目录
本章与体系结构强相关,主要的参考文档来自:Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3 (3A, 3B, 3C, & 3D): System Programming Guide
中断(interrupt)通常被认为是改变CPU正在执行的指令的一种事件,与之对应的是来自CPU内外的电路信号,中断通常被分为两种类型:
- 同步(Synchronous)中断,are produced by the CPU control unit while executing instructions and are called synchronous because the control unit issues them only after terminating the execution of an instruction.
- 异步(Asynchronous)中断,由外部硬件设备发送,可能出现在任意时刻
在Intel的文档中,将同步中断称为异常(exception,如除0、访问了不合法的内存地址等),异步中断才被称为中断(interrupt),如用户按下了键盘。
中断提供了一个方法让处理器停下手头的工作,转而去执行其他事情,CPU将它此时cs和eip寄存器的内容保存在内核栈中,然后根据中断的类型设置相关寄存器的内容。本章一些内容会让人会想到进程切换过程中的上下文切换过程,不过两者的区别是中断处理并不是一个进程所做的事,而是内核,所以中断处理的过程比进程切换轻量很多(不需要处理任何与进程相关的各种内容)。
Note:内核并不是一个独立的进程,一个进程的地址空间划分中,内核位于进程内存地址的高处,每个进程的内核地址空间会被映射到相同的一块物理地址,因此可以说每个进程复用了内核。
中断处理是内核处理的最重要的任务之一,因为它必须满足如下的限定:
- 中断什么时候都可能发生,可能发生在内核正在处理一些其他事物。所以内核的目标是尽可能让中断尽快被响应,尽可能将处理任务延迟。因此内核对于中断的响应分为两个部分,critical urgent part that the kernel executes right away and a deferrable part that is left for later。
- 因为中断什么时候可能会到来,内核在处理某一个中断的时候可能新的中断到来了(不同类型的),这是非常重要的,这保证了让IO设备尽可能繁忙。所以这要求内核代码对于中断处理是可嵌套(nested)的。
- 当内核处理一个先前发送的中断时,新的中断到达了,此时内核可能处于某些关键代码(critical regions)以至于需要暂时的屏蔽中断,关键代码数量要尽可能少,因为根据前面的要求,内核需要保证大部分情况下中断是启用的。
任何一个能够发出中断的硬件设备都有一套输出线(single output line)被称为 Interrupt ReQuest (IRQ) line,所有IRQ都会连接到一块硬件电路称为Programmable Interrupt Controller(PIC,可编程中断控制器),该控制器它执行下面的动作:
-
监听所有的IRQ line,确认是否有中断发生,如果多个IRQ line都发送了信号,那么lower pin number的line会被选中
-
如果IRQ line发送了信号:
-
将对应的信号转为对应的vector,vector指的应该是中断或异常的number。
Each interrupt or exception is identified by a number ranging from 0 to 255; Intel calls this 8-bit unsigned number a vector.
-
将vector 写入到Interrupt Controller I/O port,让CPU可以通过data bus直接读取
-
发送一个信号给CPU 的 INTR pin,这就发送了一个中断给CPU
-
Waits until the CPU acknowledges the interrupt signal by writing into one of the Programmable Interrupt Controllers (PIC) I/O ports; when this occurs, clears the INTR line
-
-
回到第一步
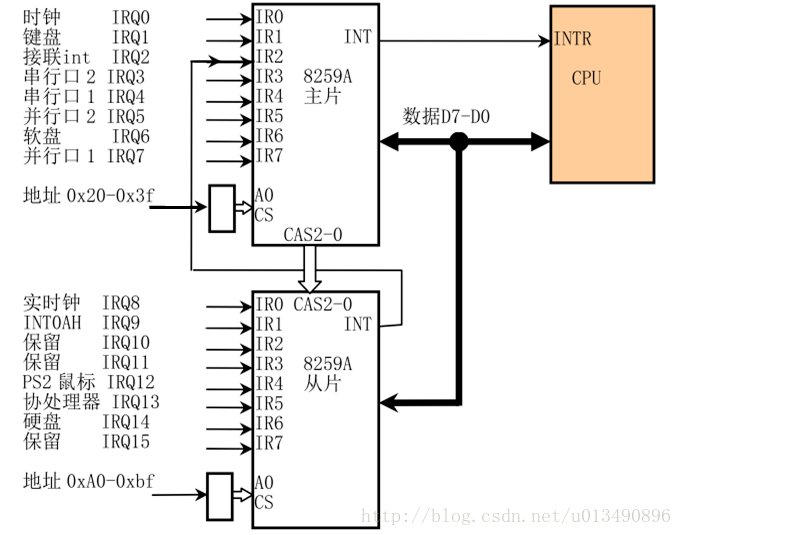
每一个IRQ line都可以被屏蔽,因此PIC可以通过编程来直接屏蔽IRQ。不过屏蔽了中断并不会代表着中断就此丢失,当被重新enable以后,PIC会重新发送中断给CPU,这个特性保证了同一种类型的中断可以串行化处理。关闭/打开 IRQ 并不等同于屏蔽中断,当eflags寄存中IF位被清除,任何一个有PIC发送的可屏蔽中断都将会被CPU忽视,cli和sti命令分别用于清除和设置该标志位。传统的PIC通过级联(in cascade)两块8259A芯片,单块的8259A能处理8个IRQ line,因为是级联的(两块拼接在一块儿),所以有一块的IRQ line用于接收从片的中断,因此一共可用的IRQ line是15。
Note: 因此这说明单处理器搭配了两块8259A芯片的最多只能处理15种外设的中断,8259A的资料很多,下面是级联8259A示意图:
The Advanced Programmable Interrupt Controller (APIC)
前面描述的是针对单核处理器设计的PIC,对于单核CPU,master PIC的output line直接连接带INTR pin,然而如果有多个处理器,这种方法就不再适用了。为了SMP的并行性,每个CPU分发中断是十分重要的。从奔腾3开始,Intel引入了I/O Advanced Programmable Interrupt Controller (I/O APIC),是8259A的高级版,为了兼容性,很多主板上支持了同时两种。此外,所有的80x86处理器还引入了一个local APIC,Each local APIC has 32-bit registers, an internal clock; a local timer device,还包括了两条额外的IRQ line,用于local APIC interrupts,local APIC与 external I/O APIC 相连,形成了一个多 APIC 系统,如下图所示:

