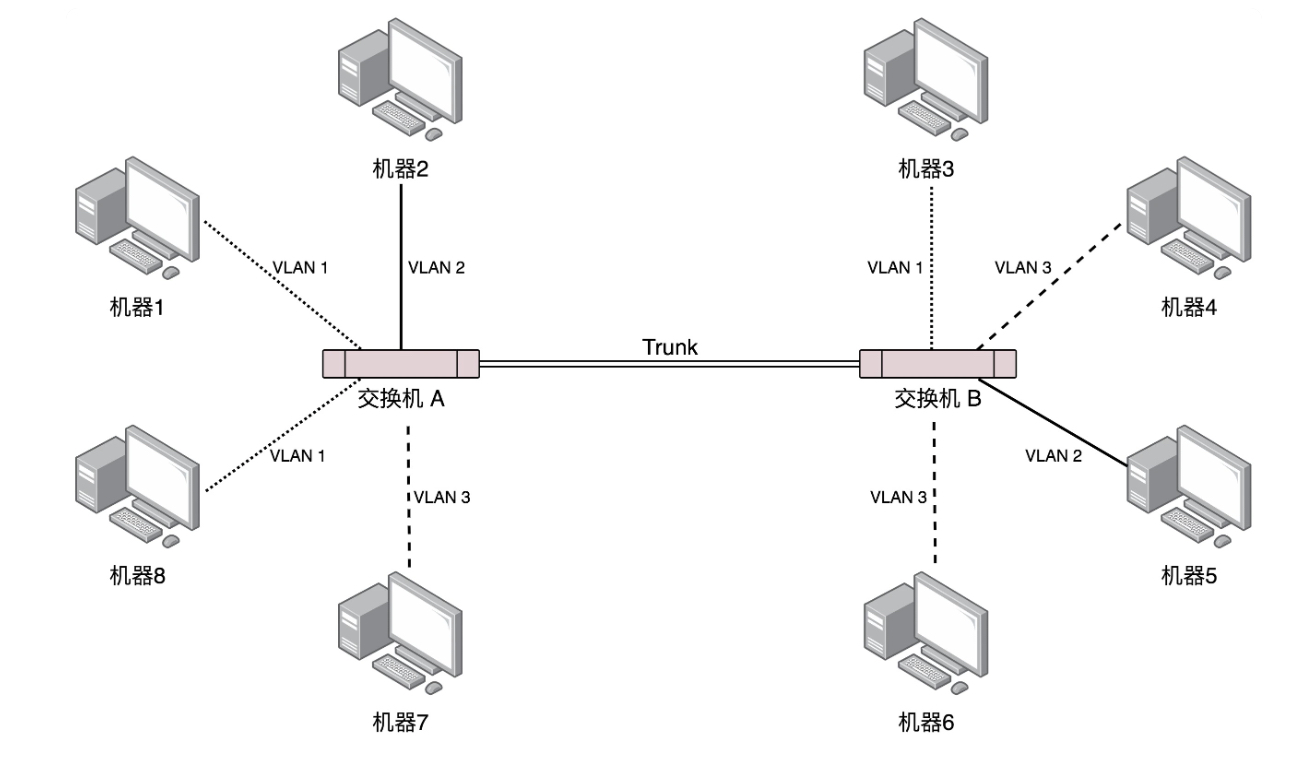
机器1、机器8、机器3同属于同个VLAN 1,所以它们之间的广播报文不会影响到其他主机。那么如何去配置机器属于哪个VLAN呢?我们可以设置每个交换机口所属的VLAN,这样连接到该端口的机器就属于该VLAN,在不同交换机上做相同的配置即可。
另外一个问题是,两台不同的交换机各自连接着许多机器,这些机器之间又被划分到了相同的VLAN,两台交换机之间如何交换VLAN数据呢?一个方法是各自预留VLAN端口用于两者之间的互联。图如下,处于蓝色圈内的机器同处于一个VLAN,所以他们都经过蓝色的VLAN 端口通信,红色圈内的机器同样如此这种做法显而易见的缺陷是这种做法存在很大程度上的端口浪费,因为每个VLAN都需要独占一个端口。
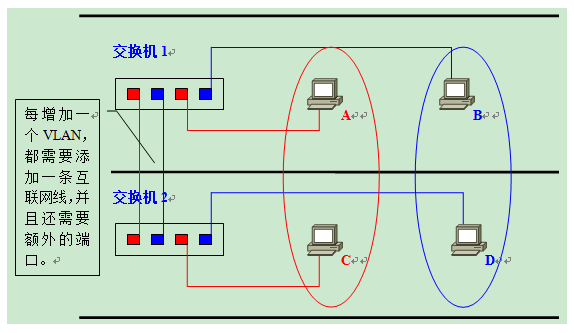
另外一个做法是两个交换机之间用专用的端口转发他们之间的VLAN数据,这条路线称为trunk。那么交换机如何区分走在trunk上的广播报文(单播是很容易确定发往哪个主机的,所以这里强调的是广播)是发往哪个VLAN?就像身份证一样,可以给每个VLAN都配个ID,带有vlan报文的以太网帧报头如下所示,在中间插入了四个字节的VLAN信息。VLAN是定义在 IEEE 802.1Q 标准的,VLAN header也就是下图的 802.1Q header。

对于 VLAN header的描述可以参考wiki,VLAN ID 是 12 bit,所以在一个LAN下最多只能划分2^12(4096)个VLAN。
VXLAN
VXLAN比较复杂,我也不是专业的网工,对于这部分内容浅尝辄止。VXLAN是一种被广泛采用的overlay network,RFC 文档的定义是:
A framework for overlaying virtualized layer 2 networks over layer 3 networks.
