目录
和所有的time sharing 系统一样,Linux通过短时间内进程切换来模拟实现多个进程同时运行的假象。前面我们讨论了进程的基本实现,本章关注进程的调度。
Scheduling Policy
Linux的进程调度基于时间片的,每个进程运行一段时间后被换下。然而并没有那么简单,还需要根据进程的优先级进行调度。进程分为三个类型:
- Interactive processes 交互性的应用如文本编辑器,这类程序的响应时间必须快一些,因为调度引入的延迟有需要短
- Batch processes 运行在后台,不与用户交互,因此慢一点也没啥关系
- Real-time processes 有严格调度要求,这种类型的进程不能被低优先级的进程所阻塞并且也需要保证响应时间要比较固定。
对于real time process的描述比较模糊,另外的定义可以参考:https://tldp.org/LDP/tlk/kernel/processes.html
This is the scheduling policy that will be applied to this process. There are two types of Linux process, normal and real time. Real time processes have a higher priority than all of the other processes. If there is a real time process ready to run, it will always run first. Real time processes may have two types of
policy, round robin and first in first out. In round robin scheduling, each runnable real time process is run in turn and in first in, first out scheduling each runnable process is run in the order that it is in on the run queue and that order is never changed.
Process Preemption
Linux 进程是可抢占的,当一个进程进入到TASK_RUNNING状态时,内核会确认该进程的priority是否大于此时的current来决定是否换下当前进程转而去执行刚刚成为runnable的进程。当然进程随着时间片结束也会被中断执行,设置进程的TIF_NEED_RESCHED flag,在时钟的中断处理函数中调用scheduler。
一个具体的例子,假设此时系统中只有一个文本编辑器(text editor)和compiler,文本编辑器是交互式程序,调度的优先级必然高于其他进程,但是按下键位的频率很低(无论你打字多块和计算机比起来都是很慢了),所以文本编辑器大部分时间处于被挂起状态。然而,当按下键位时,内核发现文本编辑器的优先级比编译器高多了,所以将编译器进程的flag设置为TIF_NEED_RESCHED,在中断结束后让scheduler将文本编辑器换下去。等待文本编辑器处理好了输入的文字,又陷入了挂起状态等待下一次的keypress到来。
注意,被换下去的进程并不是处于被挂起的状态,它仍然是TASK_RUNNING状态,只不过它不再占有CPU。
Note: 这里说的中断结束后被换下去的逻辑是,进程被设置了TIF_NEED_RESCHED,所有的中断处理函数最终会调用ret_from_inter和ret_from_exp两者最终都会判断进程是否被设置了TIF_NEED_RESCHED进而确定是否换下进程,参考中断这一章。
How Long Must a Quantum Last?
时间片到底多长呢?这实际上是一个需要权衡的值,假设一次进程切换需要5ms,时间片为10ms,那么一个时间片一半都用于进程切换,十分浪费。如果时间片过长,那么系统的并发性就很差,因为就绪进程需要等待很久才可以执行。一个常见的误区是,认为过长的时间片对于交互式应用的效果不好,然而这是不对的,如同前面所讨论的,交互式应用有更高的优先级,处于runnable状态会对现在的进程进行抢占。
The Scheduling Algorithm
早期的Linux调度器实现十分简单,就是遍历所有可以runnable的进程,根据它们的优先级选择一个最合适的进程运行。显然该调度器的效果很差,随着进程数量的增加,调度的时间会被延长。在Linux 2.6当中的调度算法更加复杂,因为它将选择进程的过程是常数时间的,无论实际可运行的进程有多少,它在多CPU以及调度交互式应用和batch processes都有了很好的提升。当没有进程执行到时候,scheduler总会执行swapper进程,它的pid为0,每个CPU都有自己的swapper进程。
进程会根据下面三种调度策略调度,书上对于这小部分的描述不好,https://man7.org/linux/man-pages/man7/sched.7.html更合适
- SCHED_FIFO: First-In, First-Out,进程可以持续的运行除非它主动放弃CPU或者有优先级更高的进程抢占。被抢占时,它加入到它所处的优先级的run queue的头部,当优先级比高的进程都执行完毕后恢复执行。
- SCHED_RR: 和FIFO差不多,但是当时间片用完以后它会被换下,并且加入到它所处的run queue的尾部。
- SCHED_NORMAL: A conventional, time-shared process.
