目录
进程(process)本质来说就是处于运行当中的程序,从内核角度来看进程是一组资源的集合(cpu、内存等)。当一个进程被创建时,父子进程拥有相同的代码段(text),但是他们拥有不同的堆栈。多线程在现代已经变得司空见惯,大部分的多线程应用都是用pthread库(POSIX thread)来实现的。
早期的Linux内核并不支持多线程程序,从内核的角度来说多线程程序和普通进程没有区别,因此线程的实现、调度都在用户态实现,即交给pthread 库。这种模式缺陷十分明显,一个线程因为系统调用陷入阻塞,会导致其他线程都阻塞。因此linux使用light weight process(LWP)来实现多线程,线程之间对于一些资源是共享的如内存空间、打开的文件等,线程之间对于资源修改是相互可见的,因此需要一些额外的同步手段。一个直接的实践方案就是将线程与LWP一对一关联起来,这既保证了资源的共享又保证了内核实现了对线程的调度,从而一个线程的睡眠(阻塞)其他线程仍然可以运行,Native POSIX Thread Library (NPTL)借助了LWP在Linux上实现了POSIX兼容的多线程库。为了能够管理进程,每个进程都有一个task_struct结构体。它包含了许多内容,如进程的优先级、状态、地址空间等,又被称为process descriptor。下图的右侧的六个数据结构示例了进程的一些资源。
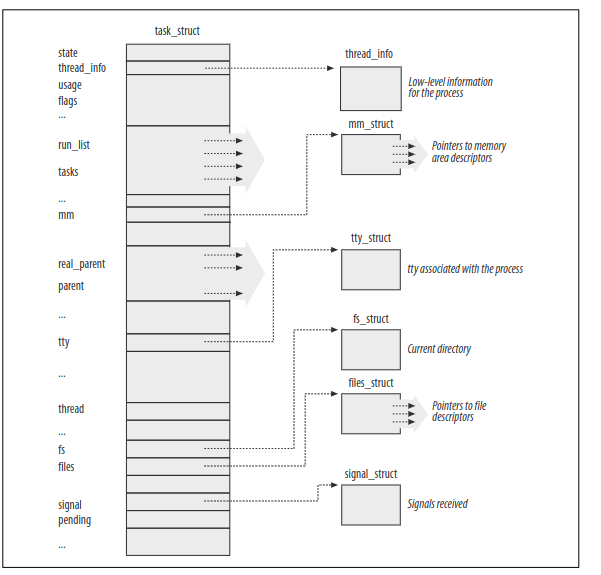 Note: Linux对于thread实现是采用LWP,所谓轻量化主要体现在thread之间对于资源的共享(如内存空间),而非进程级别的各种资源隔离。因此,内核的调度的角度来说thread和process没有太大的区别。虽然fork也让父子进程共享了一部分资源,但是因为COW(copy-on-write)的缘故,最终它们是独占了内存空间的。
Note: Linux对于thread实现是采用LWP,所谓轻量化主要体现在thread之间对于资源的共享(如内存空间),而非进程级别的各种资源隔离。因此,内核的调度的角度来说thread和process没有太大的区别。虽然fork也让父子进程共享了一部分资源,但是因为COW(copy-on-write)的缘故,最终它们是独占了内存空间的。
参考文档:
https://www.thegeekstuff.com/2013/11/linux-process-and-threads/ 描述LWP和thread的区别
进程的状态
task_struct内的state字段描述了进程此时的状态,划分为如下几种状态:
- TASK_RUNNING:进程正在运行或者是等待运行
- TASK_INTERRUPTIBLE: 进程被挂起(睡眠)直到某些条件被触发,可以是等待硬件中断、等待资源被释放、等待信号
- TASK_UNINTERRUPTIBLE: 和TASK_INTERRUPTIBLE差不多,区别是发送信号给处于该状态的进程无法改变它的状态。一般情况下,只有等待IO才会让进程处于该状态,在
ps中对应的就是进程处于D状态,参考man ps。 - TASK_STOPPED: 进程结束了,收到SIGSTOP, SIGTSTP, SIGTTIN, or SIGTTOU信号后进程会处于该状态。
- TASK_TRACED: Process execution has been stopped by a debugger.