基于三层协议对二层协议虚拟化的协议。二层指的是以太网帧,三层指的是 UDP。一种新事物的产生总是需要解决现有的问题,在没有VXLAN之前实现大型数据中心实现多租户隔离使用的就是VLAN,VLAN存在哪些缺陷呢?下面的几点参考自RFC文档
- VLAN ID 至多为 4096,在虚拟化时代(无论是虚拟机还是现在的容器)在大型数据中心已经完全的不够用了。
- 数据中心要实现多租户,就要实现它们之间的网络隔离。在共享的网络设施上(这里应该是指实际的物理设备)实现网络隔离是成本很高的,并且多租户之间MAC地址以及VLAN ID的唯一性保证也存在潜在问题。
- 虚拟户的环境通常十分灵活,随时的扩容迁移传统的网络模型不适用。
VXLAN的出现就是为了解决上述原因的。我们先从协议层面理解VXLAN与VLAN的区别:
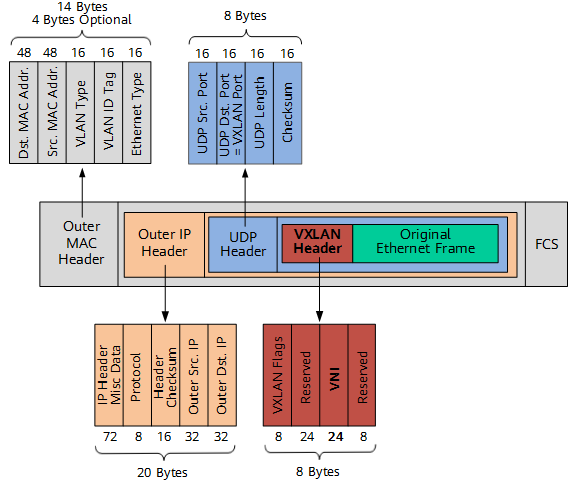
前面已经说过,VXLAN是构建在三层网络之上的用于实现二层虚拟化的协议。协议的结构也很直观的表明了这一点,原始的以太网帧被内嵌在了报文的最内部(绿色部分)。VNI的作用与VLAN ID类似,用来标识VXLAN网络的,用于网络隔离。不过它长度为 24 bit,所以最多支持 2 ^ 24个 VNI,基本用不完。传统的网络设备 MTU 都是1500,VXLAN报文在原始的以太网帧上额外增加了50字节,所以MTU数量要进一步减少,通常支持VXLAN的网络设备MTU要设置为 1450。flannel就会将MTU设置为这个值,如下:
shell$ ip link
3: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/ether 16:66:8e:e9:20:e5 brd ff:ff:ff:ff:ff:ff
Flannel的基本原理
Flannel 是较早出现的一个CNI,分别有三种模式用于实现容器环境下的虚拟网络分别是:UDP、VXLAN、host-gw,目前除了一些不支持VXLAN的老内核(VXLAN 在linux 3.7版本被合并),Flannel采用的默认模式都是VXLAN模式,接下来对于Pod通信的原理分析都是基于VXLAN,因为UDP模式的性能很差基本已经弃用,最后也附带介绍下Flannel的其他两种模式。
同节点内Pod通信
Flannel实现的同节点内Pod通信的过程比较简单,完全等同于同节点上两个docker容器的通信,主要就是依赖于一个网桥cni0进行数据的转发。
注意,同节点内Pod通信是不需要经过网关转发的,因为Pod同属于同一个子网,流量直接到达了Pod内的网络设备,以Flannel为CNI的Pod基本的网络设备类似于:
shell$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default
link/ether d6:33:62:f4:13:43 brd ff:ff:ff:ff:ff:ff link-netnsid 0
eth0是一个veth pair,它的作用类似于一根水管将Pod内部网络与外部网络通信(veth pair作用是在两个不同的namespace之间通信)。2: eth0@if5意思是eth0设备在Pod内的设备索引号是2,它的另一端(位于宿主机)索引号为5。前面我们说过 VXLAN 的MTU只能为 1450,所以容器内的MTU也只能为1450字节,不过实际的数据被封装为VXLAN报文是在宿主机上做的。