Scheduling of Conventional Processes
每个普通进程有一个静态优先级(static priority),可选的取值是100(最高优先级)到139(最低优先级),新创建的进程会从父进程继承static priority,用户可以用过nice()和setpriority()来调整。
Base time quantum
static priority 决定了进程的时间片,由一下的表达计算:
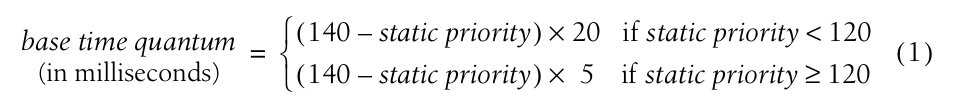
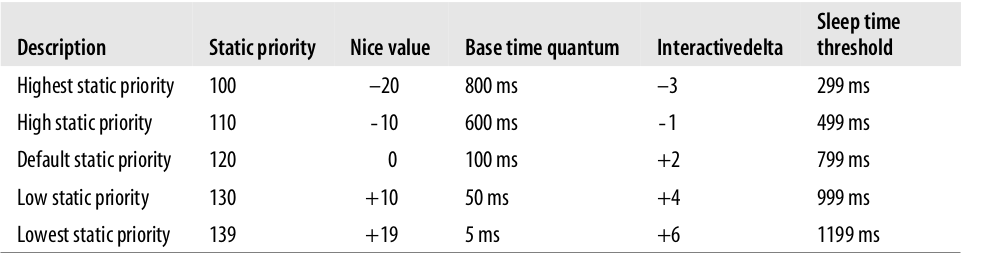
根据表达式可知,static priority更高的进程有更长的时间片因此可以占据CPU的时间越长。下图是常见的进程优先级、它的nice值以及时间片长度:
Dynamic priority and average sleep time
dynamic priority的作用是调度器决定哪一个进程去执行,根据如下的表达式计算:
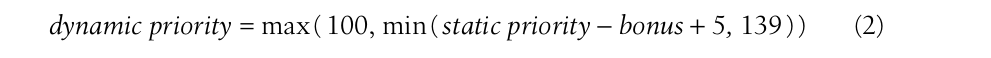
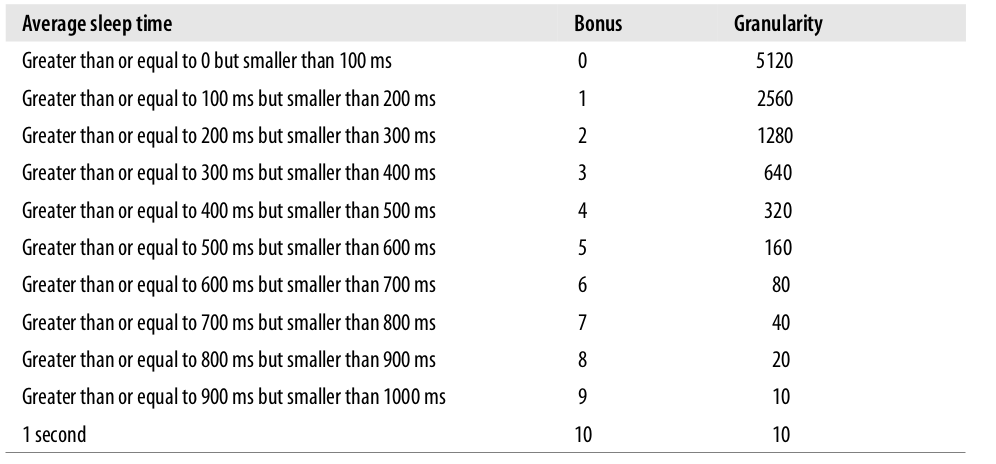
bonus在0到10之间浮动,小于5将会降低dynamic priority,反之则增加。bonus的取值根据进程的过去的信息,准确的说是根据他的average sleep time,指的是它过去多少时间用于sleeping。下面是休眠时间和bonus之间的关系,granularity的作用后面会讲述:
scheduler根据average sleep time来判断进程是否为交互性进程(interactive process),表达式如下:
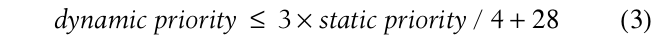
该表达式成立那么就是一个交互性进程。
Active and expired processes
在前面的描述中,我们说过static priority决定进程可用的时间片,但是高优先级的进程不应该彻底的阻塞低优先级机场的执行。为了避免低优先级进程的饥饿,当一个进程用完了它的时间片,可以被低优先级并且时间片还没有用完的进程所替代。为了实现这一目的,调度器又将进程划分为两种类型:
- Active processes 处于runnable状态并且时间片还没有用完的进程
- Expired processes 处于runnable的进程,但是时间片用完了,只有等所有的active进程运行结束以后才可以继续运行
不过实际的情况会稍微复杂一些,详情见书中文档。
Scheduling of Real-Time Processes
Data Structures Used by the Scheduler
在进程一章中,我们说过进程都是以双向链表组织在一起的,所有处于TASK_RUNNING状态的进程所在的链表称为runqueue。
The runqueue Data Structure
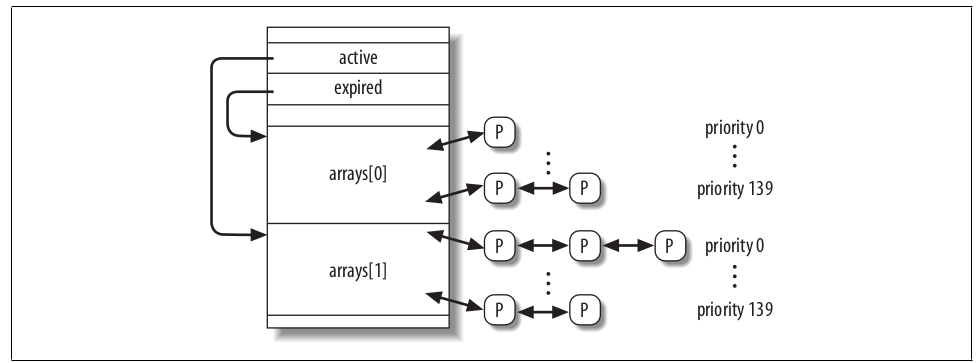
runqueue是Linux 2.6调度器中最重要的数据结构。每个CPU都有自己的runqueue,存在一个runqueues的per-CPU variable,this_rq()宏返回当前CPU的runqueue,cpu_rq(n)返回nth cpu的runqueue。struct runqueue 源码位于kernel/sched.c,其中最重要是管理线程的双向链表,任何一个进程只能属于一个runqueue,不过后面我们会学习到,一个进程可以从一个runqueue迁移到另外一个runqueue。runqueue 结构里的arrays成员变量是一个长度为2的struct prio_array_t数组,源码如下:
c// 源码位于:kernel/sched.c
struct prio_array {
unsigned int nr_active;
unsigned long bitmap[BITMAP_SIZE];
struct list_head queue[MAX_PRIO]; // 按照优先级将进程组织在同一个双向链表
};
struct runqueue结构里面的active和expired和arrays的关系如下,struct prio_array将每个优先级的进程都组成了一个双向链表。定期地,arrays它们的角色会发生改变,active会变成expire,expire会变成active,scheduler通过交换两者的内容来实现这一点。
Process Descriptor
当一个新进程被创建,sched_fork()设置进程时间片的代码如下,源码位于kernel/sched.c:
cp->time_slice = (current->time_slice + 1) >> 1;
current->time_slice >>= 1;
这表示父进程的时间片一分为二,一半给自己一半给子进程。这样做的目的是,系统中总体的时间片并没有变化,保证了调度的公平性。如果不这样做,假设每次创建进程都分配一个新的时间片值,那么创建同类型的子进程多个,这些进程在总体系统的时间片的比重会增大,相对来说就增加了它获得CPU的时间,霸占了CPU。如果父进程的时间片为1,创建进程会导致父进程的时间片立刻被用完(1>>1==0),在这种情况下copy_process()会重新将父进程的时间片设置为1,然后调用scheduler_tick()再减少该值,这部分代码:
c// 源码位于:kernel/sched.c
if (unlikely(!current->time_slice)) {
/*
* This case is rare, it happens when the parent has only
* a single jiffy left from its timeslice. Taking the
* runqueue lock is not a problem.
*/
current->time_slice = 1;