还有两个状态会被同时设置在state和exit_state字段
- EXIT_ZOMBIE: 进程执行结束了,但是父进程没有调用wait系列函数来回收它的资源。
- EXIT_DEAD: 进程死亡,进程执行结束并且父进程调用了wait系列函数,内核可以回收它的资源了。
内核提供了set_task_state和set_current_state宏分别设置一个进程的状态以及正在运行的进程状态,这两个宏避免了指令重排带来的影响。
进程的ID
每个进程都有自己的task_struct,因此每个进程也会有自己的pid。默认情况下pid的最大值为32,767(64位内核不再是这个值),可以修改/proc/sys/kernel/pid_max来降低pid的限制,在64位内核中max_pid是4,194,303。当没有ID可用时,pid开始回卷,一个pidmap_array的位图维护着那些pid是可用的。
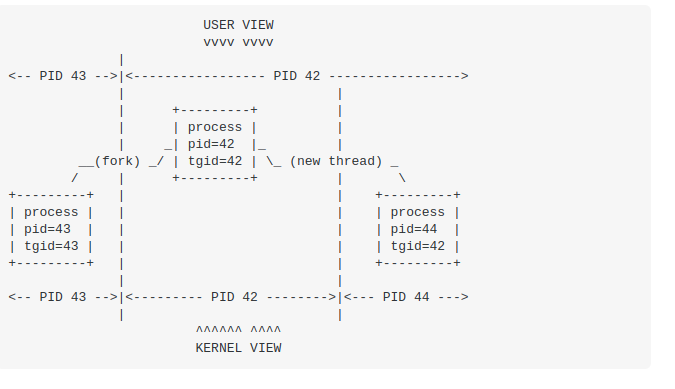
一个进程下的多个线程是共享pid的,多线程编程中getpid()将会返回相同的内容,因此对一个进程发送信号会影响到它里面所有的线程。为了实现这一点(即多线程需要共享pid),linux引入了thread group的概念,thread group的id就是第一个LWP的pid,它被存放在task_struct的tgid字段。下图展示了tgid和pid的关系,图来自:
 用户态程序调用
用户态程序调用getpid()返回的是tgid,所以多个线程就获得了相同的pid。
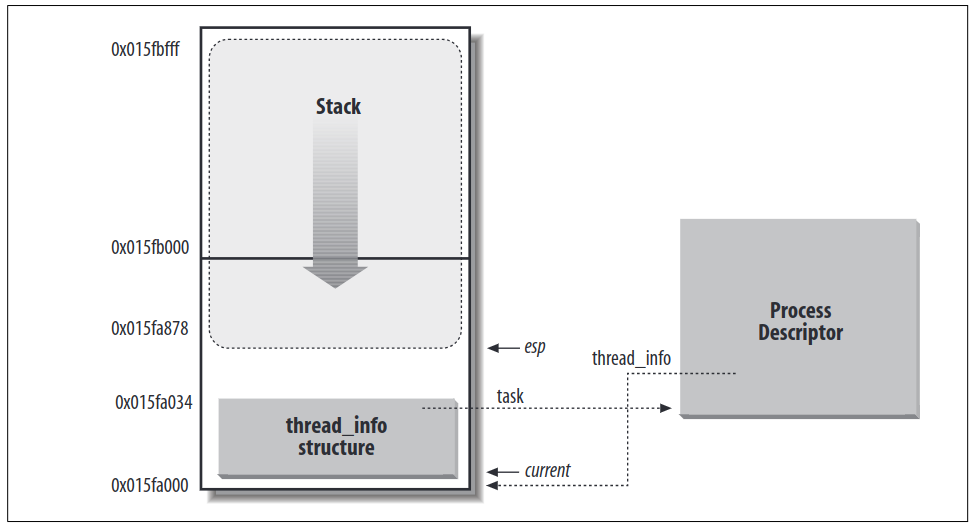
对于每一个进程,内核会将两块数据结构放在一块连续的内存中,这两块内分别是thread_info和内核栈。这块内存区域通常为8192字节(2 page frames)为了效率期间内核栈通常分配在两个连续的页并且地址为2^13对齐,不过因为空闲的页可能是分散的(因为伙伴系统的缘故),因此内核可以在编译期间指定内核栈为4096字节。内核采用了额外的栈地址来避免中断和异常嵌套导致的栈溢出。
下图是这块连续内存的结构:
 `thread_info`里面有一个`task_sturct`的指针,`task_struct`也有一个`thread_info`指针。内核使用下面的union来分配一块连续的内存,将thread_info和内核栈放在一起:
`thread_info`里面有一个`task_sturct`的指针,`task_struct`也有一个`thread_info`指针。内核使用下面的union来分配一块连续的内存,将thread_info和内核栈放在一起:
cunion thread_union {
struct thread_info thread_info;
unsigned long stack[2048]; /* 1024 for 4KB stacks */
};
如何高效的获取当前正在运行进程信息?内核在这儿有一个很巧妙的做法。
当从用户态切换到内核态的时候,esp指向的是内核栈的起始地址,只要将地位的13 bit 设置为0(8192字节的内核栈)就获得了这块连续内存的首地址,也就是thread_info的地址。
cmovl $0xffffe000,%ecx /* or 0xfffff000 for 4KB stacks */
andl %esp,%ecx
movl %ecx,p
再从thread_info中获取task字段,就得到了当前运行的进程。或者直接使用current这个宏来获得当前运行的进程。
Note: 从上面的描述来看,每个进程都有自己内核栈,而非多个进程共享一个内核栈。
进程间关系
一个进程可以创建多个子进程,task_struct里面有一些结构体维持了进程之间的关系:
- real_parent: 创建了当前进程的父进程的
task_struct指针,或者是1号进程的task_struct(Therefore, when a user starts a background process and exits the shell, the background process becomes the child of init.) - parent: 也是父进程,大部分情况下real_parent和parent相同
- children: 当前进程的子进程
- sibling: 当前进程的兄弟进程
进程是如何组织的
runqueue是所有处于TASK_RUNNING的进程列表(每个CPU都有自己的run queue),那么处于其他状态的进程是如何被组织的呢?