再来查看宿主机的网络设备:
shell$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:48:78:4d:9c brd ff:ff:ff:ff:ff:ff
3: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/ether 16:66:8e:e9:20:e5 brd ff:ff:ff:ff:ff:ff
4: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether fa:20:bd:e7:68:c7 brd ff:ff:ff:ff:ff:ff
5: veth95fd7679@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default
link/ether ee:7d:7c:79:50:7b brd ff:ff:ff:ff:ff:ff link-netnsid 1
6: vethd33f7325@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default
link/ether 92:d4:65:e5:24:ca brd ff:ff:ff:ff:ff:ff link-netnsid 2
5: veth95fd7679@if2:标识设备索引号为5的设备它的对端索引号为2,这与先前的描述恰好相符。为了同节点内Pod可以通信,还引入了一个Bridge-cni0,它的作用在这会等同于二层交换机,它的作用是将位于root namespace的veth绑定,查看cni0所绑定的设备:
shell$ brctl show
bridge name bridge id STP enabled interfaces
cni0 8000.fa20bde768c7 no veth95fd7679
vethd33f7325
当同节点Pod间需要网络通信,bridge是如何维护mac地址与设备名称的关系呢?与交换机相类似,bridge也有一个转发表,查看该表内容:
shell$ brctl showmacs cni0
port no mac addr is local? ageing timer
2 06:b3:a3:8e:bf:a1 yes 0.00
2 06:b3:a3:8e:bf:a1 yes 0.00
1 16:77:cf:fb:21:0f yes 0.00
1 16:77:cf:fb:21:0f yes 0.00
3 32:7d:d1:55:62:88 yes 0.00
3 32:7d:d1:55:62:88 yes 0.00
3 62:cd:2b:73:df:b5 no 1.84
2 6e:ac:dd:2c:9c:07 no 1.84
1 da:04:2a:80:d9:5a no 1.90