preempt_disable();
scheduler_tick();
local_irq_enable();
preempt_enable();
}
copy_process()函数还初始化了子进程的其他字段(实际我看的源码和书上描述的有区别,源码中这些字段在sched_fork()被初始化):
cp->first_time_slice = 1;
p->timestamp = sched_clock();
first_time_slice作用是表明进程是否用完了它的时间片,因为新创建的子进程还没有用完,所以该值设置为1。
if a process terminates or executes a new program during its first time slice, the parent process is rewarded with the remaining time slice of the child
sched_clock()获取当前64bit的时间戳。
Functions Used by the Scheduler
下面是调度器(scheduler)工作的几个关键函数:
- scheduler_tick() 保证当前进程的time_slice counter 是最新的(这应该说的是保证对时间片的持续更新)
- try_to_wake_up() 唤醒一个睡觉的进程
- recalc_task_prio() 更新进程的dynamic priority
- schedule() 调度一个新的进程去执行
- load_balance() 多CPU之间的runqueue长度保持平衡
The scheduler_tick( ) Function
scheduler_tick()会在每次时钟中断发生时(kernel/timer.c的update_process_times函数)调用,它执行下面的操作:
-
runqueue的
timestamp_last_tick成员变量保存为当前的时间戳 -
确认当前进程是否为
swapper进程(0号进程),如果是将当前进程设置TIF_NEED_RESCHEDflag来强制切换进程 -
确认当前进程的
current->array是否指向runqueue的active list,如果不是表明当前进程的时间片用完了但是还没有被换下CPU,设置它的TIF_NEED_RESCHEDflag,然后离开scheduler_tick()函数,源码:cif (p->array != rq->active) { set_tsk_need_resched(p); goto out; } -
递减当前进程时间片,确认时间片是否用尽,然而进程的类型不同也有不同的处理,后面会在讨论该内容。
-
调用
rebalance_tick(),确保每个CPU的runqueue长度是均衡的。
Updating the time slice of a real-time process
如果当前进程FIFO real-time process啥也不做(FIFO是一个调度策略),实际上该策略下当前进程不能被低优先级的进程抢占。如果当前进程是Round Robin real-time process,scheduler_tick()会递减的时间片,确认时间片是否用完:
cif (current->policy == SCHED_RR && !--current->time_slice) {
// 重新设置进程的时间盘
current->time_slice = task_timeslice(current);
// 它的首次时间片已经用完,将 first_time_slice 设置为0
current->first_time_slice = 0;
// 设置当前进程的 TIF_NEED_RESCHED flag,在 ret_from_inter 中会判断进程的该标志
// 中断处理函数最终调用 shcedule() 来切换进程
set_tsk_need_resched(current);
// 将进程从 active 链表中移除
list_del(¤t->run_list);
// 然后把进程添加回去
list_add_tail(¤t->run_list,this_rq()->active->queue+current->prio);
}
最后两行和源码有些出入,源码当中调用的是list_move_tail(),根据函数名猜测是将上述两行合二为一了。
Updating the time slice of a conventional process
如果是普通进程,scheduler_tick()会执行下面的流程:
-
递减时间片
current->time_slice -
确认进程的时间片是否用完,如果是:
-
调用
dequeue_task()从active 链表中将当前进程移除 -
调用
set_tsk_need_resched()设置进程的 TIF_NEED_RESCHED flag -
更新进程的dynamic priority:
current->prio = effective_prio(current);,effective_prio()根据static priorit和sleep_avg来计算的,根据前面提到的表达式 -
重新填充它的时间片:
cp->time_slice = task_timeslice(p); p->first_time_slice = 0; -
将当前进程插入到active 或者是 expired 链表:
cif (!TASK_INTERACTIVE(p) || EXPIRED_STARVING(rq)) { // 当前进程不是交互式进程或者过期队列中有优先级更高的进程,那么将当前进程插入到过期队列。 enqueue_task(p, rq->expired); if (p->static_prio < rq->best_expired_prio) rq->best_expired_prio = p->static_prio; } else // 如果是交互性进程,重新分配时间以后,重新将进程加入到 runqueue enqueue_task(p, rq->active);
