目录
tc(traffic control)是用于流量控制的,不过其命令相当复杂,涉及到的名词和概念不少,无奈也没看到特别好的文章。带着问题去学习。假设我们是内核的开发者,会以什么样的数据结构去设计流量控制。首先想到的想法应该是用队列,进一步的考虑队列应该有优先级,优先级高的队列内的packet先出去,比如说ssh的实时交互性数据应该比wget下载大文件的优先级更高。还需要实现限流,这主要是避免发送太多的流量导致链路被冲垮,也避免网卡流量被某一进程独占其他进程无法分配到网络带宽。当然tc所支持的功能更加复杂, 下面是 tc 的基本功能,来源-man page:
- shaping: 对出口流量进行限速,它的原理是packet在被正式从output queue出去之前加入一些延迟,这样来流量低于限定的速度。
- scheduling: 对packet进行调度,就像前面举例的 ssh 的packet应该比其他的packet先出去。
- policing: shaping的作用对象是出去的流量,而policing作用的对象则是进入的流量的限速。
- dropping: 对于超过预设值的流量都会被直接丢弃,dropping可以发生在ingress和egress。
而tc则使用下面这些基本的组件实现了上面所描述的基本功能,:
- qdisc(queueing discipline): 作用就是队列,tc当中有相当多各种队列(qdisc),最基本的如pfifo就是以packet为基本单位的队列,pfifo没有任何其他策略packet以FIFO的形式出入队列。进一步地qdisc,分为两大类,分别是classful qdisc 和 classless qdisc两者的唯一区别是能否包含qidsc,classful qdisc可以包含多个classes,其内部还可以包含多个qidsc,形成一种层次结构。有两个默认的qidsc: root和 ingress,虽然它们被称为qdisc 不过它们并不是真正的qdisc,它们实际代表的是流量控制所发生的地方, root 代表 egress (output),ingress 代表入口(input)。出去的流量需要经过绑定在root上的(以及它下属的)qdisc,进入的流量需要经过ingress(以及它下属的)qdisc。
- filters: 既然一个qdisc可以包含多个class,那么packet到底进入到哪一个packet就需要以来预设的条件进行判决,我们使用filter来设置选择的条件。filter还会与policer 搭配使用。policer的使用场景是对流量限速的情况,假如超过了预设的带宽值就根据 policer 预设的 action 处理。
- naming: 所有的qdisc,class,filter都要以有一个唯一的标识符。前面说过一个qdisc 还可以包含多个qidsc,那么我们将qdisc 加入到某个现有的qdisc(parent qdisc)就需要使用该标识符来指定。标识符由两个部分组成形如
major:minor。对于 qdisc,该标识符被成为 handle,形式一般为handle xxx:,minor number 都不设置。对于 root ,handle 一般都为handle 1:。同一个 qdisc 下的classes的 major number 都相同,它们之间以 minor number区分,class 的标识符称为classid。
Note: 我一开始无法彻底理清 qdisc 和 class 的关系。可以将 class 认为是媒介,对于 classful qdisc 如果需要加入子队列就需要先创建 class,然后将子队列加入到class里边。也就是说 qdisc 本身不能存在层级关系,这依赖于 class ,不过class本身也是可以具有qdisc的。
到这未知,上述概念都十分模糊,先使用几个简单的例子来对tc有个直观的感受。我们以 PRIO 作为示例,它是一个多队列的qdisc,每个qdisc有不同的优先级。使用如下命令创建一个 PRIO qidsc,在稍后我们会在对它进行描述:
shell$ sudo tc qdisc add dev eth0 root prio 3
表示在设备eth0的入口(egress)创建prio qdisc,包含三个bands,得到的结果如下图所示:

也可以使用命令查看:
shell$ sudo tc class show dev eth0
class prio 1:1 parent 1:
class prio 1:2 parent 1:
class prio 1:3 parent 1:
1:1,1:2,1:3分别表示三个qdisc的标识符,与前面描述的那样,major number 表示它们的 parent qdisc,也就是 root qdisc。这三个 qdisc 内的数据在出队的时候从 band0(prio 1:1)先出去,按照handle升序进行。默认的PRIO的子队列都是FIFO的,可以对FIFO进行替换,换成其他qdisc,使用如下命令替换为了tbf队列:
shell$ sudo tc qdisc add dev eth0 parent 1:1 handle 20: tbf rate 100mbit limit 100mbit burst 100mbit
命令表示往class 1:1加入tbf qdisc,参数为rate 100mbit limit 100mbit burst 100mbit,暂且不表,新的 qdisc 标识符为handle 20:,然后查看结果:
shell$ sudo tc class show dev eth0