这个表的内容是自学习的,任何经过 bridge 的报文都会在表内留下痕迹,第一行内容表示mac地址为06:b3:a3:8e:bf:a1 报文从port 2出入。那么这些 port又代表着什么呢?使用命令brctl showstp cni0查看cni0上port的信息,port所关联的就是各个绑定到 bridge的veth设备。
shell$ brctl showstp cni0
# 省略了一些内容
vethbe21ca9f (3)
port id 8003 state forwarding
designated root 8000.b2bff13312cf path cost 2
designated bridge 8000.b2bff13312cf message age timer 0.00
designated port 8003 forward delay timer 0.00
designated cost 0 hold timer 0.00
flags
hairpin mode 1
当 Pod 第一次访问另外一个 Pod 时,由于不知道对方的 Mac 地址于是发送了 ARP 广播。 cni0 收到这条广播以后在转发表内增加了相关记录:
shellport no mac addr is local? ageing timer 2 6e:ac:dd:2c:9c:07 no 1.84
表示6e:ac:dd:2c:9c:07 no 表示这个mac地址不是位于 root namespace(因为 is local的值为 no),进入到cni0的端口是 port 2,也就是从 veth 的一端到达了另一端(从容器内到达了 root namespace)。ARP 广播转发到与 cni0 所绑定的所有端口,这等同于所有的 veth 设备都会收到 ARP 广播,除了源 veth。对方 Pod 响应了 ARP 应答,同样的也会在 cni0 的转发表内留下痕迹,这个过程与交换机转发 ARP 报文是完全一致的。
最后,对上述过程总结一下,基本原理如下图:
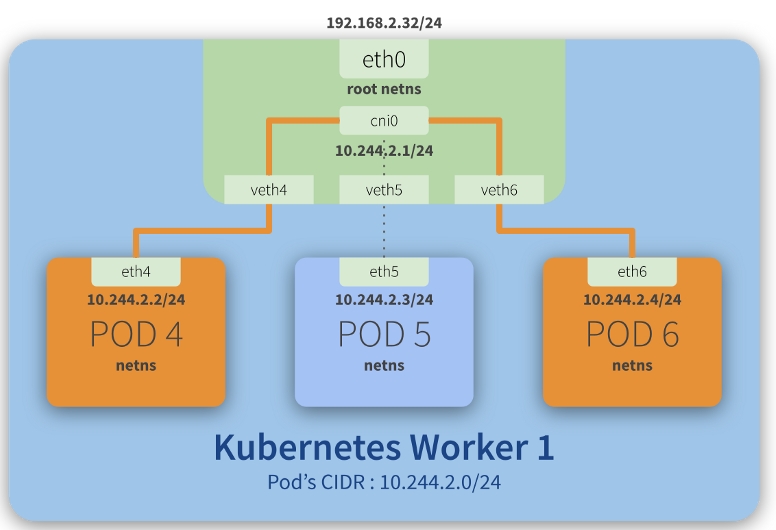
不同节点内Pod通信
接下来的实验验证的是: 从 10.244.1.2 -> 10.244.0.5 的网络数据走向。从网络地址可以观察到,Flannel将同节点Pod都是放在同一个子网内的,不同节点的Pod将位于不同的子网,这也就暗示着流量的转发需要经过网关。要知道网络数据的流向,不外乎从网卡设备、路由信息等方面入手。先来看下Pod内的路由信息:
shell$ route -n
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.244.1.1 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 10.244.1.1 255.255.0.0 UG 0 0 0 eth0
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
网关地址为10.244.1.1,它是宿主机上的cni0设备。所以访问其他节点的Pod流量首先也会到达cni0设备。注意,cni0是被配备了IP地址,此时它的角色是三层交换机。流量从Pod内经过路由转发到宿主机后,宿主机要根据路由表决定下一条去哪,宿主机路由如下:
shell$ route -n
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.49.1 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.49.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
表明去往10.244.0.0/24的流量将会发往10.244.0.0(网关),出去的设备是flannel.1。不过当前主机上没有任何一个网络设备的ip地址是10.244.0.0 ,所以要查看arp记录才知道10.244.0.0是哪个设备:
shell$ arp -a -n
? (192.168.49.1) at 02:42:0c:fd:74:57 [ether] on eth0
? (192.168.49.2) at 02:42:c0:a8:31:02 [ether] on eth0
? (10.244.1.2) at d6:33:62:f4:13:43 [ether] on cni0
? (10.244.0.0) at 96:8a:66:ad:2c:80 [ether] PERM on flannel.1
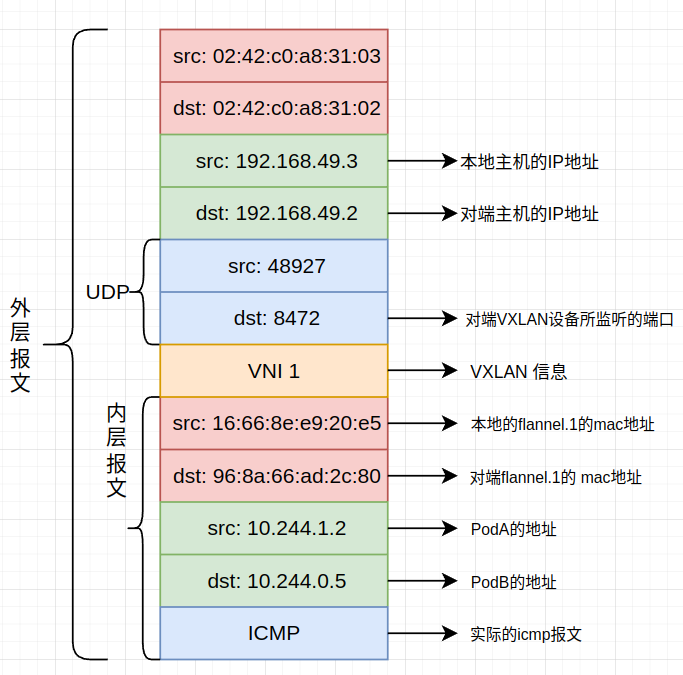
第四条记录知道了目的的mac地址是96:8a:66:ad:2c:80,该mac地址是对方主机的flannel.1的mac地址。到这儿为止,已经包装好了VXLAN的报文。注意,flannel.1是一个虚拟设备(flannel.1就是Vxlan术语中的vtep设备,负责对Vxlan报文的封装),所以它的mac地址不能直接用于目的地址,所以如何把VXLAN报文发送给对方设备还是个问题,这里又涉及到fdb表,表内以记录了96:8a:66:ad:2c:80应该往那台物理设备转发的记录:
shell$ bridge fdb show dev flannel.1
96:8a:66:ad:2c:80 dst 192.168.49.2 self permanent
这下就知道了往192.168.49.2转发即可,这个IP所绑定的是对方物理主机的eth0设备。到这儿为止,用一张图该概括一下整个VXLAN报文的结构,这个报文都可以从wireshark抓包得到:
这条报文到达对方宿主机以后,又是怎么样最终被容器所接受的呢? 要观察这个流程,只要在所有设备上抓取udp(VXLAN报文是以udp为载体的)和icmp(VXLAN报文被拆解为ICMP),如下:
shell# 进入minikube-m02上的一个pod,往minikube节点发送一条icmp报文
$ ping -c 1 10.244.0.5
# 在 minikube 节点上抓包,tcpdump -e 选项表示输出报文的 mac地址
$ sudo tcpdump -ne -i any 'icmp or udp'
12:55:03.155233 In 02:42:c0:a8:31:03 ethertype IPv4 (0x0800), length 150: 192.168.49.3.48927 > 192.168.49.2.8472: OTV, flags [I] (0x08), overlay 0, instance 1