-
-
如果时间片没用完,确认当前进程剩下的时间片是不是太多了。一个static priority 较高的进程(说明有很长的时间片)的时间片会被分为
TIMESLICE_GRANULARITYpieces,所以它不会霸占CPU。
参考:https://blog.csdn.net/Rachelint/article/details/107052275
The try_to_wake_up( ) Function
try_to_wake_up()唤醒一个处于stopped或者sleeping的进程,将其状态设置为TASK_RUNNING状态并且插入到当前CPU的runqueue。比如说一个进程处于休眠状态,休眠的进程都被放到了一个 wait queue,那就可以调用try_to_wake_up()唤醒进程,它的参数列表为:
- 要被唤醒的进程p
- 一个mask,表明进程处于哪些状态可以被唤醒
- 一个flag来确定被唤醒的进程是否抢占正在CPU执行的进程
该函数的执行流程如下:
- 调用
task_rq_lock()关闭当前CPU中断,获取目标p上次执行的CPU的runqueue的锁 - 确认进程的
p->state是否属于参数state,如果不是那么退出函数执行 - 如果
p->array不为空,那么表示进程已经属于一个runqueue,跳转到step 8 (唤醒一个已经处于runqueue(表明它已经是处于可运行状态)是没有意义的) - 在多处理系统中,确认被唤醒的进程是否需要从它上次它所运行的CPU的runqueue迁移。如何选择目标runqueue迁移,这里有几条细则就不展开了。
- 如果进程
p处于TASK_UNINTERRUPTIBLE,递减runqueue的nr_uninterruptible(表示有多少进程处于TASK_UNINTERRUPTIBLE状态),并且将进程的p->activated=-1,这个变量啥用?后面会说 - 调用
activate_task()函数,它做的事情:- 调用
sched_clock()获取此时的时间戳,不同的CPU之间存在一定的drift。 - 调用
recalc_task_prio(),后面会详细描述,看函数名称猜测是重新计算优先级 - 重新设置
p->activated=1变量,该变量每种取值会在后面讲述 - 设置进程
p->timestamp时间戳为前面获取到的值 - 将进程插入到active链表,等待后续的调度
- 调用
- 确认目标CPU(被唤醒的进程上次所执行的CPU)是否和
try_to_wake_up()函数所执行的CPU是同一个,如果不是再判断被唤醒进程的dynamic priority 是否高于当前进程,如果是的话被唤醒进程就抢占当前进程。唤醒一个高优先级进程抢占当前进程的CPU从逻辑来说还是比较自然的。 - 设置被唤醒状态为
TASK_RUNNING - 最后释放锁,函数结束
The recalc_task_prio() Function
recalc_task_prio()调整进程的average sleep time和dynamic process(直接影响到进程的调度),它接收两个参数:目标进程p和此时的时间戳now,下面是该函数的执行流程:
-
将
now - p->timestamp的值保存到临时变量__sleep_time。p->timestamp里面存放的是进程上一次睡觉的时间,因此__sleep_time就记录了进程从上一次执行完了以后陷入睡眠的时间(如果进程休眠了更长的时间,那sleep_time就取1s)。cunsigned long long __sleep_time = now - p->timestamp; unsigned long sleep_time; if (__sleep_time > NS_MAX_SLEEP_AVG) sleep_time = NS_MAX_SLEEP_AVG; else sleep_time = (unsigned long)__sleep_time; -
如果
sleep_time不大于0,那么跳过修改average sleep time,跳转到步骤8 -
如果进程不是内核进程(
p->mm不为空),确认进程是否从TASK_UNINTERRUPTIBLE状态唤醒(检查p->activated的值是否为-1,可以看上一小节的内容)并且进程是否休眠的时间超过了一个预设的阈值,如果是直接到步骤8。进程休眠的阈值和它的staic priority 有关,简而言之static priority 越低休眠阈值也越低,目的是为了让处于uninterruptible状态的进程(通常在等待硬盘IO)休眠一个预先时间来保证它们可以被更快的处理。 -
调用
CURRENT_BONUS宏计算bonus,如果10 – bonus大于0,那么这个宏会乘上sleep_time该值,因为sleep_time最终会加到average sleep time,the lower the current average sleep time is, the more rapidly it will rise.(没有特别明白) -
如果进程处于
TASK_UNINTERRUPTIBLE状态并且不是内核线程(p->mm不为空),那么:- 确认进程的
p->sleep_avg是否大于睡眠阈值,如果是将sleep_time直接设置为0 - 如果
sleep_time+ p->sleep_avg大于等于休眠阈值,那么将p->sleep_avg设置为休眠阈值
- 确认进程的
-
调整 average sleep time,代码:
p->sleep_avg += sleep_time; -
确认
p->sleep_avg是否超过了1000个ticks,如果是那么p->sleep_avg = NS_MAX_SLEEP_AVG; -
调用函数
effective_prio(p)来调整进程的 dyanmic priority,effective_prio(p)原理就是根据进程的average sleep time 和bouns 相结合计算出优先级。
