目录
linux namespace 与 cgroup 是容器技术的基石。本篇的内容是探究docker网络的基本实现,即 linux network namespace 与 veth 的作用,基于探究与学习容器与容器之间通信,容器与外部网络通信,宿主机与容器通信。接下来首先对network namespace 与 veth 做基本介绍,然后模拟docker的网络通信模式。
基本知识
对于docker的初体验是奇怪于它是如何做到每一个容器都有自己IP和独立端口的,事实上这一切魔法就是来源于 linux network namespace。linux networkspace作用是为进程提供资源的隔离,每一个进程都可以认为系统资源是自己的独享的。于是,一台机器暴露有多个80端口对外提供服务也成为了可能。namespace 只是提供了资源隔离,每个容器都有自己的 IP 这还要归功于 linux 的虚拟设备-veth。除了veth 以外 ,linux还有 bridge,tun/tap等。
实操
veth pair
veth pair 的作用是连通两个 namespace, 让它们之间可以相互通信。使用命令ip netns add <namespace name>创建namespace,然后再这俩namespace之间互相ping对方验证效果。首先创建两个namespace,并且查看所属的网络设备:
shell$ ip netns add ns1
$ ip netns add ns2
$ sudo ip netns exec ns1 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
可以看到ns1下目前只有一个设备lo并且状态为down,我们可以将他启动并且ping 127.0.0.1 验证效果:
shell$ ip netns exec ns1 ip link set dev lo up
$ sudo ip netns exec ns1 ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
$ sudo ip netns exec ns1 ping -c 1 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.046 ms
ip addr显示状态为UNKOWN这就已经表示该设备被启动, <LOOPBACK,UP,LOWER_UP>内的UP就正确的表示设备被启动,于是ping 127.0.0.1就成功了。接下来我们要做的是创建一对 veth pair 让两个namespace之间可以相互访问。
shell$ ip link add veth1 type veth peer name veth2 # 创建一对 veth pair <veth1,veth2>
$ ip link set veth1 netns ns1 # 将 veth1 设备加入到ns1
$ ip link set veth1 netns ns2 # 将 veth2 设备加入到ns2
$ ip netns exec ns1 ip link # 查看这两个namespace下的设备
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth1@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 82:e8:f0:8e:4f:b9 brd ff:ff:ff:ff:ff:ff link-netns ns2
$ ip netns exec ns2 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: veth2@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 62:57:df:30:7c:ce brd ff:ff:ff:ff:ff:ff link-netns ns1
此时两个veth 设备的状态都还是DOWN, veth1@if3后面的if3指代的是veth的另一端在对方namespace的设备表里边所处的index,ns2的veth2前面哪个3恰好与这相对应,这个tip可以帮助我们后面在探究docker网络。接下来将这两个设备都分配IP地址并且启动,并且相互之间进行ping,结果如下:
shell$ ip netns exec ns1 ifconfig veth1 172.0.0.1 up
$ ip netns exec ns2 ifconfig veth2 172.0.0.2 up
$ ip netns exec ns1 ping 172.0.0.2
PING 172.0.0.2 (172.0.0.2) 56(84) bytes of data.