16:66:8e:e9:20:e5 > 96:8a:66:ad:2c:80, ethertype IPv4 (0x0800), length 98: 10.244.1.2 > 10.244.0.5: ICMP echo request, id 6220, seq 1, length 64
12:55:03.155233 In 16:66:8e:e9:20:e5 ethertype IPv4 (0x0800), length 100: 10.244.1.2 > 10.244.0.5: ICMP echo request, id 6220, seq 1, length 64
12:55:03.155251 Out 12:b6:15:39:8a:6c ethertype IPv4 (0x0800), length 100: 10.244.1.2 > 10.244.0.5: ICMP echo request, id 6220, seq 1, length 64
12:55:03.155252 Out 12:b6:15:39:8a:6c ethertype IPv4 (0x0800), length 100: 10.244.1.2 > 10.244.0.5: ICMP echo request, id 6220, seq 1, length 64
从结果来看,报文的流转顺序为:
- 02:42:c0:a8:31:03: 表明到宿主机的物理网卡
- 16:66:8e:e9:20 > 96:8a:66:ad:2c:80: 这两个地址分别是 minikube-m02 的 flannel.1设备的mac地址以及 minikube的flannel.1设备的mac地址,这表明这会报文已经从宿主机的物理网卡传递到了flannel.1设备。参考了一些其他人的文章,内核会根据VNI将VXLAN报文转发到目标VXLAN设备。
- 12:b6:15:39:8a:6c: 这个是minikube节点的cni0 mac地址,说明数据从flannel.1转发到cni0网桥。flannel.1是如何将转发到cni0设备呢?答案是根据路由表。
最后一步在veth设备上抓包,输出了 src mac和 dst mac,不太清楚先前的抓包 为什么没有输出类似的内容。下面的内容表明流量从cni0到达了veth pair 进而进入到了容器。
shellsudo tcpdump -ne -i veth3aa88433 'udp or icmp' 04:54:38.217362 12:b6:15:39:8a:6c > 0e:47:dd:8f:76:b2, ethertype IPv4 (0x0800), length 98: 10.244.1.2 > 10.244.0.5: ICMP echo request, id 8153, seq 1, length 64
Note: 在新版本的tcpdump可以使用-v输出网卡的信息,serverfault一个答案是说tcpdump 4.99开始的,不过在容器内直接apt安装的tcpdump是4.9的,暂时不支持这个功能。