The schedule( ) Function
进程调度的核心函数是schedule(),它的目标是从runqueue中找一个进程去执行,该函数是有两种调用的情况:lazy和direct。
Note: 本小节讲述的调度算法是O(1)算法,在 Linux 2.6.23 被替换为了 CFS 算法。
Direct invocation
被当前进程主动调用,当当前进程所等待的资源不可用而陷入阻塞时,内核会执行下面的工作
- 将当前进程插入到wait queue
- 将进程状态设置为
TASK_INTERRUPTIBLEor toTASK_UNINTERRUPTIBLE - 调用
schedule()切换进程 - 确认资源是否可用,如果不是回到2
- 一旦资源可用,将进程从wait queue移除
内核代码持续不断的确认资源的状态,调用schedule()换下CPU,当进程重新赋予CPU时,再一次确认资源状态,重复这个过程,直到资源可用。
Lazy invocation
通过设置进程的TIF_NEED_RESCHED flag,因为该标志会在返回用户态时每一次都被检查,schedule()总会被将来的某时调用(毕竟,在内核态早晚要回到用户态),下面是一些lazy的例子:
-
当前进程的时间片用完了,
scheduler_tick()函数会设置该标志 -
进程被唤醒并且它的优先级高于正在运行的进程,函数
try_to_wake_up() -
调用
sched_setscheduler()系统调用
schedule( )
终于到了调度函数,曾经想自己看调度函数的原理,属实看不明白,经过一些知识储备以后,终于也可以可见一斑了。
首先schedule()函数关闭了进程抢占并且初始画了一些变量:
cneed_resched:
// 关闭进程抢占,原理是将当前进程的 preempt_count增加
preempt_disable();
prev = current;
rq = this_rq();
然后确认prev没有持有 big kernel lock :
cif (prev->lock_depth >= 0)
up(&kernel_sem);
接下来,如果prev进程已经结束了,那需要重新设置进程的状态:
cif (prev->flags & PF_DEAD)
prev->state = EXIT_DEAD;
接下来确认prev的状态,如果它不是runnable并且没有在内核态中被抢占,那么它应该从runqueue 中移除。如果它有非阻塞的信号并且处于TASK_INTERRUPTIBLE状态(比如调用sleep会陷入该状态),那么设置进程的状态为TASK_RUNNING。这并意味这将CPU直接分配给进程prev,而是代表着在将来它有机会被执行(因为它处于runnable状态,将来早晚会被插入到runqueue)。
cif (prev->state != TASK_RUNNING &&
!(preempt_count() & PREEMPT_ACTIVE)) {
if (prev->state == TASK_INTERRUPTIBLE && signal_pending(prev))
prev->state = TASK_RUNNING;
else {
if (prev->state == TASK_UNINTERRUPTIBLE)
rq->nr_uninterruptible++;
deactivate_task(prev, rq);
}
}
deactivate_task()函数则将进程从runqueue中移除,它的源码:
crq->nr_running--;
dequeue_task(p, p->array);
p->array = NULL; // 将进程的所处的runqueue的struct prio_array_t 设置为null,这可以认为进程此时不属于任何一个runqueue
接下来确认处于runnable进程的数量,如果还有一些进程可以执行,调用dependent_sleeper()函数,大部分情况下该函数立刻返回了0。不过在hyper-threading情况下,它会确认接下来被选取执行的进程会比它的兄弟进程(运行在同一个实际的CPU)的优先级高低,这种情况下不会去执行低优先级的进程而是去执行swapper进程。
cif (dependent_sleeper(cpu, rq)) {
next = rq->idle;
goto switch_tasks;
}
// ... 省略了一些代码
switch_tasks:
if (next == rq->idle)
schedstat_inc(rq, sched_goidle);
如果runqueue中没有可以执行的进程,那调用idle_balance()来从其他local runqueue中搬一些进程过来。
c// 如果没有可以执行的进程,进入代码下面的代码
if (unlikely(!rq->nr_running)) {
go_idle:
idle_balance(cpu, rq);
if (!rq->nr_running) {
// 如果其他CPU没有可以执行的进程,那么下一个进程就是 swapper 进程了
next = rq->idle;
rq->expired_timestamp = 0;
wake_sleeping_dependent(cpu, rq);
/*
* wake_sleeping_dependent() might have released
* the runqueue, so break out if we got new
* tasks meanwhile:
*/
if (!rq->nr_running)
goto switch_tasks;
}
接下来判断runqueue中是否还有runnable的进程,如果没有就交换active和expired的内容,因此所有expired的进程都成为了active进程,于是expired进程空空如也,可以用来插入时间片用完的进程。
carray = rq->active;
// 当前 runqueue 是否还有 runnabel的进程?