64 bytes from 172.0.0.2: icmp_seq=1 ttl=64 time=0.023 ms
64 bytes from 172.0.0.2: icmp_seq=2 ttl=64 time=0.027 m
不出意外的话,这两个ns任意一个都无法去外部网络,宿主机通信。那么为什么这两者可以相互通信呢?查看路由:
shell$ ip netns exec ns2 ip route
172.0.0.0/16 dev veth2 proto kernel scope link src 172.0.0.2
上边是一条直连路由,表示将172.0.x.x无脑转发到veth2,于是流量经过veth2到达了veth1。对于veth pair 的理解是将它们认为是一条导线只有连接着的双方可以相互通信。
最后为了防止对下一个实验造成影响,使用如下命令将ns删除:
shell$ ip netns delete ns1
$ ip netns delete ns2
Bridge
veth pair只能限定两个namespace之间通信,一旦namespace多了总不可能两两之间都创建一个veth pair。于是 网桥(bridge)就出现了,它是一个虚拟设备,在作用上如同物理交换机,能对二层以太网帧进行转发。为了让多个namespace之间相互通信,我们将**veth pair 的一端置于 namespace 内,另一端放到网桥上,**这样他们之间就可以互通了。
接下来的实验中,我们创建三个 ns 并且都绑定到网桥上,总体的拓扑图如下:
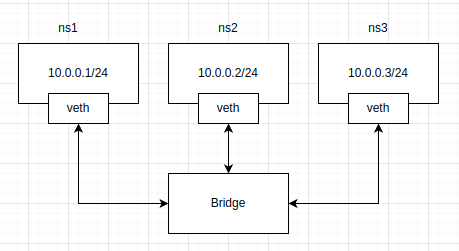
本小节的内容就是增加了一个bridge并且需要将veth pair 一端放到 bridge 上,命令如下每行命令的作用都写了注释。
shell# 创建network namespace
ip netns add ns1
ip netns add ns2
ip netns add ns3
# 创建 bridge
ip link add name br0 type bridge
# 创建三对 veth pair,一端位于 namepsace,一端位于bridge
for ns in ns1 ns2 ns3; do
# 创建 veth pair
ip link add $ns-inside type veth peer name $ns-outside
# 将veth的另一端放到brige上
ip link set dev $ns-outside master br0
# 并且启动
ip link set $ns-outside up
# 将veth的一端放入到 namespace
ip link set $ns-inside netns $ns
done
# 给veth pair中位于新建的 network namesapce的那一端分配 IP 地址
ip netns exec ns1 ip addr add 10.0.0.1/24 dev ns1-inside
ip netns exec ns2 ip addr add 10.0.0.2/24 dev ns2-inside
ip netns exec ns3 ip addr add 10.0.0.3/24 dev ns3-inside
# 然后启动
ip netns exec ns1 ip link set dev ns1-inside up
ip netns exec ns2 ip link set dev ns2-inside up
ip netns exec ns3 ip link set dev ns3-inside up
# 然后启动bridge
ip link set br0 up
验证实验效果,在ns之间相互ping:
shell$ ip netns exec ns1 ping 10.0.0.3
PING 10.0.0.3 (10.0.0.3) 56(84) bytes of data.
64 bytes from 10.0.0.3: icmp_seq=1 ttl=64 time=0.067 ms
$ ip netns exec ns2 ping 10.0.0.1
PING 10.0.0.1 (10.0.0.1) 56(84) bytes of data.
64 bytes from 10.0.0.1: icmp_seq=1 ttl=64 time=0.017 ms
查看bridge上的设备:
shell$ brctl show
bridge name bridge id STP enabled interfaces
br0 8000.f64c80ddee1d no ns1-outside
ns2-outside
ns3-outside
在宿主机上调用ip link,也可以看到outside 这几个网卡都被挂到了网桥上。示例信息如下:
shell5: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether f6:4c:80:dd:ee:1d brd ff:ff:ff:ff:ff:ff 6: ns1-outside@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP mode DEFAULT group default qlen 1000 link/ether d2:de:6c:2f:ca:a5 brd ff:ff:ff:ff:ff:ff link-netns ns1
查看 arp 表的内容也可以确认 IP 与 veth mac 地址之间的对应关系是正确的。
shell$ ip netns exec ns1 arp -a
? (10.0.0.3) at 8e:97:9d:0d:f3:7c [ether] on ns1-inside
? (10.0.0.2) at 56:25:1c:73:fe:a9 [ether] on ns1-inside
此时的bridge是一个二层设备(类似于交换机),所以数据的转发完全地依赖于 mac 地址。当一个ns第一次尝试ping另外一个ns时,它所发送的ARP广播会经过br0发送出去(bridge 会根据 fdb 表来转发到所有设备,使用命令bridge fdb show查看fdb的内容),目的ns返回的ARP reply也会由br0返回给发起方,这个过程和交换机转发过程是一样的。
Note:
注意,如果你在一台装有docker的机器上进行bridge的实验会发现这无法进行,这是因为docker对iptables的filter 表的 FORWARD chain 做了手脚,它将该chain的默认策略改为了DROP,而我们自定义的bridge又不能满足里边的各种规则而只能被DROP。所以推荐的方法是在虚拟机上实验,对宿主机的网络完全隔离。示例如下:
shellChain FORWARD (policy DROP) # 会导致我们默认的bridge无法生效 target prot opt source destination DOCKER-USER all -- anywhere anywhere DOCKER-ISOLATION-STAGE-1 all -- anywhere anywhere ACCEPT all -- anywhere anywhere ctstate RELATED,ESTABLISHED DOCKER all -- anywhere anywhere ACCEPT all -- anywhere anywhere ACCEPT all -- anywhere anywhere
容器与宿主机之间通信
进入到本小节以前可以开启使用docker进行实验,验证容器与宿主机之间能否相互通信,下面是我的实验结果:
shell$ ping -c 1 10.219.201.12 # 从容器到宿主机
PING 10.219.201.12 (10.219.201.12) 56(84) bytes of data.