上边的mac地址分别代表的是: 宿主机 cni0和位于宿主机veth pair设备的mac地址,因此流量的走向已经十分明显了,将报文从cni0转发到veth设备,最终到达了容器内部。最后,再以一张图总结下Flannel的基本过程:
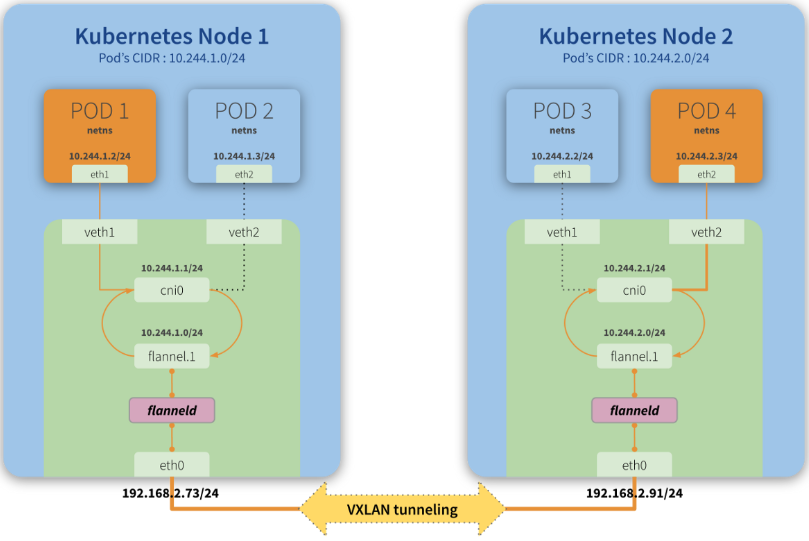
Note:
问题一: 回想一个问题,宿主机是如何知道对端的flannel.1设备是位于那台物理设备的呢?主要有两个方法,第一个是通过 flood学习,第二个就是引入全局的控制中心,flannel就是这样做的。相关内容可以参考: http://just4coding.com/2017/05/21/vxlan/ 和 https://icloudnative.io/posts/vxlan-protocol-introduction/
问题二: 使用 docker ps 可以看到flannel是容器的形式运行的,那为啥flannel.1设备以及fdb记录会出现在宿主机上? 这是因为flannel是与宿主机共享network namespace的,详情参考flannel的yaml配置文件(其中关键是设置了 hostnetwork: true)。
UDP 模式
UDP模式最早的目的应该是适配那些不支持VXLAN的老内核,在内核正式支持VXLAN以后UDP模式基本上已经没啥需要了。总体来说,UDP模式只是将容器间的报文交互装到了一份宿主机之间通信的UDP报文内。与VXLAN模式由内核支持相比,UDP模式是在于用户态实现的,所以不可避免又用户态与内核态之间的切换带来的性能开销,因此基本已经被弃用。
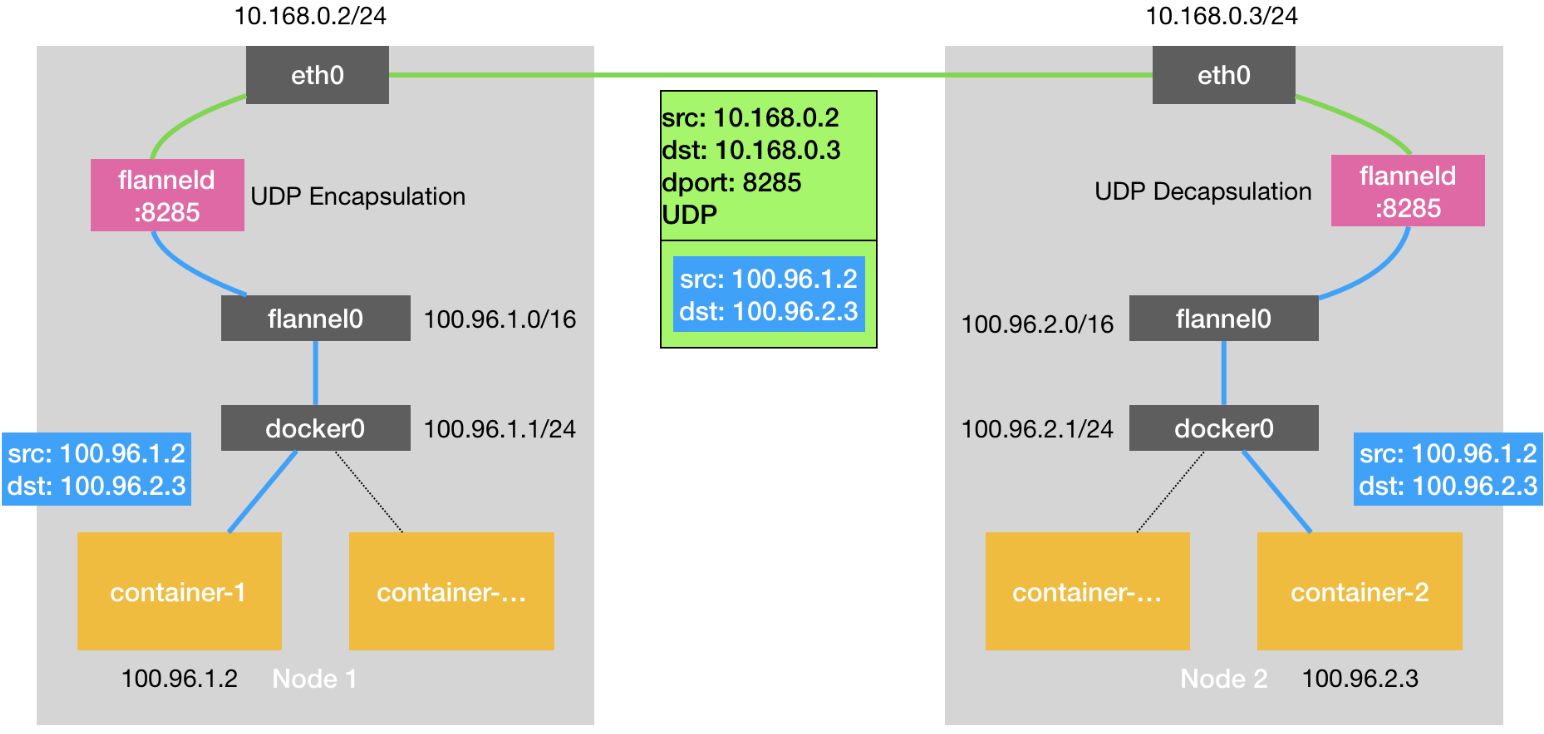
UDP模式的核心是一个flannel0设备,它是Linux下的TUN/TAP设备,目的是代理IP层的流量。Pod的默认网关是宿主机的一个bridge(也是一个三层交换机),所以流量会被转发到宿主机,宿主机的路由内配置了路由记录,Pod间的都将会被转发到flannel0设备,而Flannel的守护进程flanneld会完成这些被转发到flannel0报文的打包,包装为实际在物理机之间流通的报文。
那Flannel如何知道目标pod到底是位于哪个物理机呢?前面我们说过同节点的Pod将会位于同一个子网,Flannel会在ETCD维护着(子网,物理机地址)这样的映射关系。下面是一个例子(未实验,从公司内网一篇文章复制的):
shell$ etcdctl get /coreos.com/network/subnets/100.96.2.0-24
{"PublicIP":"10.168.0.3"}
下面是UDP模式的一个示例图,来自 https://blog.yingchi.io/posts/2020/8/k8s-flannel.html
host-gw 模式
host-gw指代host-gateway,顾名思义将宿主机直接作为网关,例子如下图:
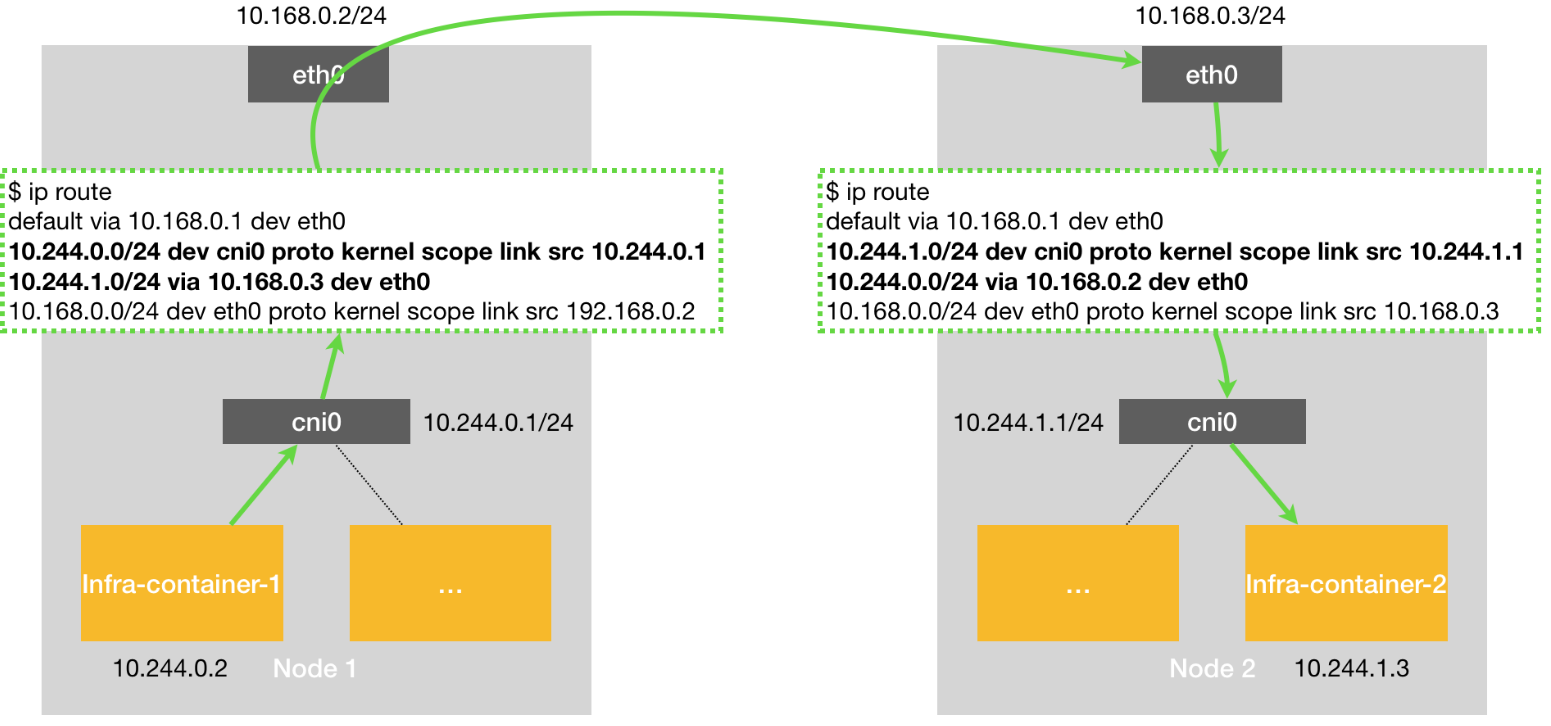
右侧的pod所处的子网是10.244.1.0/24,所以在左侧的Node1的路由表中直接配置了10.244.1.0/24 via 10.168.0.3 dev eth0这条路由记录,意思是10.244.1.0/24的报文都直接转发到10.168.0.3这台主机也就是Node2,Node2收到这种报文以后,依据自己的路由表记录10.244.1.0/24 dev cni0将Pod间通信的报文进一步转发到cni0,cni0又根据fdb转发到最终的pod。