// 如果条件成立,那么说明此时 active 长度为0,交换 active 和expired
if (unlikely(!array->nr_active)) {
/*
* Switch the active and expired arrays.
*/
schedstat_inc(rq, sched_switch);
rq->active = rq->expired;
rq->expired = array;
array = rq->active;
rq->expired_timestamp = 0;
rq->best_expired_prio = MAX_PRIO;
} else
schedstat_inc(rq, sched_noswitch);
接下来选择下一个要被执行的进程,它运用了bitmap来快速查找不为空的priority list,所以返回的idx是目标进程所处的链表:
cidx = sched_find_first_bit(array->bitmap);
queue = array->queue + idx;
// list_entry表示在找出ptr指向的链表节点所在的type类型的结构体首地址,member时type类型结构体成员。
// 参考:https://blog.csdn.net/zsj100213/article/details/81843523
// 找到下一个可执行的进程
next = list_entry(queue->next, task_t, run_list);
接下来是next->activated进入到了舞台,该成员变量的可取值如下,表示是该进程被唤醒时所处的状态。

如果进程是从TASK_INTERRUPTIBLE或者TASK_STOPPED状态中唤醒的,那么会将 average sleep time 算到它的优先级里,重新调整它在runqueue中的位置。对于频繁睡眠的进程,降低它们的优先级是符合逻辑的:
cif (!rt_task(next) && next->activated > 0) {
unsigned long long delta = now - next->timestamp;
if (next->activated == 1)
delta = delta * (ON_RUNQUEUE_WEIGHT * 128 / 100) / 128;
array = next->array;
// 从它现在的链表中弹出
dequeue_task(next, array);
// 重新计算它的优先级
recalc_task_prio(next, next->timestamp + delta);
// 重新插入到链表
enqueue_task(next, array);
}
到此为止,schedule()选择了下一个进程,接下来内核要获取下一个进程的thread_info:
cswitch_tasks: prefetch(next);
prefetch宏的目的是提示CPU将下一个进程的process descriptor放到硬件缓存里,提高性能。接下来确认next和prev是否为同一个进程,如果是的话就不再需要切换进程:
cif (prev == next) {
spin_unlock_irq(&rq->lock);
goto finish_schedule;
}
如果不是,准备开始切换进程。context_switch()会设置下一个进程的地址空间。对于一般进程来说,p->active_mm和p->mm是等价的,前者表示进程所使用的地址空间,后者表示进程所持有的地址空间。但是对于内核进程而言,mm是为NULL,因此context_switch()中如果发现是内核进程,就不需要切换进程地址空间。在Linux 2.2 以前内核进程也有地址空间,内核进程共享地址空间避免了切换进程的开销(更新cr3会刷新所有的TLB缓存)。
cif (likely(prev != next)) {
// 只有前面一个
next->timestamp = now;
rq->nr_switches++;
rq->curr = next;
++*switch_count;
prepare_arch_switch(rq, next);
// 准确切换进程
prev = context_switch(rq, prev, next);
barrier();
finish_task_switch(prev);
} else
spin_unlock_irq(&rq->lock);
// context_switch() 代码,如果下一个进程是内核进程,那么不需要切换进程地址空间。
if (!next->mm) {
next->active_mm = prev->active_mm;
atomic_inc(&prev->active_mm->mm_count);
enter_lazy_tlb(prev->active_mm, next);
}
如果是一个普通进程,那么很自然就开始切换进程的地址空间:
cswitch_mm(oldmm, mm, next);
// 重新加载下一个进程的 page directory 到cr3 寄存器
// switch_mm() 位于 include/asm-i386/mmu_context.h
load_cr3(next->pgd);
注意,内核广泛使用了COW来加快进程的创建,不过COW的实现位于copy_mm函数,而不是在switch_mm。所以切换进程地址空间的过程十分迅速,到此为止代码已经运行在新进程地址的地址空间了。这听起来是十分神奇,既然已经运行在新进程的地址空间了,那从内存中恢复寄存器的时候能正确进行吗?当然可以,因为所有进程地址空间的内核部分(4GB内存的高1GB内存都是给内核用)是共享的,虽然地址空间已经切换,内核空间没有发生变化,如何实现的呢?当然是每个进程的page table的内核部分映射到一块相同的物理内存就好了。最后,调用switch_to(prev, next, prev);切换到下一个进程的内核栈。
cswitch_to(prev, next, prev);
return prev;
Actions performed by schedule() after a process switch
到这为止,此时的内核栈指向的都是next的内核栈了。所以对于被换下的进程来说,在它的地址空间中,这部分代码是在未来被执行的(因为在switch_to宏当中我们将prev->thread.eip设置为了 标号1的地址,所以会从这里开始执行),也就是它重新被换上CPU以后会执行(在switch_to宏当中将标号1的地址写入到了prev->thread.eip)。然而此时的prev不再是原先的prev,而是被再次调用schedule()后它被换上CPU时的上一个进程(也就是switch_to宏里面的last),注意这一点和进程一章中的switch_to为什么需要三个参数这个问题联系起来。
当被换下的进程在再获取到CPU开始执行时,运行下面的代码:
cbarrier();
finish_task_switch(prev);
static void finish_task_switch(task_t *prev)
__releases(rq->lock)
{
runqueue_t *rq = this_rq();
struct mm_struct *mm = rq->prev_mm;
unsigned long prev_task_flags;
rq->prev_mm = NULL;
prev_task_flags = prev->flags;
finish_arch_switch(rq, prev);
if (mm)
mmdrop(mm);
if (unlikely(prev_task_flags & PF_DEAD))
put_task_struct(prev);
}
如果前者是一个内核进程,借用某个进程的mm_struct那么现在归还,现在切换到了下一个进程理应归还。疑问:对于mm_struct的借用是什么?