- 处于
TASK_STOPPED,EXIT_ZOMBIE,EXIT_DEAD状态的进程不需要放在专门的链表中,因为这些进程可以通过PID直接获取,或者是 via linked lists of the child processes for a particular parent(不太明白) - 处于
TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE被划分为多个类(class),每一种都对应一种事件。这种情况下,进程的状态(state字段)无法反映的足够信息,进程是睡觉还是等待中断而陷入的TASK_INTERRUPTIBLE?因此需要引入额外的list,这些list称为wait queue。
run queue wiki: https://en.wikipedia.org/wiki/Run_queue
vmstat命令可以查看系统runqueue的长度:
shell$ vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 1 411904 2474772 1199820 10911888 0 0 1 6 1 2 1 0 99 0 0
1 0 411904 2480336 1199824 10911892 0 0 0 134 1608 4793 1 0 99 0 0
r: The number of runnable processes (running or waiting for run time).
b: The number of processes blocked waiting for I/O to complete.
wait queues
wait queue有双向链表实现,链表内每个元素都指向一个进程描述符(process descriptors),每个wait queue由wait queue head来表示:
cstruct __wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;
wait queue需要被 interrupt handlers和内核代码并发使用,所以一些同步是必要的,因此内置了一个 spin lock。成员变量task_list是wait queue的head,wait queue的每个元素为结构如下:
cstruct __wait_queue {
unsigned int flags;
struct task_struct * task;
wait_queue_func_t func;
struct list_head task_list;
};
typedef struct __wait_queue wait_queue_t;
每个element都代表一个处于睡眠的进程(不是狭义上调用sleep的进程),它在等待某一事件的发生,成员变量task_list是**等待同样的事件的进程的链表。**但是,并不是事件就绪了就唤醒所有等待该事件的所有进程,比如说等待了一些独占的资源(锁)那么更加合适的做法是只唤醒其中的一个进程,这样做避免了thundering herd
his avoids a problem known as the “thundering herd,” with which multiple processes are wakened only to race for a resource that can be accessed by one of them, with the result that remaining processes must once more be put back to sleep.
因此等待睡眠的进程应该有两种类型,等待互斥资源的(锁)和等待非互斥资源的(等待硬盘数据的发送),wait queue的func成员变量决定了进程将如何被唤醒。两种类型的睡眠进程,也决定了它们将如何被插入到wait queue,分别有add_wait_queue_exclusive和remove_wait_queue函数。一个进程等待某种事件发生,可以调用以下的函数:
-
sleep_on()操作的对象是当前进程它将进程设置为
TASK_UNINTERRUPTIBLE,然后插入到wait queue,调用schedule()选择下一个进程。当进程被唤醒以后,将它从wait queue移除cvoid sleep_on(wait_queue_head_t *wq) { wait_queue_t wait; init_waitqueue_entry(&wait, current); current->state = TASK_UNINTERRUPTIBLE; add_wait_queue(wq,&wait); /* wq points to the wait queue head */ schedule(); remove_wait_queue(wq, &wait); } -
interruptible_sleep_on()和
sleep_on()类似,只不过它将进程设置为TASK_INTERRUPTIBLE状态,因此可以被信号唤醒 -
sleep_on_timeout()和前一个类似,内核定义了一个timer,timer过期后唤醒进程
下面琐碎的细节太多,不想看了。
进程资源的限制
内核对每个进程资源都进行限制,避免所有资源被一个进程消耗殆尽。每个进程的资源限制被存放在current->signal->rlim(新版本的内核似乎并不是如此),rlim是一个数组,里面的元素是struct rlimit 结构体:
cstruct rlimit {
unsigned long rlim_cur;
unsigned long rlim_max;
};
分别表示了资源的当前的limit以及该资源最大可以允许的limit。用户可以用getrlimit( ) 和 setrlimit( ) 调节limit,直到rlim_max,但是rlim_max只有root用户可以调整。参考: https://man7.org/linux/man-pages/man2/getrlimit.2.html
进程切换
进程切换需要保存当前进程的现场(各种寄存器的值,hardware context),然后加载新的进程的上下文。一部分的hardware context保存在内核内存中(存在process descriptor,也就是 struct task_struct),其他部分存在于内核栈中。进程切换是发生在内核态的,因此需要从用户栈切换到内核栈,那么如何CPU获取内核栈呢?