64 bytes from 10.219.201.12: icmp_seq=1 ttl=64 time=0.129 ms
$ ping 172.17.0.3 # 从宿主机到容器
PING 172.17.0.3 (172.17.0.3) 56(84) bytes of data.
64 bytes from 172.17.0.3: icmp_seq=1 ttl=64 time=0.104 ms
接下来我们要模拟这个过程,用我们自己创建的网桥和容器(namespace),与上一小节有些许不一样的是: 我们现在要对网桥附上 IP 地址,总体的命令与上一小节一样,只是将10.0.0.1/24这个地址赋给了网桥,而ns的IP往后移动一位,拓扑图如下:
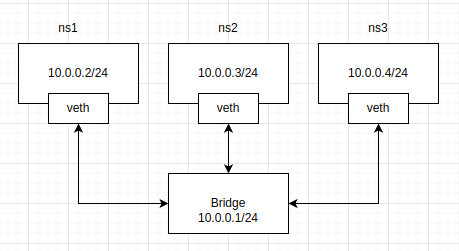
下面的命令是给bridge加上IP地址,其他命令与上一节保持一致。
shell# 给bridge加上IP以后就变成了一个三层设备,它将作为容器的网关
$ ip addr add 10.0.0.1/24 dev br0
$ ip link set br0 up
到这里似乎万事大吉了,就可以实验双方的通信,然而这暂时还是不行的,结果显示对方不可达,因为此时ns内还没有路由信息。查看ns的路由表:
shell$ sudo ip netns exec ns1 ping 10.0.2.15
ping: connect: Network is unreachable
$ ip netns exec ns1 ip route
10.0.0.0/24 dev ns1-inside proto kernel scope link src 10.0.0.2
意思是目的为10.0.0.x的流量都直接从ns1-inside网卡出去,然而我们的宿主机(10.0.2.15)并不是属于这个网段,因此流量跟不知道往哪里转发。所以我们要做的是将 bridge 作为默认网关让它把把流量往这里转发。
shell$ ip netns exec ns1 ip route add default via 10.0.0.1 dev ns1-inside
$ ip netns exec ns1 ip route
default via 10.0.0.1 dev ns1-inside
10.0.0.0/24 dev ns1-inside proto kernel scope link src 10.0.0.2 # 将网桥加入到ns的路由表中
给bridge设置ip以后,宿主机会自动追加一条路由记录,所以创建完了以后
shell$ ip route
default via 10.0.2.2 dev eth0 proto dhcp src 10.0.2.15 metric 100
10.0.0.0/24 dev br0 proto kernel scope link src 10.0.0.1 # 网桥路由
10.0.2.0/24 dev eth0 proto kernel scope link src 10.0.2.15 metric 100
10.0.2.2 dev eth0 proto dhcp scope link src 10.0.2.15 metric 100
10.0.2.3 dev eth0 proto dhcp scope link src 10.0.2.15 metric 100
好了,验证实验结果:
shell$ ip netns exec ns1 ping -c 1 10.0.2.15 # 容器到宿主机
PING 10.0.2.15 (10.0.2.15) 56(84) bytes of data.