IO APIC包括了24条IRQ line,a 24-entry Interrupt Redirection Table, programmable registers, and a message unit for sending and receiving APIC messages over the APIC bus.8259A依赖于pin number来表示中断的优先级,IO APIC稍微高级了点,each entry in the Redirection Table can be individually programmed to indicate the interrupt vector and priority。 The information in the Redirection Table is used to translate each external IRQ signal into a message to one or more local APIC units via the APIC bus。
来自外部设备的中断以如下两种方式在CPU之间分发:
-
Static distribution
根据Redirection Table entry将IRQ signal转发给local APIC,可以是单个CPU、多个CPU、所有CPU(广播模式)
-
Dynamic distribution
这块描述比较复杂,需要的直接看书。
除了在处理器之间分发中断,multi-APIC 还允许CPU生成interprocessor interrupts,当CPU期望发送一个中断给其他CPU时,it stores the interrupt vector and the identifier of the target’s local APIC in the Interrupt Command Register (ICR) of its own local APIC.A message is then sent via the APIC bus to the target’s local APIC, which therefore issues a corresponding interrupt to its own CPU.Interprocessor interrupts (in short, IPIs) are a crucial component of the SMP architecture. They are actively used by Linux to exchange messages among CPUs .
Exceptions
x86有20个不同的exception,内核必须对每种异常设置不同的handler,对于一些异常,CPU还会在执行handler之前将hardware error code 压入到内核栈。x86的各种异常可以参考:https://www.sandpile.org/x86/except.htm
每种异常都有一种与之相对应的handler,它通常给造成这些异常的进程发送signal:

Interrupt Descriptor Table
x86 CPU包含一个system table称为Interrupt Descriptor Table (IDT),将exception vector与它相对应的exception handler关联起来,IDT必须在内核开启中断以前就初始化完毕。IDT的形式上和GDT、LDT类似,一共可以存放256个IDT,每个8字节,所以需要2048字节存放IDT。
IDT entry有三种类型:
- Task gate: Includes the TSS selector of the process that must replace the current one when an interrupt signal occurs.
- Interrupt gate:包含了Segment Selector and the offset,当执行Interrupt gate时 CPU 的 IF 标志将会被设置,因此屏蔽了将来的可屏蔽中断。
- Trap gate:和前者类似,只不过不会设置IF标志。
Linux使用Interrupt gate来处理interrupt,Trap gate来处理exception,回顾一下两者的区别,interrupt来自于CPU内部,exception来自于外部设备。
Hardware Handling of Interrupts and Exceptions
接下来描述CPU是如何处理中断和异常的。cs:ip总是保存着下一条将要执行的命令,在执行该指令之前,CPU确认是否已经发生了中断,如果是:
-
读取中断号(vector i,0≤i ≤255)
-
从IDT中读取第i个entry,IDT的地址位于idtr寄存器
-
从gdtr寄存器读取GDT的地址,根据IDT的selector获取到它的Segment Descriptor
-
上一步获取到了Segment Descriptor,接下来进行权限校验,如果CPL(此时CPU所执行的特权级)小于DPL(目标Descriptor的特权级),抛出一个 General protection 。因为中断处理函数所处的特权级不能低于造成异常的程序的特权级。
-
确认是否发生了特权级切换,即CPL不同于目的的DPL,这里说的是用户态切换到了内核态,这里涉及到的栈切换,需要切换到内核栈:
-
从tr寄存器读取TSS segment的地址
-
从TSS中加载内核栈的内容到
ss:esp寄存器,完成了内核栈的切换 -
在新的栈中,CPU将原先的
ss:esp的内容(用户栈)压入了内核栈。这部分内容可以查看文首提到的手册的209页。在后文附上相关的截图Note: 内核和用户程序同处于同一片虚拟地址空间,将用户栈地址压入到了内核栈,内核栈可以以此来获取用户栈上的内容
-
-
If a fault has occurred, it loads cs and eip with the logical address of the instruction that caused the exception so that it can be executed again
-
保存eflags,cs,ip寄存器到内核栈
-
如果该异常带有hardware error code,也压入到栈
-
将
cs:ip设置为Segment Selector和Gate Descriptor里边的offset,拼接到了中断处理函数的入口地址。
接下来就是等待中断被处理,最后中断处理函数调用了iret指令返回到了用户进程,它会执行如下的操作来复原上下文:
- 将之前压入到内核栈的cs, eip, and eflags 复原,如果压入了error code,那么需要在iret之前弹出