mmdrop(mm)会递减memory descriptor的usage counter,当它为0的时候最终导致内存的回收。finish_task_switch()函数还确认prev进程是否是僵尸进程(PF_DEAD flag是有被设置),如果是,那么还需要递减process descriptor reference counter和丢弃其他相关内容。最后:
cfinish_schedule:
prev = current;
if (prev->lock_depth >= 0)
_ _reacquire_kernel_lock();
preempt_enable_no_resched();
if (test_bit(TIF_NEED_RESCHED, ¤t_thread_info()->flags)
goto need_resched;
return
有必要的话,获得了全局的内核锁,再确认当前进程的TIF_NEED_RESCHED flag 是否被设置,如果是,那么还需重新进程(什么情况下会发生这种情况呢?)。
Runqueue Balancing in Multiprocessor Systems
现代的计算机多核处理器已经十分常见,下面是三种常见的多核PC:
-
Classic multiprocessor architecture
所有的CPU共享内存,这也被称为UMA(Uniform Memory Access),很显然这样的缺陷是CPU之间会存在访存冲突。
-
Hyper-threading
一个CPU被抽象为两个logic CPU,该技术最早由 Intel 发明,日常说的双核四线程就是值得hyper-threading技术。每个CPU有通用寄存器的多份拷贝,可以快速的进行切换。Hyper-threading特性使得当前线程访问内存被stall时去执行另外一个线程,然而从内核的角度来说,实际的CPU被抽象为了多个logic CPU。
-
NUMA
CPU和内存被划分为了local node(通常一个node包含一个CPU和多个RAM),因为在传统的UMA结构中memory arbiter是内存的瓶颈。在NUMA结构中,CPU访问local的内存不存在竞争关系,这有很快的速度,但是访问远端的(其他node)内存就速度更慢。
现在,hyper-threading和NUMA相结合已经十分常见了。schedule()的目的就是从当前CPU的runqueue选择一个进程去执行,所以一般来说一个runnable进程都是和一个CPU所绑定的,这一定程度上也是为了性能考虑,充分利用CPU的一些缓存。缺陷是,当大量batch process绑定到同一个CPU时,会让该CPU持续处于繁忙,然而其他CPU出于idle。因此定期的确认runqueue是否均衡,在必要的时候将进程在runqueue之间搬运。从Linux 2.6.7 开始采用一个复杂的算法,基于scheduling domains的概念实现的负载均衡算法。
Scheduling Domains
每个scheduling domain进一步被划分为多个group,进程可以在group之间移动。scheduling domain以struct sched_domain结构来表示,源码位于include/linux/sched.h:
cstruct sched_domain {
/* These fields must be setup */
struct sched_domain *parent; /* top domain must be null terminated */
struct sched_group *groups; /* the balancing groups of the domain */
// 省略了其他变量
}
groups指的是domain下的所有group所组成的链表,domain具有层级结构,因此parent指的是parent domain。内核所有的domain都存放在per-CPU variable phys_domains变量中。如果内核支持hyper-threading,bottom-level scheduling domains存在与per-CPU variable cpu_domains.
The rebalance_tick() Function
为了保证runqueue的均衡,scheduler_tick()每次调用时(时钟中断会调用该函数)最终都会调用rebalance_tick(),它接受三个参数:当前的CPU,当前的runqueue,一个flag,取值如下:
- SCHED_IDLE: 当前CPU处于空闲,即current进程就是swapper.