x86有一种特殊的segment成为 task state segment (TSS)目的适用于存放进程切换时寄存器,虽然Linux没有使用它来完成进程切换,只用了它两个方面的功能:
- 当cpu从用户态切换到内核态时,CPU 从 tss 中获取内核栈的地址
- 当用户态程序尝试使用IO命令(in 或者 out) 命令直接从IO port访问数据时,CPU需要从 TSS 内获取 I/O Permission Bitmap 来决定进程是否权限访问。
当进程执行IO命令时,control unit 会执行下面的操作:
- 确认 eflags 寄存器中的 IOPL 字段,只有IOPL 小于等于 CPU 此时的CPL的时候才可以执行IO指令。因此,如果IOPL设置为了3,那么所有进程都可以直接执行IO操作。
- 从tr寄存器获取当前的TSS
- 从IO Permission Bitmap 判断被IO指令所有的IO port是否为设置为1,如果没有,那么就可以执行IO命令。
TSS是每个CPU都有的,因此内核维护了一个 TSS 数组(Intel设计之初的目的是每个进程都有自己的TSS)。正因为 Linux 没有使用 TSS用于上下文切换,因此它将上下文内容都保存在内存中,即struct thread_struct,它里面保存了大部分 CPU 寄存器的值,除了一些通用性的寄存器eax、ebx等,这些寄存器被保存在内核栈当中。struct thread_struct位于include/asn-i386/process.h。
Note: Linux为每个CPU都维护了一个TSS,也就是每个CPU上所执行的进程在共享这个TSS,当进程切换的时候,TSS也需要切换到下一个进程的内核栈指针,Linux以这样动态调节TSS里的内核栈指针,让多个进程复用了TSS。
本质来说,进程切换就做两件事
- 切换进程的page directory
- 切换到内核栈,切换到下一个进程的上下文(各种寄存器)
switch_to macro:
switch_to是一个关键的宏,我们首先关注它的参数列表:
c// include/asm-i386/system.h
#define switch_to(prev,next,last) do { \
unsigned long esi,edi; \
asm volatile("pushfl\n\t" \
"pushl %%ebp\n\t" \
"movl %%esp,%0\n\t" /* save ESP */ \
"movl %5,%%esp\n\t" /* restore ESP */ \
"movl $1f,%1\n\t" /* save EIP */ \
"pushl %6\n\t" /* restore EIP */ \
"jmp __switch_to\n" \
"1:\t" \
"popl %%ebp\n\t" \
"popfl" \
:"=m" (prev->thread.esp),"=m" (prev->thread.eip), \
"=a" (last),"=S" (esi),"=D" (edi) \
:"m" (next->thread.esp),"m" (next->thread.eip), \
"2" (prev), "d" (next)); \
} while (0)
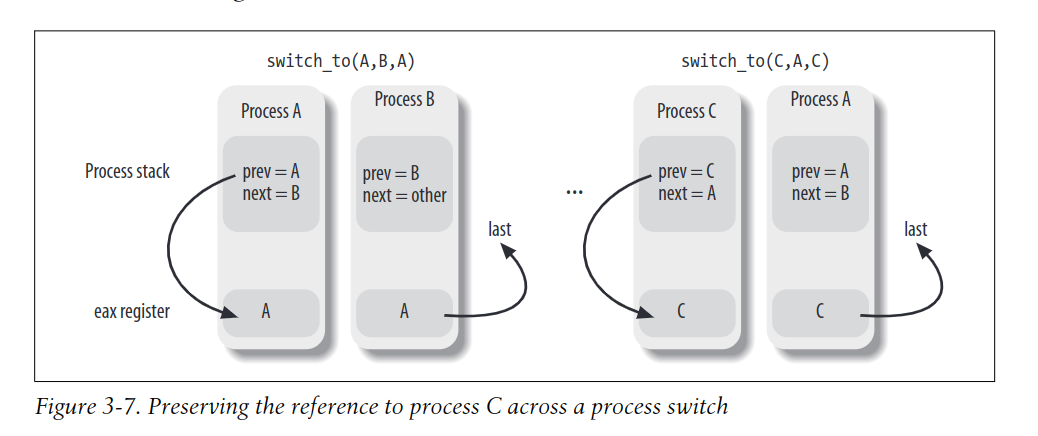
顾名思义,prev和next分别只想被切换的进程和将要轮到执行的进程,那么last是什么?
考虑一个场景,从进程A切换到进程B以后,经过许久有需要从进程C切换会A。当A进程在被切换时(B还没有执行,A仍然是CPU的持有者),此时switch_to的prev和next都位于进程A的内核栈,当从C回到A时,这个过程期间,A的内核栈都没有发生变化,因此prev=A,next=B。而我们所期望的是,prev=C,next=A,因此我们丢失了对C的reference。因此,我们额外引入了一个last来保存C。
下面逐行来解释这个情况,疑问:源码和书上的描述有些不符,可能是版本的关系
-
将prev和next保存到寄存器eax和edx。
cmovl prev, %eax movl next, %edx -
保存eflags寄存器到prev进程的内核栈。
cpushfl pushl %ebp书上对于编译器的描述不太明白
-
将此时栈指针保存到当前进程的thread->esp处,这就保存了当前进程内核栈的地址
movl %esp,484(%eax)前面将eax设置为了prev的地址,
484(%eax)表示eax寄存器的内容作为地址 + 484字节,就是thread->esp的地址 -
加载下一个进程的内核栈指针。接下来任何对栈的操作都是在下一个执行的进程的内核栈了! 因为内核栈指针和
current宏息息相关,所以改变了内核栈指针也就改变了当前运行的进程。cmovl 484(%edx), %esp -
将标号1点地址保存到
prev->thread.eip,当prev进程恢复执行的时候,它就会从标号1处开始执行,最后回到schedule()函数。cmovl $1f, 480(%eax) -
在next进程的内核栈中,压入 next->thread.eip,大部分情况下就是标号1的地址
cpushl 480(%edx) -
跳转到
__switch_to,后面会说cjmp __switch_to -
重新回到这儿的时候,A重新获得了CPU,所以开始恢复它之前的寄存器内容
c1: popl %ebp popfl -
从C切换到A的时候,eax寄存器里的是C,edx寄存器里的是A,A的内核栈里面prev是A,next是B,所以这会对last赋值,让A知道上一个被换出去的进程其实是C,而不是参数prev所指向的A。
cmovl %eax, last
整个过程如下图所示:
 进程切换还有很大一部分工作是在
进程切换还有很大一部分工作是在__switch_to函数。和普通的函数不同,这个函数使用的是寄存器传参,而不是和普通函数一眼使用栈。为了强制使用寄存器传参,内核代码使用_ _attribute_ _(regparm(3));,表示将3个参数写入到eax,edx,ecx寄存器,而不是栈上。因为在前面我们将prev和next分别存在了eax和edx寄存器,这里恰好也前面的动作相符。
c_ _switch_to(struct task_struct *prev_p,
struct task_struct *next_p)
_ _attribute_ _(regparm(3));