- 确认handler的CPL是否等同于cs的低2bit,如果是的话表示位于同一特权级,如果是的话iret就此结束
- 从内核栈中加载用户栈的
ss:esp
这里还没有涉及到通用寄存器的保存,后文会提到这些内容。

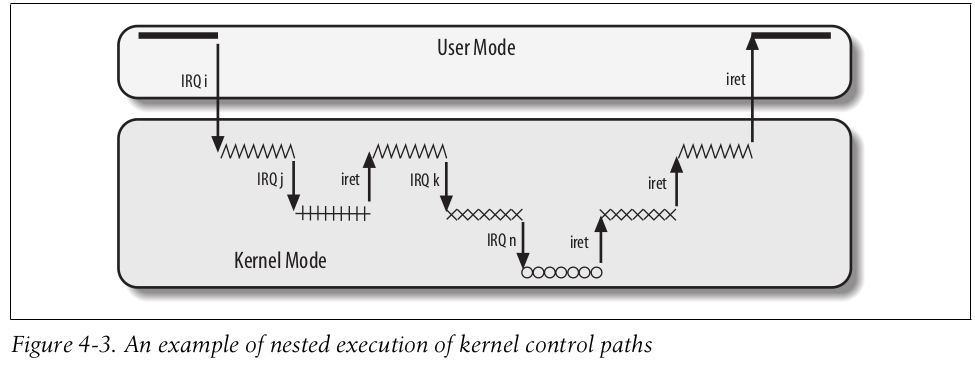
Nested Execution
任何中断和异常的执行都会执行一段 kernel control path,内核替代当前进程去执行,然而这是可嵌套的,一个中断处理函数可以被另一个中断处理函数打断,所以中断处理函数在恢复上下文到时候,必须确认当前嵌套的深度是否大于1,如果是就回到被中断的中断处理函数继续执行,此时还是位于内核空间。下图是一个中断嵌套的示意图:
Initializing the Interrupt Descriptor Table
在内核开启中断之前,必须初始化好IDT的内容。用户程序可以通过使用int指令发起一个中断,因此有一些中断必须设置特权级为0,禁止用户程序调用,对于那些允许用户调用的中断,特权级设置为3。IDT被存在idt_table数组中,包含了256个entry,idt_table的地址将会被写入到idtr寄存器当中。setup_idt()是一段汇编代码,它就是将256个entry都初始化为相同的interrupt gate,代码如下:
assemblysetup_idt: # 将ignore_int的地址写入到edx lea ignore_int, %edx movl $(__KERNEL_CS << 16), %eax movw %dx, %ax /* selector = 0x0010 = cs */ movw $0x8e00, %dx /* interrupt gate, dpl=0, present */ # 将 idt_table的地址写入到edi lea idt_table, %edi # ecx=256,将用于控制循环次数 mov $256, %ecx rp_sidt: movl %eax, (%edi) movl %edx, 4(%edi) addl $8, %edi # 递减循环条件 dec %ecx # 循环执行,直到ecx为0 jne rp_sidt ret
ignore_int是一个汇编代码(源代码位于:arch/i386/kernel/head.S),它会执行:
- 保存所有通用寄存器的值到栈(应该是内核栈)
- 调用
printk()输出一行Unknown interrupt” - 恢复所有寄存器的值
- 执行iret指令,回到被中断的程序
**不过ignore_int()**永远不会执行,因为内核会在接下来将各个中断替换为真正的各种中断处理函数,下面是部分函数调用的示例:

这些中断处理函数总体来说可以概括为三个步骤:
- 保存大部分寄存器的内容到内核栈
- 执行由C语言编写的处理函数
- 调用
ret_from_exception从处理函数退出。
在接下来的内容分析exception的处理过程。
Exception Handling
我们以handler_name表示一个处理函数,每个中断处理函数的基本形式为:
assemblyhandler_name: pushl $0 /* only for some exceptions */ pushl $do_handler_name jmp error_code
有一些中断不会压入错误码,所以为了保证栈的统一性,将不压入错误码的中断处理函数人为的压入0。然后将由C语言编写的中断处理函数压入到内核栈,然后跳转到jmp error_code,它负责保存用户态的通用寄存器的内容到内核栈,执行cld指令,将error code从esp+36位置复制到edx,并且在该位置写入-1,用来区分0x80(用于实现系统调用的中断)和其他中断。
下面是除0异常的代码,位于arch/i386/kernel/entry.S:
assemblyENTRY(divide_error) pushl $0 # no error code pushl $do_divide_error ALIGN error_code: pushl %ds pushl %eax xorl %eax, %eax pushl %ebp pushl %edi pushl %esi pushl %edx decl %eax # eax = -1 pushl %ecx pushl %ebx cld movl %es, %ecx movl ES(%esp), %edi # get the function address movl ORIG_EAX(%esp), %edx # get the error code movl %eax, ORIG_EAX(%esp) movl %ecx, ES(%esp) movl $(__USER_DS), %ecx movl %ecx, %ds movl %ecx, %es movl %esp,%eax # pt_regs pointer call *%edi # 跳转到中断处理函数 jmp ret_from_exception
Entering and Leaving the Exception Handler
do_divide_error这些函数名都是由一个宏生成的,这个宏的关键调用了do_trap函数。
c#define DO_ERROR(trapnr, signr, str, name) \
fastcall void do_##name(struct pt_regs * regs, long error_code) \
{ \
if (notify_die(DIE_TRAP, str, regs, error_code, trapnr, signr) \
== NOTIFY_STOP) \
return; \
do_trap(trapnr, signr, str, 0, regs, error_code, NULL); \
}
它将error code和中断号存在了当前进程的成员变量中:
ccurrent->thread.error_code = error_code;
current->thread.trap_no = vector; // 有点不明白,哪里将中断号保存到了内核栈?
force_sig(sig_number, current);
然后调用force_sig发送一个信号给当前进程,进程的signal handler将会负责对这个信号待处理。do_trap()结束以后,调用jmp ret_from_exception进入到ret_from_exception()函数。
因此从代码来看,大部分的exeception都是由进程本身来处理。**疑问:**那么默认的exception handler是怎么样的呢?换而言之,默认的信号处理方式什么样的?