- NOT_IDLE:当前CPU处于非空闲状态
rebalance_tick()函数首先计算档当前CPU的负载,对应的源码是:
c// load 是runqueue结构下的一个成员变量
old_load = this_rq->cpu_load;
this_load = this_rq->nr_running * SCHED_LOAD_SCALE;
接下来就是所有遍历层级的domain进行负载均衡。参数idle的取值(也就是前面的flag,表示此时CPU是否处于idle状态)决定了调用load_balance()的频率,如果是SCHED_IDLE那么会调用的更加频繁,反之则频率更低。
cif (j - sd->last_balance >= interval) {
// 对 domain 进行负载均衡
if (load_balance(this_cpu, this_rq, sd, idle)) {
/* We've pulled tasks over so no longer idle */
idle = NOT_IDLE;
}
sd->last_balance += interval;
}
一个注意点,遍历domain是从 base domain(children domain)往 top level domain(最高层的domain),这个过程是从下到上顺序,源码:
c#define for_each_domain(cpu, domain) \
for (domain = cpu_rq(cpu)->sd; domain; domain = domain->parent)
The load_balance() Function
进行负载均衡的关键函数,目的是检查当前CPU负载不均的情况是否可以通过将进程在 groups 之间移动来改善,它接收四个参数:
- this_cpu: 当前CPU
- this_rq:当前CPU的runqueue
- sd:此时所操作的domain
- idle:同上,当前CPU是否空闲
该函数的基本流程如下:
-
this_rq->lock获取runqueue的锁 -
调用
find_busiest_group()函数来分析domain下哪个group是最繁忙的,前提是该group不包含当前CPU,也就是说只能返回除了自身CPU所处的group以外的group。这种情况下,该函数还需要所需要转移到当前runqueue的进程数量。另一个方面说,如果所有的group已经均衡,或者是最繁忙的group已经包含了当前CPU(即当前CPU所处的group已经最繁忙了),那么该函数返回NULL。 -
find_busiest_group()无法找到一个最繁忙的group,调整 parameters in the scheduling domain descriptor, delay the next invocation ofload_balance()on the local CPU, and terminates.从逻辑来说,当前group已经是最忙的,它能做的事确实很少,应该等待其他CPU来从它这里分走一些进程。
-
如果步骤2找到一个繁忙的group,接下来再调用
find_busiest_queue()从group里面找到一个最繁忙的CPU,获取它的runqueue地址(记作busiest)。该函数的源码很简单,就是类似于从一个链表中找到最大值。 -
获取
busiest->lock锁,这里需要先释放this_rq->lock来避免死锁。 -
调用
move_tasks()来尝试将busiestrunqueue 当中移动一些进程到当前cpu的runqueue(this_rq宏),然后这个函数返回所移动的进程数量。 -
如果
move_task()失败了,那么domain还是处于不平衡的状态,将busiest->active_balance设置为1,然后唤醒busiestrunqueue的migration kernel thread,这个内核线程的作用就是又遍历domain,找到一个idle CPU,给这个CPU 转移一个进程。这个内核线程所执行的函数是migration_thread(),源码位于kernel/sched.c。 -
最后释放锁,函数结束。
Note:
migration 进程也可以用ps -eaf命令看到,这种进程也是每个CPU都有一个,示例如下:

The move_tasks() Function
move_task()将进程从source runqueue 转移到当前的runqueue,它接收六个参数;
- this_rq 和 this_cpu: 分别表示当前的 runqueue 和当前cpu
- busiest:source runqueue descriptor
- max_nr_move: the maximum number of processes to be moved
- sd:the address of the scheduling domain descriptor in which this balancing operation is carried on
该函数首先确认 busiest 是否存在 expired 的进程(即那些时间片永远了但是仍然处于runnable的进程),如果没有在使用active process(时间片没有用完的runnable进程)这也符合逻辑的,将那些不是太活跃的进程移动是更好的选择。对于每个候选进程,调用can_migrate_task(),它将会在下面情况成立的时候返回1:
- 候选进程没有正在其他CPU执行
- 当前CPU可以被候选进程所使用,即使当前CPU被包含在了候选进程的
cpus_allowedmask - 还有一些其他附属条件,略。
如果can_migrate_task()返回1,接着调用pull_task()将候选进程移动到当前的 runqueue。本质来说,pull_task()做的事就是将候选进程从它原先的 runqueue 中调用 dequeue_task() 脱离,调用enqueue_task()重新加入到当前runqueue,最后如果候选进程的优先级大于当前进程,那么当前进程需要被抢占(通过设置进程的 flag,可以参考lazy scheduling 小节)下面是pull_task()的源码,位于kernel/sched.c:
cstatic inline
void pull_task(runqueue_t *src_rq, prio_array_t *src_array, task_t *p,
runqueue_t *this_rq, prio_array_t *this_array, int this_cpu)
{
dequeue_task(p, src_array);
src_rq->nr_running--;
set_task_cpu(p, this_cpu);
this_rq->nr_running++;
enqueue_task(p, this_array);
p->timestamp = (p->timestamp - src_rq->timestamp_last_tick)
+ this_rq->timestamp_last_tick;
/*
* Note that idle threads have a prio of MAX_PRIO, for this test
* to be always true for them.
*/
if (TASK_PREEMPTS_CURR(p, this_rq))
resched_task(this_rq->curr);
}
System Calls Related to Scheduling
内核提供了一些系统调用来调节进程的优先级,但是一个用户只能调低它自己所创建的进程的优先级,如果需要调整其他用户创建的进程的优先级,那必须要有 superuser privileges。
The nice( ) System Call
nice() 允许用户调整进程的优先级,它也是nice命令的底层实现,与之对应的系统调用是sys_nice()。nice()函数的可以是任意直,但是最终都会被缩减到的正负40的区间内。负值表示增加进程的优先级(static priority),然而这需要 superuser privileges,正值表示降低优先级。如果尝试增加优先级,内核需要确认用户是否有CAP_SYS_NICE权限,最终调用set_user_nice()函数,修改current进程的优先级,然后调用resched_task()允许其他进程来抢占。
nice()函数的存在只是为了兼容性考虑,它在后来被setpriority()函数所取代。
The sched_getaffinity( ) and sched_setaffinity( ) System Calls
sched_getaffinity()和sched_setaffinity分别获取和设置当前进程的对于CPU的亲和性,即进程允许执行的进程的 mask,这些信息被存放在进程的cpus_allowed字段。
sys_sched_getaffinity()的作用是返回根据pid查找进程,然后返回它可以使用的CPU,即将所有可用的CPU和cpus_allowed做 AND 运算。
End
最后还剩下一下和realtime process 相关的调度,暂时先略将来有需要再补充。
本文作者:strickland
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!