实际源码和这里的描述有点不一样,__switch_to是被包含在FASTCALL(x) x __attribute__((regparm(3)))的
-
保存prev进程的FPU、MMX、XMM这些寄存器的内容
c_ _unlazy_fpu(prev_p); -
加载下一个进程的内核栈指针到当前CPU的TSS
cinit_tss[cpu].esp0 = next_p->thread.esp0;前面我们说过Linux是多个进程复用一个TSS,动态的切换TSS中内核栈的指针。在后面将会学习到,通过sysenter命令从用户态切换到内核态的时候,CPU会从TSS中复制这个栈指针到esp寄存器。上面代码
cpu是smp_processor_id( )得到的当前CPU的Index。 -
加载下一个进程的TLS(thread local storage),Linux将GDT的6、7、8 存放TLS selector。
ccpu_gdt_table[cpu][6] = next_p->thread.tls_array[0]; cpu_gdt_table[cpu][7] = next_p->thread.tls_array[1]; cpu_gdt_table[cpu][8] = next_p->thread.tls_array[2]; -
将prev进程的gs和fs寄存器的值保存起来
cmovl %fs, 40(%esi) movl %gs, 44(%esi)这里 esi 寄存器的内容指向了
prev->thread。疑问:什么时候将prev->thread赋值给了esi寄存器? -
如果fs和gs寄存器已经被prev或者next进程使用(即他们不为0),把寄存器的值加载到next进程。不太明白作用
cmovl 40(%ebx),%fs movl 44(%ebx),%gs -
剩下几步不太重要,最后一步是结束了
__switch_to函数,将prev返回,也就是edi寄存器的内容返回。x86以eax寄存器作为返回值,所以将edi寄存器的内容写入到eax寄存器,最后一条ret指令返回:cmovl %edi,%eax ret将edi的值写入到eax寄存器,这是因为eax寄存器在x86当中是返回值所用的寄存器,这是相当重要的因为这保证了eax寄存器指向的都是被换出去的进程(这里说的应该是
switch_to调用__switch_to期间eax的寄存器的值保持不变)。ret指令从栈上获取将要执行的指令的地址,而此时内核栈已经是下一个进程的内核栈,对于一个新创建的进程来说,它将开始从ret_from_fork()函数开始执行,源码位于 arch/i386/kernel/entry.S:assemblyENTRY(ret_from_fork) pushl %eax call schedule_tail GET_THREAD_INFO(%ebp) popl %eax jmp syscall_exit疑问:为什么edi寄存器中会是prev?上文没有看到对edi寄存器赋值的地方
书上接下来还描述了很多在上下文切换中FPU的内容,这块不太熟悉也略。感觉对于上下文切换的描述比较粗略,其他的如通用寄存器的恢复之类的还不太明白。
进程的创建
传统的Unix系统在创建新进程的时候,父进程的资源会被完全复制一份到子进程,这是十分低效的做法。大部分情况下,子进程被创建后紧跟着调用exec系列函数,加载一个新的进程,将刚才从父进程中复制的内容丢弃了,因此传统进程实现做了很多无用功。后来的Unix内核引入了新的机制来解决这个问题:
- 使用了Copy On Write(COW),父进程和子进程共享页表,于是他们的虚拟空间映射到了相同的物理地址,当其中一个进程尝试去修改内存的内容,会触发PageFault内核将原内存的数据复制一份,避免了数据的污染(COW的具体细节留到了书的第九章讲解)。
- LWP(light weight process)允许父子进程共享相当多的资源,包括地址空间、打开的文件、信号处理。
- 使用vfork使得父子进程之间共享地址空间,为了避免父进程修改了那些子进程需要的数据,父进程调用vfork的时候会陷入阻塞。
创建LWP使用了clone()函数,它的参数列表是:
- fn:新进程将要执行的函数
- arg:新进程的参数
- flags:乱七八糟的flag,参考man clone,包括是否共享打开文件、是否共享地址空间之类的。
- child_stack: 子进程的栈地址(用户栈)
- tls:新进程的thread local storage
- ptid::在用户空间中子进程的父进程的pid
- ctid:在用户空间中子进程的pid
clone()是C标准库的一个封装函数,源码地址,它设置好LWP的栈然后调用clone()系统调用。sys_clone这个系统调用的参数列表并没有fn和arg参数,因为clone()已经将fn和arg放在了子进程栈上某个地址,该地址恰好是clone()函数的返回地址,arg紧跟其后。这里说的应该也是利用ret指令从栈上获取执行命令的机制来跳转到子进程。
When the wrapper function terminates, the CPU fetches the return address from the stack and executes the fn(arg) function
传统的fork()也是由clone()系统调用实现的并且设置了SIGCHILD标志清空了其他标志,然后子进程的栈是父进程的栈指针,所以父子进程共享了栈指针,不过感谢COW,父子进程最终使用的是不同的用户栈。在源码中fork()最终调用的是sys_fork(),看下它的源码:
casmlinkage int sys_fork(struct pt_regs regs)
{
// SIGCHLD 表示当子进程退出后给父进程发送的信号是 SIGCHLD, 详情参考 man clone
return do_fork(SIGCHLD, regs.esp, ®s, 0, NULL, NULL);
}
vfork()也是用了clone()系统调用,包含了SIGCHLD、CLONE_VM、CLONE_VFORK三个选项,并且子进程的栈和也父进程栈相同。所以使用vfork应该要十分小心,因为子进程的对于内存空间的操作父进程是可见的。
Therefore, vfork() must be used with caution to ensure that the child process does not modify the address space of the parent.