Interrupt Handling
最开始我们强调过内核需要保证中断的响应尽可能快,前面我们将exception handler以信号的形式交给了造成exception的进程,而不是在内核中处理exception,因此处理的过程是相当快的。这一点对于中断不再适用,当中断发生时,因为与中断相关的进程可能已经被挂起,此时可能一个与中断完全无关的进程正在使用CPU,因此发送给它信号是没有意义的。
中断的处理取决于中断的类型,主要是三种:I/O interrupts,Timer interrupts,Interprocessor interrupts
- I/O interrupts: IO设备的中断
- Timer interrupts:时钟中断
- Interprocessor interrupts:CPU间通信中断
I/O Interrupt Handling
通常来说,一个IO interrupt handler需要足够的灵活进而能够处理多种设备。PCI bus architecture中,多种设备可能共享一条IRQ line,比如说下表中IRQ 11被USB和声卡同时所用:
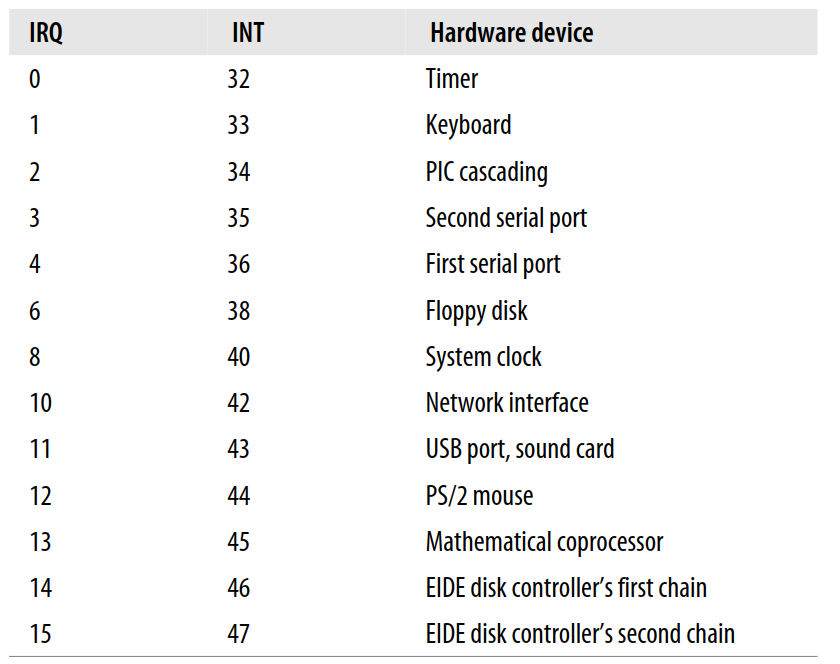
为了面对这种情况,Interrupt handler 必须能够灵活性可以通过两个方面来实现:
-
IRQ sharing
一个Interrupt handler同时实现多个interrupt service routines (ISRs),每个ISR对应一种实际的物理设备,因此ISR也需要在执行的过程中确认此时的中断是不是它所关注的,否则的话传递给下一个ISR。
-
IRQ dynamic allocation
动态的分享IRQ line,比如说 floppy IRQ line 只有在需要访问floopy的的时候才分配,所以IRQ line不能被多种设备同时使用。
并不是所有的中断都十分紧急,不太紧急的工作可以适当的延迟处理,当中断函数再运行的时候,对应的IRQ line发送的信号会被暂时的忽略,另外一个很重要的目的是中断处理函数的在执行的时候,此时的正在运行的进程(current进程)必须是出于TASK_RUNNING状态,否则系统就被freeze了,Linux将中断分为是哪个部分:
- Critical: Actions such as acknowledging an interrupt to the PIC, reprogramming the PIC or the device controller, or updating data structures accessed by both the device and the processor.这些工作需要尽快的执行(并且暂时屏蔽了中断)
- Noncritical: Actions such as updating data structures that are accessed only by the processor (for instance, reading the scan code after a keyboard key has been pushed). These actions can also finish quickly, so they are executed by the interrupt handler immediately, with the interrupts enabled
- Noncritical deferrable: 可以将这部分工作延后,比如说处理IO。Noncritical 将由Softirqs and Tasklets最终处理。
不管什么样的情况触发了中断,中断处理函数基本需要做:
- 将IRQ value和通用寄存器的内容保存到内核栈
- 发送一个acknowledgment给PIC表明此时正在处理IRQ,你可以进一步发送中断了
- 执行与共享IRQ的ISR
- 调用
ret_from_intr()结束中断处理函数
Interrupt vectors
硬件中断在中断向量表中可用的范围是32-238(32前一部分给CPU本身使用,如除0错误等),Linux 将128 用作系统调用的实现,一个 IBM-compatible PC architecture还有其他限制:
- 时钟中断必须处于 IRQ 0
- 8259A 从片必须接到 IRQ 2(不过没啥用了,老掉牙的 8259 A)
其他限制不一一列举。下图是中断向量表的分布:

IRQ data structures
先学习下中断处理的数据结构-irq_desc_t,内核维护了一个数组irq_desc,一共有NR_IRQS个(224)元素,每个下标对应着一个irq_desc_t,这个结构体源码位于include/linux/irq.h,成员变量包括:

在前一小节,我们说过内核最开始调用了setup_idt()来进行一些没用的工作,初始化了所有的中断,内核在初始化阶段调用init_IRQ()来将这些没有的中断处理函数进行替换为真正的处理函数,核心代码:
cfor (i = 0; i < NR_IRQS; i++)
if (i+32 != 128)
set_intr_gate(i+32,interrupt[i]);
i+32是因为中断是从32号开始的,interrupt[n]是IRQ n的处理函数的地址,注意,我们没有处理128,这是留给系统调用的。后面还有很多将APIC初始化以及对8259A的兼容工作,太繁琐,略。
Saving the registers for the interrupt handler
当进入到一个中断处理函数,首先要做的是保护各种寄存器的值。interrupt数组里面是各个中断处理函数的地址,而interrupt在arch/i386/kernel/entry.S当中被初始化,源码如下:
c.data
ENTRY(interrupt)
.text
vector=0
ENTRY(irq_entries_start)
.rept NR_IRQS
ALIGN
1: pushl $vector-256
jmp common_interrupt
.data
.long 1b
.text
vector=vector+1
.endr
这里用了一些预处理指令.rept NR_IRQS重复了224(NR_IRQS的值,该值如果是8259A芯片那么就是16)次,所以每个中断处理函数的起始语句都是:
assemblypushl $n-256 jmp common_interrupt
汇编语句将IRQ line - 256的值保存到了内核栈,因此内核看到的IRQ number都是负数的,因为将正数预留给系统调用,然后执行comm_interrupt:
assemblycommon_interrupt: SAVE_ALL movl %esp,%eax call do_IRQ jmp ret_from_intr
SAVE_ALL的作用是保存所有通用寄存器,除了eflags,cs,eip,ss,esp寄存器会被CPU自动压入到内核栈,SAVE_ALL的源码也在arch/i386/kernel/entry.S,就不贴了。接下来将栈指针保存到eax寄存器,调用do_IRQ函数,源码位于arch/i386/kernel/irq.c:
c_ _attribute_ _((regparm(3))) unsigned int do_IRQ(struct pt_regs *regs)
The do_IRQ( ) function
(regparm(3))表示从eax获取参数,而此时栈指针指向的是通用寄存器,因此构造好了struct pt_regs,do_IRQ()首先执行了irq_enter(),递增了当前进程的preempt_count,它表示的是中断嵌套的次数,源码在include/linux/hardirq.h:
c#define irq_enter() \
do { \
account_system_vtime(current); \
add_preempt_count(HARDIRQ_OFFSET); \
} while (0)
然后调用了__do_IRQ()函数,源码位于:kernel/irq/handle.c,__do_IRQ()琐碎细节比较多,先暂时略过,其中关键的是调用handle_IRQ_event()来处理各种中断,在前文我们说过存在IRQ sharing的内容,所以调用ISR( interrupt service routines)是一个循环的过程:
cfastcall int handle_IRQ_event(unsigned int irq, struct pt_regs *regs,
struct irqaction *action)
{
int ret, retval = 0, status = 0;
if (!(action->flags & SA_INTERRUPT))
local_irq_enable();
do {
// 遍历所有ISR函数
ret = action->handler(irq, action->dev_id, regs);
if (ret == IRQ_HANDLED)
status |= action->flags;
retval |= ret;
action = action->next;
} while (action);
if (status & SA_SAMPLE_RANDOM)
add_interrupt_randomness(irq);
local_irq_disable();
return retval;
}
每个ISR的参数都是一样的:
- irq: IRQ number
- dev_id: The device identifier
- regs: 硬件的上下文,主要由三个部分组成:
- 前9个通用寄存器,由
SAVE_ALL压入 - 第十个是原先的eax寄存器的值,代表的是IRQ number
- 剩下的寄存器内容由CPU自己压入
- 前9个通用寄存器,由
剩下还有很多实现IRQ sharing 和 dynamic IRQ 的内容,略。
疑问: 具体每个ISR函数在做什么?从哪里找到呢?
Softirqs and Tasklets
处理中断需要尽可能快,将复杂的操作适当延迟,这使得内核响应中断的时间相当短,在很多time-critical 应用中这一点是十分重要的。Linux 2.6 使用了deferrable functions(softirqs and tasklets),实际上通过一些work queue来执行。softirq和tasklet是紧密耦合的,因为tasklet的实现基于softirq。softirq可以在多个CPU之间并发运行,所以必须用spin lock保护起来,而同一种类型的tasklet是串行的,不同类型的tasklet可以在多个CPU之间并发执行。
Note: 这里的是否并发指的是存放sotifrq的数组不是一个per cpu 数组,而tasklet是一个per-cpu数组。
Softirqs
Linux 2.6 使用了没几个softirq,只用了6个softirq:

它的index表示的是优先级,越小越大,因为softirq都是从index 0开始执行的。
Data structures used for softirqs
softirq都存放在softirq_vec的数组里,虽然它的长度是32,实际上存了6个,每个元素类型为srtuct softirq_action,源码在include/linux/interrupt.h,如下:
cstruct softirq_action
{
void (*action)(struct softirq_action *);
void *data;
};
- action:表示softirq 要执行的函数
- data:softirq函数所执行时可能需要的变量
Note:
现在的内核拥有的softirq数量已经比这个多了,5.x版本的内核可以看到softirq的数量是10个,源码地址。
每个CPU都会有一个ksoftirq进程(注意不要将其于softirq弄混),每个CPU上的softirq的信息可以从/proc/softirqs看到,下面是一个示例:
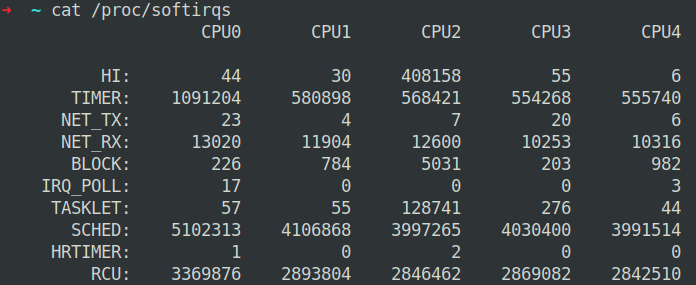
扩展文档: https://0xax.gitbooks.io/linux-insides/content/Interrupts/linux-interrupts-9.html
另一个重要的字段就是thread_info里面的preempt_count,它由三个部分组成:

第一部分表示disable了多少次内核抢占,0表示没有发生任何内核抢占。第二部分表示how many levels deep the disabling of deferrable functions,第三部分表示number of nested interrupt handlers on the local CPU,这部分值由irq_enter()增加,由irq_exit()递减。preempt_count是相当有用的,内核抢占会在各种地方被打开和关闭,所以为了确认当前进程是否可以被抢占,内核只需要查阅preempt_count即可。最后一个实现softirq的data structure 是一个per-CPU 32 bit的bit mask,它是irq_cpustat_t的_ _softirq_pending变量。
Handling softirqs
open_softirq()函数用于softirq的初始化,它接收三个参数,源码位于kernel/softirq.c:
cvoid open_softirq(int nr, void (*action)(struct softirq_action*), void *data)
{
softirq_vec[nr].data = data;
softirq_vec[nr].action = action;
}
nr是所要初始化的softirq index,action是softirq要执行的函数,data是可能被用到的数据。下面是两个和网络相关的softirq的初始化,源码位于net/core/dev.c:
c// NET_TX_SOFTIRQ 发送所用的softirq,调用的函数是 net_tx_action
open_softirq(NET_TX_SOFTIRQ, net_tx_action, NULL);
open_softirq(NET_RX_SOFTIRQ, net_rx_action, NULL);
softirq被函数raise_softirq()所激活(不过源码中看到的更多是raise_softirq_irqoff函数),它以nr作为参数执行下面的操作:
- 执行
local_irq_save()保存当前的IF flag,并且关闭中断 - 在当前CPU的bit mask中,把当前softirq所对应的bit设置为1,表明当前softirq已经处于pending状态
- If in_interrupt() yields the value 1, it jumps to step 5. This situation indicates either that raise_softirq() has been invoked in interrupt context, or that the softirqs are currently disabled
- 否则的话,调用
wakeup_softirqd()唤醒当前CPU的ksoftirqd函数 - 执行
local_irq_restore()恢复IF flag
softirq被设置为pending以后,需要被定期的确认(不然谁来处理?),下面是一些重要的checkpoint:
-
当内核调用了
local_bh_enable()函数来enable 了softirq -
当
do_IRQ()函数结束了中断处理函数,然后调用了irq_exit()宏 疑问 既然中断处理尽可能快,那么在irq_exit()的时候调用softirq是不是可能带来一些开销?从源码注释来看,开发者似乎也考虑到了这个问题,Process softirqs if needed and possible应该说明他们认为这里处理softirq是可以忍受的开销吧。c/* * Exit an interrupt context. Process softirqs if needed and possible: */ void irq_exit(void) { account_system_vtime(current); sub_preempt_count(IRQ_EXIT_OFFSET); if (!in_interrupt() && local_softirq_pending()) invoke_softirq(); preempt_enable_no_resched(); } -
如果系统使用了 IO APIC,调用了
smp_apic_timer_interrupt() -
调用了
CALL_FUNCTION_VECTOR() -
内核线程
ksoftirqd被唤醒
这样看来softirq的基本逻辑是,使用一个bit mask表示此时需要有工作被处理,然后再各种地方确认bit mask的状态,调用softirq对应的函数
The do_softirq() function
当前面提到的checkpoint发现了有处于pending状态的softirq,就调用do_softirq()函数,流程如下:
- 如果
in_interrupt()返回1,表示已经处于调用do_softirq()或者softirq已经被disable local_irq_save()保存此时的IF flag- 调用
_ _do_softirq(),该函数是中断处理的核心部分 - 调用
local_irq_restore()恢复IF flag
原文还有涉及到 4KB 栈,略。
The __do_softirq() function
_ _do_softirq()函数根据bit mask来处理运行deferrable functions ,因为在执行这些函数的时候新的softirq也处于pending,所以___do_softirq()内部会有一个循环,确认所有pending的softirq都会被处理。如果在这个循环结束后又有pending的softirq,最终将会被ksoftirqd内核进程所处理。源码位于kernel/softirq.c,如下,源码还是比较直观的,所以集合代码来解释。
casmlinkage void __do_softirq(void)
{
struct softirq_action *h;
__u32 pending;
// softirq 执行的循环次数
int max_restart = MAX_SOFTIRQ_RESTART;
int cpu;
// 获取当前CPU的softriq bit mask
pending = local_softirq_pending();
local_bh_disable();
cpu = smp_processor_id();
restart:
/* Reset the pending bitmask before enabling irqs */
// 将当前CPU的softirq的 bit mask清空,让新的softirq可以处理
local_softirq_pending() = 0;
local_irq_enable();
h = softirq_vec;
// 根据 bitmask 的某bit是否1来循环处理softirq
do {
if (pending & 1) {
h->action(h);
rcu_bh_qsctr_inc(cpu);
}
h++;
// 右移一个bit,表示当前softirq已经被处理,因为变量pending是一个bitmask
pending >>= 1;
} while (pending);
local_irq_disable();
pending = local_softirq_pending();
// 如果在处理softirq期间有新的softirq处于pending状态,跳转到restart重新执行前面的过程
if (pending && --max_restart)
goto restart;
// 如果执行完了还有softirq没有被处理,尝试唤醒ksoftirqd内核进程来处理
if (pending)
wakeup_softirqd();
__local_bh_enable();
}
The ksoftirqd kernel threads
每个CPU都有一个自己的ksoftirq内核进程,如下图,后面的需要代表的是CPU的序号。
每个ksoftirq函数当中核心的部分是一个循环,代码位于kernel/softirq.c:
cset_current_state(TASK_INTERRUPTIBLE);
while (!kthread_should_stop()) {
if (!local_softirq_pending())
schedule();
__set_current_state(TASK_RUNNING);
while (local_softirq_pending()) {
/* Preempt disable stops cpu going offline.