64 bytes from 10.0.2.15: icmp_seq=1 ttl=64 time=0.072 m
$ ping -c 1 10.0.0.2 # 宿主机到容器
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=0.063 ms
成功了,如同我们所预期的那样。再结合抓包的结果来看下报文的走向:
shellsudo tcpdump -i any -vv -n -e 'icmp' 11:07:10.046609 ns1-outside P ifindex 11 d2:66:1a:8f:6c:a2 ethertype IPv4 (0x0800), length 104: (tos 0x0, ttl 64, id 4481, offset 0, flags [DF], proto ICMP (1), length 84) 10.0.0.2 > 10.0.2.15: ICMP echo request, id 49320, seq 1, length 64 11:07:10.046609 br0 In ifindex 10 d2:66:1a:8f:6c:a2 ethertype IPv4 (0x0800), length 104: (tos 0x0, ttl 64, id 4481, offset 0, flags [DF], proto ICMP (1), length 84) 10.0.0.2 > 10.0.2.15: ICMP echo request, id 49320, seq 1, length 64 11:07:10.046626 br0 Out ifindex 10 ca:86:ab:db:30:be ethertype IPv4 (0x0800), length 104: (tos 0x0, ttl 64, id 24214, offset 0, flags [none], proto ICMP (1), length 84) 10.0.2.15 > 10.0.0.2: ICMP echo reply, id 49320, seq 1, length 64 11:07:10.046628 ns1-outside Out ifindex 11 ca:86:ab:db:30:be ethertype IPv4 (0x0800), length 104: (tos 0x0, ttl 64, id 24214, offset 0, flags [none], proto ICMP (1), length 84) 10.0.2.15 > 10.0.0.2: ICMP echo reply, id 49320, seq 1, length 64
内容有些多,不过只要关注网络设备的名称,很明显是从ns1-outside走到了br0,到了br0会发现10.0.2.15就是本机的网卡,接着就进入到了icmp reply的处理,又根据路由表知道了目的为10.0.0.2报文应该转发到br0设备,再回到了ns1。
容器访问外部网络
最后模拟的就是容器对于外部网络的访问,经过上一小节的实验。可能会以为,此时应该已经能够访问外部网络,我们会猜想流量从容器到达了网桥,网桥转发到宿主机的网卡,然后被转发到了外部网络。动手试试:
shell$ ip netns exec ns1 ping www.baidu.com
# 阻塞,不会输出任何内容
那么是不是因为我们的数据包根本没有出去呢? 可以在 br0 上使用 tcpdump 抓包,输出内容如下:
shell$ sudo tcpdump -n -i br0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on br0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
06:38:05.338895 IP 10.0.0.2.50843 > 127.0.0.53.53: 53091+ [1au] A? www.baidu.com. (42)
06:38:05.338903 IP 10.0.0.2.50843 > 127.0.0.53.53: 42597+ [1au] AAAA? www.baidu.com. (42)
上面的内容表明容器正在进行DNS解析,不过DNS解析存在异常,A记录无法被解析,进而去转为AAAA记录还是无法解析。从实验结果来看,这说明容器的DNS请求已经发出去了,但是不能收到。问题的原因是此时 DNS 请求的源IP是容器IP,DNS 应答把容器IP作为了dst ip,到达主机以后不知道这个10.0.0.2到底是哪个网卡的IP,简单来说是因为我们没有进行NAT转换。
另外一个十分明确的例子是,我们可以预先解析得到百度的ip地址,然后再抓包,结果如下:
shell$ sudo tcpdump -i any -vv -n -e 'host 180.101.50.188'
11:29:46.582393 ns1-outside P ifindex 11 d2:66:1a:8f:6c:a2 ethertype IPv4 (0x0800), length 104: (tos 0x0, ttl 64, id 38796, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.0.2 > 180.101.50.188: ICMP echo request, id 55758, seq 1, length 64
11:29:46.582393 br0 In ifindex 10 d2:66:1a:8f:6c:a2 ethertype IPv4 (0x0800), length 104: (tos 0x0, ttl 64, id 38796, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.0.2 > 180.101.50.188: ICMP echo request, id 55758, seq 1, length 64
11:29:46.582400 eth0 Out ifindex 2 08:00:27:10:0b:45 ethertype IPv4 (0x0800), length 104: (tos 0x0, ttl 63, id 38796, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.0.2 > 180.101.50.188: ICMP echo request, id 55758, seq 1, length 64
到这儿,结果更加明确了,经过eth0设备出去的icmp报文的源IP地址是容器IP,所以icmp reply是永远回不来了。
目的已经明确,接下来要做的就是进行NAT转换,这里涉及到 iptables 的内容,这不是本篇的内容。在这个场景下,我们的宿主机扮演了路由器的角色,负责对IP包进行NAT,实现该目的需要开启ip转发的功能:
shell$ echo 1 > /proc/sys/net/ipv4/ip_forward
然后我们要分别作 SNAT 与 DNAT,出去的时候源IP被改为宿主机的网卡IP,返回的网络包目的IP被改为容器IP,接下来在 iptables 加入如下规则:
shell$ iptabls -t nat -A POSTROUTING -s 10.0.0.0/24 -j MASQUERADE # SNAT
$ iptables -t filter -A FORWARD -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT # DNAT
验证结果:
shell$ ip netns exec ns1 ping -c1 www.baidu.com
PING www.a.shifen.com (180.101.49.14) 56(84) bytes of data.