vfork() is intended to be used when the child process calls exec() or exit() immediately after creation.
do_fork()函数被clone(),fork(),vfork()所调用,下面是它的参数列表:
- clone_flags: 和
clone()的一样,各种flags - stack_start: 子进程的栈,和
clone()的一样 - regs: 保存到内核栈里的各种通用寄存器,当从用户态切换到内核态的时候,会在中断处理函数中保存所有的通用寄存器的内容
- stack_size: 没用,都是0,疑问:我们是stack_size为0?
- parent_tidptr,child_tidptr: 和clone中对于进程id的描述的一样
do_fork()先调用了一个copy_process()来从父进程中复制很多内容给子进程,do_fork()主要的过程是(我省略了很多ptrace相关的内容):
-
从
pidmap_array中找一个空闲的pid分配给子进程 -
调用
copy_process(),将父进程的各种东西都给子进程复制一份 -
如果标志
CLONE_STOPPED没有被设置,调用wake_up_new_task()-
调整父子进程的与调度相关的参数
-
如果子进程和父进程将会在同一个CPU运行,并且父子进程不共享地址空间,那么子进程将会插入到父进程所处的runqueue的前面(插队)。这是因为如果子进程执行后马上加载了一个新的程序(exec调用),那么频繁的COW会导致很多不必要的页内容的复制
Note: COW虽然避免了实际页内容的复制,但是它复制的是页表,所以COW是不共享地址空间的。而共享地址空间指的是完全共享页表,也就是在切换进程的时候不切换cr3寄存器的内容。
-
如果不在同一个CPU运行,或者是共享了页表,那么将子进程插入到父进程的所在的runqueue的末尾。
-
-
如果设置了
CLONE_VFORK,那么将父进程放到一个 wait queue 直到子进程退出或者是调用exec -
返回子进程的pid
关于fork的奇妙之处,fork的特点是在父进程放回子进程pid,在子进程返回0,是如何做到在不同的地址空间有不同的返回值呢? 原因是fork在子进程的调用中,最后返回的时候eax寄存器被认为的修改为了0。
接下来详细介绍copy_process()的工作,它负责设置好各种子进程运行所需的内容,主要有:
-
对flags做一些校验,比如说CLONE_NEWNS(将进程放入新的namespace)和CLONE_FS(父子进程共享文件系统信息,chroot,chdir这些调用会相互影响,参考man clone),其他的内容不详细介绍。
-
调用
security_task_create()进行一些额外的安全性检查 -
调用
dup_task_struct来复制一份当前进程(父进程)的task_struct,主要有:-
_ _unlazy_fpu()保存当前进程(父进程的)FPU、MMX、SSE/SSE2寄存器,然后dup_task_struct将会复制这些寄存器的内容给子进程。 -
alloc_task_struct()分配一个新的task_struct -
调用
alloc_thread_info()分配一块连续的区域,分别存放struct thread_info和子进程的内核栈,如同前面描述的那样。疑问:前面内核栈说的thread_union,为什么这里直接是thread_info表示内核栈?下面是内核代码:
cti = alloc_thread_info(tsk); if (!ti) { free_task_struct(tsk); return NULL; } *ti = *orig->thread_info; *tsk = *orig; tsk->thread_info = ti; ti->task = tsk;根据内核代码猜测,
alloc_thread_info()分配了8192字节的内存,并且将最开始一块分配给了struct thread_info,那么剩下的地方就直接作为内核栈了,而不是用thread_union申请的。 -
将父进程的
thread_info复制给子进程,子进程的thread_info里的task_struct指向自己。 -
将子进程的
usage字段设置为2,一个子进程它自身,一个是父进程,父进程将来用于释放子进程的资源。 -
将子进程的
task_struct返回
-
-
检查当前用户所创建的进程是否超过了上限,
current->signal->rlim[RLIMIT_NPROC].rlim_cur,否则的话不能创建进程,除非是root用户。疑问:为什么将这个检查放到进程创建以后,而不是创建之前? -
增加
struct user_struct的count(tsk->user->_ _count),以及当前进程的用户所创建的进程数量(tsk->user->processes) -
确保进程的数量没有超过内核上限(没有超过max_threads进程)
-
进程一些状态设置,不展开了
-
设置新进程的pid
-
设置进程的
list_head相关的数据结构,主要是保存进程子进程和兄弟进程。此外还有pending的信号,计时器,time statistics -
复制父进程的各种资源,调用
copy_semundo(), copy_files( ), copy_fs( ), copy_sighand( ), copy_signal(), copy_mm( ), and copy_namespace( ),除非设置与之相对的flag。前面提到过COW,因此copy_mm()完全复制了父进程地址空间。 -
调用