If already offline, we'll be on wrong CPU:
don't process */
preempt_disable();
if (cpu_is_offline((long)__bind_cpu))
goto wait_to_die;
do_softirq();
preempt_enable();
cond_resched();
}
set_current_state(TASK_INTERRUPTIBLE);
}
没有工作时,ksoftirqd处于TASK_INTERRUPTIBLE状态,被唤醒以后处于TASK_RUNNING,接下来调用do_softirq()执行softirq。如果没有pending的softirq,调用schedule()将进程切换出去。
疑问: 调用cond_resched()的逻辑是什么?
Tasklets
tasklet是实现IO驱动(driver)的deferrable functions更好的方法。tasklet基于两种类型的softirq实现的:HI_SOFTIRQ和TASKLET_SOFTIRQ,多个tasklet可以和同一类型的softirq关联,每种tasklet所执行的函数不同的。HI_SOFTIRQ和TASKLET_SOFTIRQ两种类型的tasklet没有什么本质区别,除了HI_SOFTIRQ需要在TASKLET_SOFTIRQ之前执行。
tasklet和high-priority tasklets分别存在tasklet_vec和tasklet_hi_vec数组中,每个数组包含了NR_CPUS个tasklet_head一个tasklet descriptors的链表,它的结构如下:

state字段有两种取值:
- TASKLET_STATE_SCHED:tasklet处于pending,表面可以执行tasklet了。这同样意味着tasklet descriptor被插入到了
tasklet_vec或者是tasklet_hi_vec - TASKLET_STATE_RUN:表明tasklet正在被处理
为了激活一个tasklet,调用tasklet_schedule()或者是tasklet_hi_schedule(),这取决于我们所新建的tasklet是否对优先级有要求,这两个函数十分相似,流程如下:
- 检查TASKLET_STATE_SCHED来确认tasklet是否已经被调度执行
- 调用
local_irq_save()来保存IF flag - 将新添加的tasklet追加到当前CPU的
tasklet_vec的头部(链表的插入操作) raise_softirq_irqoff()调用来将softirq 设置为pending,表明此时有softirq需要被处理- 调用
local_irq_restore()恢复IF flag
接下来再描述tasklet是怎么执行的,与tasklet相关的softirq 源码如下:
cvoid __init softirq_init(void)
{
open_softirq(TASKLET_SOFTIRQ, tasklet_action, NULL);
open_softirq(HI_SOFTIRQ, tasklet_hi_action, NULL);
}
tasklet_action和tasklet_hi_action所做的事情差不多,结合源码也十分直观,下面以tasklet_action为例:
cstatic void tasklet_action(struct softirq_action *a)
{
struct tasklet_struct *list;
local_irq_disable();
// 获取当前CPU的tasklet链表
list = __get_cpu_var(tasklet_vec).list;
// 将当前CPU的tasklet链表设置为空
__get_cpu_var(tasklet_vec).list = NULL;
// 开启中断
local_irq_enable();
// 开始遍历所有的tasklet
while (list) {
struct tasklet_struct *t = list;
list = list->next;
// 这部分有些没理解
if (tasklet_trylock(t)) {
if (!atomic_read(&t->count)) {
if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
BUG();
// 执行tasklet的函数
t->func(t->data);
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
local_irq_disable();
// 更新链表,将已经更新的tasklet从链表中移除
t->next = __get_cpu_var(tasklet_vec).list;
__get_cpu_var(tasklet_vec).list = t;
// 为什么还需要在raise softirq ?
__raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_enable();
}
}
理一下tasklet的逻辑,调用tasklet_init()初始化一个tasklet(快速翻阅内核代码,tasklet基本都是被用于驱动当中),再需要的时候将调用tasklet_schedule()将tasklet加入到tasklet_vec数组,等待被执行。task_schedule()调用raise_softirq_irqoff()将tasklet对应的softirq设置为pending状态,再按照先前描述的流程去执行softirq的函数进而再去执行tasklet的函数,下面是__tasklet_schedule()源码,位于kernel/softirq.c:
cvoid fastcall __tasklet_schedule(struct tasklet_struct *t)
{
unsigned long flags;
local_irq_save(flags);
t->next = __get_cpu_var(tasklet_vec).list;
__get_cpu_var(tasklet_vec).list = t;
// TASKLET_SOFTIRQ 设置为pending,唤醒 softirq 进程
raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_restore(flags);
}
Work queue
worker queue从 Linux 2.6 引入用于替代Linux 2.4 当中的 task queue,worker queue 允许一些内核函数被延迟执行,最终被内核站进程,称为worker threads执行。work queue和之前提到的tasklet和softirq相似,从功能上来说它们都允许延迟执行,区别是:worker queue允许调用函数的阻塞。
Work queue data structures
work queue关键的数据结构是struct workqueue_struct,源码位于kernel/workqueue.c:
cstruct workqueue_struct {
struct cpu_workqueue_struct cpu_wq[NR_CPUS];
const char *name;
struct list_head list; /* Empty if single thread */
};
- name: work queue的名字
- cpu_wq: 一个数组,长度为节点CPU的数量
- list: 不清楚作用,感觉和线程相关
struct cpu_workqueue_struct的结构如下图:

worklist是双向链表,是出于pending状态的函数(等待被work queue 线程执行的函数),相对应的结构是work_struct,它的成员变量:

Work queue functions
调用create_workqueue("foo")将会创建一个work queue,然后创建了n(n取决于CPU数量)内核进程,形如foo/0,foo/1,后面的数字表示的是CPU的index。create_singlethread_workqueue()创建只有一个内核进程的work queue,destroy_workqueue()销毁work queue。当系统启动以后,