64 bytes from 180.101.49.14 (180.101.49.14): icmp_seq=1 ttl=47 time=12.8 ms
成功了!
些让人存在疑问的是,为什么DNAT的处理是在filter表当中而不是在NAT表? 如何去查看DNAT相关的记录呢?
问题一: 因为容器内请求到达外部网络的时候会被SNAT,所以本质上和宿主机的网络流量没有什么区别。当对方服务器返回的IP包内的目的地址 其实是宿主机的IP地址,因此内核处理报文时很明确的知道该报文是发送给宿主机的内的某个进程的,到这儿为止路由决策做完了(NAT表的工作已经完毕),接着要被filter表所处理。然后就是根据conntrack记录进行SNAT进而转发给容器,这也是规则中的-m conntrack的目的。
问题二: 如何查看SNAT记录? 可以使用conntrack程序。我在容器内部 curl www.baidu.com以后conntrack记录如下:
shell$ sudo conntrack -L -p tcp | grep 180.101.50.242
tcp src=172.17.0.2 dst=180.101.50.242 sport=44998 dport=80 src=180.101.50.242 dst=192.168.0.108 sport=80 dport=44998 [ASSURED] mark=0 use=2
tcp src=172.17.0.2 dst=180.101.50.242 sport=45002 dport=80 src=180.101.50.242 dst=192.168.0.108 sport=80 dport=45002 [ASSURED] mark=0 use=1
结果已经很明显了,容器172.17.0.2往百度的服务器180.101.50.242发送的IP报文被DNAT为了192.168.0.108。
Note: 为什么需要开启ip_forward?
每当linux收到一个数据帧时,总会执行以下步骤:
- 如果数据帧目标MAC地址不是收包网卡的MAC,也不是ff:ff:ff:ff:ff(ARP广播),且网卡未开启混杂模式,则拒绝收包;
- 如果数据帧目标MAC为ff:ff:ff:ff:ff,则进入arp请求处理流程;
- 如果数据帧目标MAC地址是收包网卡的MAC,且是IP包,则:
- 目标IP地址在本机,则上送到上一层协议继续处理;
- 目标IP地址不在本机,则看net.ipv4.ip_forward是否为1,如果为1,则查找目标IP的路由信息,进行转发;
- 目标IP地址不在本机,且net.ipv4.ip_forward为0,则丢弃
结合容器的例子来说,容器内报文尝试访问外部网络时,需要进过网桥转发到宿主机(MAC地址是bridge的地址,而IP包则是对方的公网IP),宿主机收到的以太网帧的目标mac是bridge的地址,但是目标IP为公网IP,这时宿主机充当了路由器的功能,这就需要开启ip_forward进行转发。
经过前面的内容,namespace里边的流量到达了br0以后,为什么可以经过宿主机上的eth0设备进而转发到外部网络呢? 这是因为当给bridge配备了IP地址值,它就变成了三层设备,流量到达了bridge以后还需要进行路由决策(查看宿主机上的路由表),接着就走默认路由从宿主机的物理网卡出去了。
参考: https://unix.stackexchange.com/questions/319979/why-assign-mac-and-ip-addresses-on-bridge-interface
开启 ip_forward以后,对宿主机上所有的网卡抓个包,就清楚了网络的走向:
shell# 随便起一个容器 ping -c 1 www.baidu.com
$ sudo tcpdump -i any -n -vv 'host www.baidu.com'
10:47:33.724013 veth23dd38d P IP (tos 0x0, ttl 64, id 49035, offset 0, flags [DF], proto ICMP (1), length 84)
172.17.0.2 > 180.101.50.242: ICMP echo request, id 2910, seq 1, length 64
10:47:33.724018 docker0 In IP (tos 0x0, ttl 64, id 49035, offset 0, flags [DF], proto ICMP (1), length 84)
172.17.0.2 > 180.101.50.242: ICMP echo request, id 2910, seq 1, length 64
10:47:33.724022 eno1 Out IP (tos 0x0, ttl 63, id 49035, offset 0, flags [DF], proto ICMP (1), length 84)
10.219.200.32 > 180.101.50.242: ICMP echo request, id 2910, seq 1, length 64