copy_thread来初始化子进程的内核栈,其中包括了子进程调用clone()时的各种寄存器的值。不过copy_thread()会将子进程内核栈的eax寄存器的值设置为0(这里设置的都是struct thread_struct里的值,而不是实际寄存器的内容,下同),esp寄存器设置为子进程的栈指针的base address,eip设置为ret_from_fork()函数的地址,如果进程使用IO位图,那么也复制IO位图。cint copy_thread(int nr, unsigned long clone_flags, unsigned long esp, unsigned long unused, struct task_struct * p, struct pt_regs * regs) { // 省略一些代码 // ... // childregs 位于内核栈的栈顶位置,回想前面说的thread_info位于内核栈的栈底 // 所以THREAD_SIZE + (unsigned long) p->thread_info 得到了栈顶地址 // 然后该地址减去 sizeof(struct pt_regs) 得到了通用寄存器在栈的内存地址 childregs = ((struct pt_regs *) (THREAD_SIZE + (unsigned long) p->thread_info)) - 1; // 复制父进程的寄存器(context)给子进程 *childregs = *regs; // 将eax设置为0,目的是让子进程中fork返回值为0 childregs->eax = 0; // 设置进程的用户栈地址 childregs->esp = esp; // 设置内核栈为内核栈的base address p->thread.esp = (unsigned long) childregs; // 将esp0 重新设置到内核栈的栈顶,后续切换进程时esp0会被写入到CPU的TSS p->thread.esp0 = (unsigned long) (childregs+1); // 重新设置eip,ret指令将导致它从ret_from_fork开始执行 p->thread.eip = (unsigned long) ret_from_fork; }当父进程调用系统调用陷入到内核态时,此时它的各种通用寄存器都保存在父进程的内核栈中(应该位于内核栈的栈顶),
*childregs = *regs;就是将寄存器复制一份给子进程。p->thread.esp = (unsigned long) childregs;被赋值到了内核栈的base address(base address,我理解的是通用寄存器位于这块内容的底部),后续进程返回用户进程到时候,从这里开始弹出各种通用寄存器的值(这个应该在中断返回的地方)。Note: 内核栈是在
dup_task_struct函数申请的,不过那会还没有初始化内核栈,知道这时才初始化内核栈。 -
Initializes the tsk->exit_signal field with the signal number encoded in the low bits of the clone_flags parameter. 一般是都是SIGCHLD
-
调用
sched_fork()来设置进程中和调度相关的数据,将进程设置为TASK_RUNNING状态,并且子进程和父进程共享一样的时间片(timeslice) -
设置进程的
thread_info里的cpu字段(表示进程执行于哪个CPU) -
设置子进程的父进程为当前进程
-
执行
SET_LINKS将子进程加入到process list -
如果子进程是thread group 的leader,那么tgid等同于它的pid,
tsk->group_leader执行tsk (自己指向自己) -
否则的话,子进程属于它父进程的thread group(起用了CLONE_THREAD)标志。那么tgid指向父进程的tgid(也就是父进程的PID),
group_leader指向父进程的group_leader -
一个新的线程被创建,增加
nr_threads计数器 -
增加
total_forks,表明多少进程被创建了 -
创建进程结束,返回子进程的 process descriptor pointer
创建进程属实麻烦,在将来进程被调度器选择选择以后,恢复它在thread字段中的寄存器,此时esp指向了内核栈地址,eip指向了ret_from_fork,它调用了schedule_tail()然后调用了finish_task_switch()完成了进程的切换,加载内核栈中其他各种通用寄存器的内容,最后回到了用户态。
内核线程
传统的Unix系统会将部分任务交给内核线程,包括:刷写硬盘缓存,将页换出,处理网络连接等,内核线程和普通进程的区别在于:
- 内核线程只运行在内核空间,然而普通进程在内核空间和用户空间交替运行
- 因为它们只运行在内核空间,所以它们所用的地址空间只会高于PAGE_OFFSET,更具体的内核线程的
mm字段为NULL。
内核线程由kernel_thread()函数创建,内部会调用do_fork(),kernel_thread源码在arch/i386/kernel/process.c
cdo_fork(flags|CLONE_VM|CLONE_UNTRACED, 0, pregs, 0, NULL, NULL);
因为所有内核线程都是运行在内核空间,所以它们是完全空间地址空间的,这就是为什么设置CLONE_VM的原因。ebx和eax寄存器会被copy_thread设置为fn和arg,分别表示运行的程序和参数,eip寄存器被设置为如下汇编代码:
movl %edx,%eax pushl %edx call *%ebx pushl %eax call do_exit
因此,call *%ebx就开始执行内核线程的程序了。
Process 0 and Process 1
所有进程的祖先都是0号进程,称为idle进程(之前写bpf程序老遇到它,以前不知所以然),它是swapper process,至于它的初始化就略。start_kernel()函数会初始化所有内核所需要的数据结构,开启中断,创建其他内核线程,包括1号进程,代码如下:
kernel_thread(init, NULL, CLONE_FS|CLONE_SIGHAND);