queue_work()插入一个函数到work queue,基本流程如下,源码位于kernel/workqueue.c:
- 确认被插入的函数是否已经是处于 pending 状态
- 将函数设置为pending状态
- 如果有work thread处于当前CPU的
more_workwait queue 并且处于休眠状态,唤醒它
queue_delayed_work()的作用和queue_work()差不多,只不过它在执行pending function之前会进行一定的时间的delay。有时候内核需要等待所有的pending function都执行完毕,flush_workqueue()就是用来干这事儿的,它会阻塞调用进程直到所有pending function执行完毕,不过并不过包括调用flush_workqueue()之后插入的函数
The predefined work queue
大部分情况下,为了执行一个需要延迟执行的函数而创建work thread没啥必要,因此内核事先已经定义了一些 work queue称为 events,它没有任何奇特的地方,该咋用咋用。除此以外,还有一个 kblockd work queue,它被用于块设备层(block device layer),直接使用 ps 命令可以看到各种work queue进程:

Note:
ps 查看进程时,包含方括号的进程(僵尸进程会以[defunct]结尾)就是内核进程,其他的则是普通进程。
Returning from Interrupts and Exceptions
回想前面的汇编代码,中断处理和异常处理(下文统称为中断)最后都分别调用了ret_from_intr()和ret_from_exception()结束两者调用,在支持抢占的内核中,ret_from_exception()会立即关闭中断。从中断返回可能有多种情况:
- Number of kernel control paths being concurrently executed 如果是1,这表示中断不是嵌套发生的,直接回到user space
- Pending process switch requests 如果存在pending的switch requests,那么需要进程切换
- Pending signals 如果有信号发送给了当前进程,必须被处理
- Single-step mode debug相关,略
- Virtual-8086 mode 虚拟化相关,略
A few flags are used to keep track of pending process switch requests, of pending signals, and of single step execution; they are stored in the flags field of the thread_info descriptor. 如下:

The entry points
The ret_from_intr() 和 ret_from_exception()基本等价,源码位于arch/i386/kernel/entry.S(实际代码和书上描述的有些不一样):
assemblyret_from_exception: cli ; missing if kernel preemption is not supported ret_from_intr: movl $-8192, %ebp ; -4096 if multiple Kernel Mode stacks are used andl %esp, %ebp movl 0x30(%esp), %eax movb 0x2c(%esp), %al testl $0x00020003, %eax jnz resume_userspace jpm resume_kernel
在进程一章说过内核栈一般是8KB,而且thread_info位于内核栈的底部,可以使用esp寄存器减去8192获得当前进程的信息,这就是头两行的内容。如何判断此时中断是发生在用户态还是内核态?中断发生时CPU会将cs和eflags压入到内核栈,所以从栈上获取cs寄存器的值,根据cs寄存器上的特权级来判断是否处于内核态,然后分别跳转到resume_userspace和resume_kernel恢复之前的上下文。
Resuming a kernel control path
resume_kernel的作用是恢复被中断的内核代码的上下文,代码如下
assemblyresume_kernel: cli ; these three instructions are cmpl $0, 0x14(%ebp) ; missing if kernel preemption jz need_resched ; is not supported restore_all: popl %ebx popl %ecx popl %edx popl %esi popl %edi popl %ebp popl %eax popl %ds popl %es addl $4, %esp ; 跳过 error code iret
如果当前进程的preempt_count()为0,跳转到need_resched()(表示该进程可以被抢占),否则从栈上获取通用寄存器,跳过error code,最后调用iret指令,它会从栈上获取cs:ip,恢复执行之前被中断的内核代码。
**疑问:**对于 preempt_count 的作用还不太明确,后面学习抢占的细节内容。
Checking for kernel preemption
当下面这段代码被执行的时候,说明不存在未完成的kernel control paths
assemblyneed_resched: movl 0x8(%ebp), %ecx testb $(1<<TIF_NEED_RESCHED), %cl jz restore_all testl $0x00000200,0x30(%esp) jz restore_all call preempt_schedule_irq jmp need_resched
判断当前进程的TIF_NEED_RESCHED flag是否为0,为0表示不需要切换进程,跳转到restore_all回到当前进程继续执行,否则执行preempt_schedule_irq(),接着再去调用schedule()切换进程。
Resuming a User Mode program
如果被被中断的进程是用户进程,那么开始恢复用户进程的上下文:
assemblyresume_userspace: cli movl 0x8(%ebp), %ecx andl $0x0000ff6e, %ecx je restore_all jmp work_pending
If no flag except TIF_SYSCALL_TRACE, TIF_SYSCALL_AUDIT, or TIF_SINGLESTEP is set, nothing remains to be done: a jump is made to the restore_all label, thus resuming the User Mode program
Checking for rescheduling
如果thread_info当中的一些flag(上一小节的flag)被设置,那么还有其他的事情要做:
assemblywork_pending: testb $(1<<TIF_NEED_RESCHED), %cl jz work_notifysig work_resched: call schedule cli jmp resume_userspace
如果有 process switch request 处于 pending,调用schedule()切换进程执行,当它(被换出去的进程)重新开始执行后,调用resume_userspace回到user space。
End
总体来说结束了中断和异常相关的内容,囫囵吞枣地学了一遍。
本文作者:strickland
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!