10:47:33.735449 eno1 In IP (tos 0x0, ttl 47, id 49035, offset 0, flags [DF], proto ICMP (1), length 84)
180.101.50.242 > 10.219.200.32: ICMP echo reply, id 2910, seq 1, length 64
10:47:33.735478 docker0 Out IP (tos 0x0, ttl 46, id 49035, offset 0, flags [DF], proto ICMP (1), length 84)
180.101.50.242 > 172.17.0.2: ICMP echo reply, id 2910, seq 1, length 64
10:47:33.735484 veth23dd38d Out IP (tos 0x0, ttl 46, id 49035, offset 0, flags [DF], proto ICMP (1), length 84)
180.101.50.242 > 172.17.0.2: ICMP echo reply, id 2910, seq 1, length 64
分别从veth23dd38d(位于宿主机的veth pair)-> docker0->eno1(实际的物理网卡),回包的过程就是一个相反的过程没啥好说的。
Docker 在做什么
前面所学的内容就是docker所做的事情。确实,从学习的角度来说先观察docker的现象在解释原理更加自然,不过这给我有一种开卷考试对着答案写答案的感觉。我们了解了上述的网络基本原理以后,docker的网络(只限于bridge模式)不再就没什么神奇的。我们运行一个docker 容器验证一下:
shell$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
265: eth0@if266: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
类似的主要通信都依赖于eth0,它的另一端位于宿主机上,宿主机的网络如下:
shell$ ip link
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:8b:0d:52:68 brd ff:ff:ff:ff:ff:ff
266: veth0861ac7@if265: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether de:ed:8f:99:81:0c brd ff:ff:ff:ff:ff:ff link-netnsid 3
docker 容器通信关键都是 docker0 这个 bridge,veth0861ac7也被放到了 docker0 上。查看容器的路由,可以看到bridge也被当做了默认网关:
shell$ ip route
default via 172.17.0.1 dev eth0 # 默认路由都转发给docker0
172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.3
至于docker插入的iptables 规则分别查看nat表和filter表就可以看到相关内容了,这里就略过。
为什么看不到 Docker 的 namespace
既然容器都是基于namespace的,那么为什么使用ip netns list看不到容器所创建的namespace呢?实际上,ip netns list做的事情就是读取/var/run/netns下的内容,而docker创建的镜像并不会在这个目录下创建内容。想要看到容器所处的namespace主要有两种方法:
- 手动的将容器进程下的
/ns/net目录使用symbolic link 连接到var/run/netns下 - 手动使用
nsenter命令进入到容器的所在的namespac,再执行ip netns list - 使用lsns命令,
sudo lsns -p <pid>查看某个进程的namespace信息。
这两种方法参考stackoverflow的这个答案。
结语
本篇主要介绍了docker的bridge模式是如何实现容器与容器间通信、容器与宿主机之间通信、容器与外部网络通信的。不过只局限与bridge模式的docker,初次意外docker还支持好几种网络模式,具体的查阅文档。在k8s的环境下,也容器也只用到了bridge模式(就以我的使用经验而言),k8s的网络就由 cni 接管了。想系统学习容器网络的初衷也是搞懂 k8s 的网络。
参考资料
https://cloud.tencent.com/developer/article/1869534 该作者的一系列文章还是不错的,从docker 网络介绍到k8s网络。
https://www.cnblogs.com/still-smile/p/14932131.html 从源码分析了bridge的基本工作原理
本文作者:strickland
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!