它共享所有0号进程的数据结构(因为内核线程不运行在用户态,所以栈应该只有内核栈,所以栈应该是不共享的),1号进程会被调度算法选中,执行它的程序。init进程创建以后,0号进程调用cpu_idle()函数。内核通过init()函数创建0号进程,紧接着调用execve()加载1号进程的程序,于是init进程与普通进程无异,init进程永不会消亡,它定期的监视着其他进程的状态实现了操作系统的其他功能。
Note: 现在的很多内核已经被systemd替代了1号进程了。
sysetmd wiki: https://en.wikipedia.org/wiki/Systemd
Other kernel threads
除了这俩内核线程以外,还有其他内核线程:
- keventd: 执行
keventd_wqworkqueue 里的函数 - ksoftirqd: 运行tasklet(和软中断相关),每个CPU都有这样的一个线程
- kblockd: 执行
kblockd_workqueueworkqueue里的函数,本质来说它的作用就是持续不断的激活block device drivers - kswapd:回收内存
进程的销毁
进程调用exit()之后就退出了,释放了它所有的资源,以及它注册的函数(通过atexit()注册的),最后调用系统调用来将这个进程彻底的移除。C 编译器会在main函数以后插入exit()。内核可能强制将整个thread group退出,这通常发生在内核收到了无法被ignore的信号(SIGKILL)或者是遇到了CPU exception(如除0异常)。从Linux 2.6开始,两个系统调用都会终止执行的进程:
exit_group()会退出整个thread group,也就是多线程程序的退出._exit()结束单个进程,无论thread group当中的其他进程的状态。这个函数也是被pthread_exit()调用的。
The do_group_exit() function
do_group_exit()函数当前进程所属的thread group的其他进程,它接受一个exit code 来自exit_group()系统调用或者是进程遇到异常情况由内核给出的状态码。它的执行过程如下:
- 检查进程的
SIGNAL_GROUP_EXIT标志是否为0(进程的flag是一个bitmap),如果不为0就以参数的exit code 作为current->signal->group_exit_code - 将进程的SIGNAL_GROUP_EXIT标志置位,并且将exit code写到
current->signal->group_exit_code - 调用
zap_other_threads()函数结束其他进程,任何与当前进程(current)不同的线程,都将发送一个SIGKILL信号给它。 - 调用
do_exit(),传给它的参数是exit code。
The do_exit() function
do_exit()函数是进程退出的关键函数,sys_exit()调用的也是它,它接收exit code作为参数,下面是它的流程:
- 设置
PF_EXITINGflag in flag field ofstruct task_struct,表示经常正在处于被回收的状态 - 将process descriptor从各种资源detach,如paging,打开的文件,namespace等,调用
exit_mm(), exit_sem(), __exit_files(), __exit_fs(),exit_namespace(), and exit_thread(),如果这些资源没有进程在使用,也会将这些资源移除。 - 将进程中的
exit_code字段设置为 exit code - 调用
exit_notify(),它做的事情有很多,挑一些讲。首先更新进程的关系,由被结束进程创建的子进程成为它(被结束的)所处的thread group的其他进程的子进程,如果没有那么就被init接管(这部分调用的是forget_original_parent()函数)。如果被结束的进程是thread group的最后一个进程,发送SIGCHLD给父进程,将进程设置为状态EXIT_ZOMBIE,也就是说进程一定会有一个EXIT_ZOMBIE状态。 - 调用
schedule()函数来挑选一个新进程执行
这块内容还有些不理解的地方,按照APUE的说法,任何进程内的一个线程调用exit都会退出整个进程,那么pthread_exit()是如何实现一个一个线程退出的呢?
If any thread within a process calls exit, _Exit, or _exit, then the entire process terminates. Similarly, when the default action is to terminate the process, a signal sent to a thread will terminate the entire process
Process Removal
Unix进程允许进程向内核查询它的父进程或者子进程的状态。一个进程可以创建子进程后,调用wait()系列函数来确认子进程是否结束,如果结束了termination code将会告诉父进程子进程是否已经成功执行。为了满足这样的设计,即使在进程退出以后,它相关的process descriptor field 也不能立刻丢弃,只有在父进程调用wait()函数以后才可以,这也就是为什么进程会存在EXIT_ZOMBIE状态的原因,一个退出的进程在父进程调用wait()函数之前都是处于EXIT_ZOMBIE状态。那么如果父进程先退出怎么办?那不是系统中充满了僵尸进程将内存耗尽,好在init进程将会称为所有僵尸进程的父进程,调用wait()函数回收这些僵尸进程。最后对于release_task()的描述就略了。
本文作者:strickland
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!