另外,如果两个 pod 所在节点在同一个网段中 ,可以让 VxLAN 也支持 host-gw 的功能, 即直接通过物理网卡的网关路由转发,而不用隧道 flannel 叠加,从而提高了 VxLAN 的性能,这种 flannel 的功能叫 directrouting。
host-gw的性能相当的好,缺点是两台主机之间需要处于同一个子网(不经过额外路由器)。这是因为如果不处于同一个子网,中间都转发需要经过路由器,路由器对于k8s的虚拟网络是无感知的,所以对于pod间的流量它不知道如何转发,自然也就无法到达目的主机。
问题记录
问题一: docker ps 看不到k8s容器
在非 minikube 的 k8s 集群中,使用docker ps看不到 k8s 容器,这是因为在k8s 1.24以后docker不再是默认的容器运行时,转而使用crictl命令,具体的参考这个issue:https://github.com/kubernetes/kubeadm/issues/2695
遇到这个问题的原因是我想知道 pod 所属的namespace是哪个,思路是先用docker inspect获取容器pid,再去/proc/$PID/ns目录获取namespace的信息。
参考资料
https://www.redhat.com/sysadmin/kubernetes-pods-communicate-nodes 基本介绍了flannel跨节点通信的流程
https://draveness.me/whys-the-design-overlay-network/
https://zhuanlan.zhihu.com/p/35616289 很详细的介绍了VLAN
https://cizixs.com/2017/09/25/vxlan-protocol-introduction/ 详细的介绍了VXLAN
https://support.huawei.com/enterprise/zh/doc/EDOC1100087027 华为的VXLAN文档
https://en.wikipedia.org/wiki/6in4 IPv6 over IPv4
https://mvallim.github.io/kubernetes-under-the-hood/documentation/kube-flannel.html
https://blog.yingchi.io/posts/2020/8/k8s-flannel.html 介绍flannel的文章
https://github.com/flannel-io/flannel/blob/master/Documentation/backends.md flannel backend的介绍文档
http://just4coding.com/2020/04/20/vxlan-fdb/ fdb和 vxlan的实验模拟
本文作者:strickland
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!