class prio 1:1 parent 1: leaf 10:
class prio 1:2 parent 1:
class prio 1:3 parent 1:
class tbf 10:1 parent 10:
前面我们提到过 tc qdisc 是像树一样的层次结构,树就存在叶子结点,在qdisc的语境下叶子结点表示不可在分割的 qidsc,即classless qdisc,tbf就是该类型的qdisc,leaf 10:也表明了这一点。PRIO 的子队列只能存在一个,无法分割为多个多个子队列,man prio也提到了这点。
将 root 上的 qdisc 删除,恢复到了系统默认的 qdisc。
shellsudo tc qdisc del dev eth0 root
classless qidsc
接下来描述一些基本的classless qidsc。
[p|b]fifo
基本的FIFO队列,pfifo表示队列以packet为单位,bfifo表示队列以字节(byte)为单位。这两种类型只有一个limit参数限制这队列的长度。
pfifo_fast
linux 默认的qdisc(不过目前似乎并不是,看了下默认的是fq_codel),它只是FIFO的升级版。内部有三个bands(子队列,每个都是FIFO),高优先级的程序(实时交互程序)被放到 band0。在出队的时候,bond0也是优于其他band先将数据发送出去。示意图如下,来自:
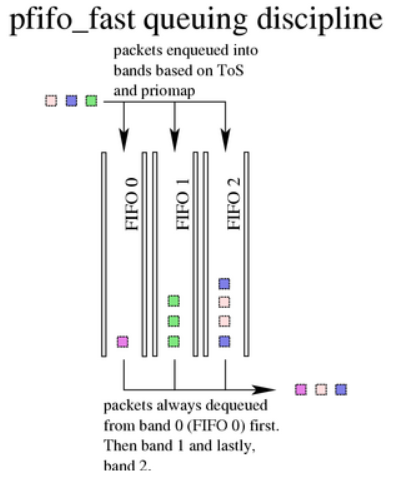
使用样例:
shell$ sudo tc qdisc add dev eth0 root handle 1: pfifo_fast
$ sudo tc qdisc show
qdisc pfifo_fast 1: dev eth0 root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
SFQ
SFQ(Stochastic Fair Queuing)是尽可能的保证在多个flow(一个flow可以理解为TCP/UDP链接)之间保证流量的公平,最直观的好处就是公平性,避免了某一些程序的流量一直出不去的情况。实现原理是使用了hash算法(根据 IP 和 port)将流量均匀地分散到了多个队列中。既然是基于hash算法,就存在不同flow的流量被放到了相同的hash bucket当中,损失了公平性,因此SFQ提供了perturb参数来避免该情况,放数据分散的更加均匀。更加详细的介绍参考man sfq。
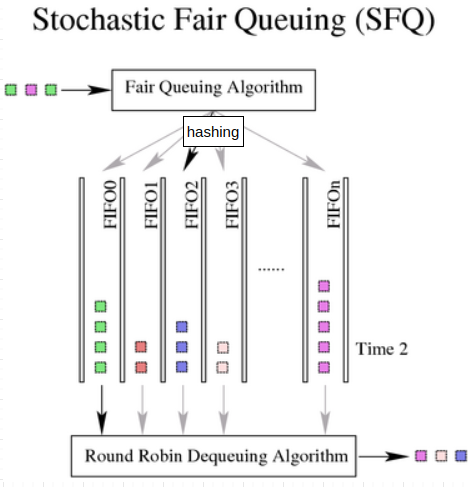
示例:
shell$ sudo tc qdisc add dev eth0 handle 1: root sfq perturb 60
$ sudo tc qdisc show
qdisc sfq 1: dev eth0 root refcnt 2 limit 127p quantum 1514b depth 127 divisor 1024 perturb 60sec
TBF
tbf(Token Bucket Filter)是我们目前唯一接触到的shaper(用于限流),前面的qdisc只能用于scheduling。这篇文档对tbf的描述很详细,tbf的基本思想是令牌桶,只有当bucket内有token可用时才可以往外发送packet,发送packet都会消耗token,如果没有token可用时packet会在队列内等待直到token可用,
tbf的示意图如下:

参数解释:
-
rate: 限定的速度
-
burst: bucket的大小,限定了可用的token数量。还有一个其他作用,不好翻译,引用man page:
Size of the bucket, in bytes. This is the maximum amount of bytes that tokens can be available for instantaneously.
-
limit: 当没有token可用的时候等待队列的长度
-
latency: 在队列中等待的时间,limit与latency不能同时设置。
还有一些其他参数不是特别明白就先略。
接下来使用tbf和iperf(网络benchmark工具)来对shaper有个基本的体验。对lo设备限速,命令如下:
shell$ sudo tc qdisc replace dev lo root handle 1: tbf rate 10mbit burst 10mb limit 10mb
然后使用iperf测试:
shell$ iperf3 -B 127.0.0.1 -s # 创建 iperf server,监听在localhost
$ iperf3 -c 127.0.0.1
实验结果如下图:
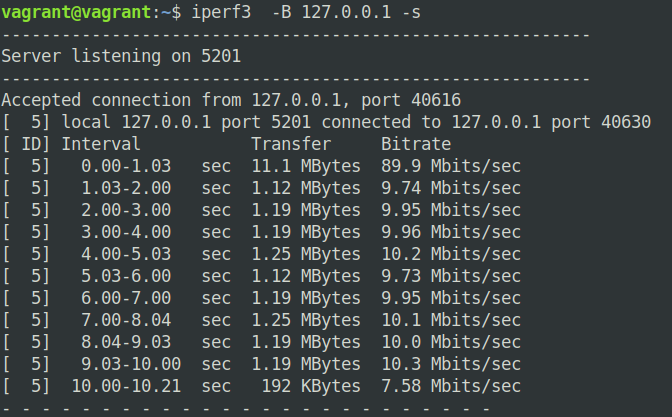
结果虽然不是那么的准确,不过可以看到速度已经被限制在了10mbit。如果没有tbf限速,lo可以达到50gbit/s以上的速度,当然这也是因为lo并非实际的物理设备。
Note: tc和tc-tbf页面对于tbf是classless还是classful存在不一致。
ingress
大部分的qdisc只能用于在egress(classful 和 classless都是如此),tc对于input的流量控制很少,毕竟我们对于远端的流量确实能做的事情很少。对ingress的能做的只有挂载一些filter,使用一些action处理流量。下面是一个 ingress 与 police(一种action) 实现限速的例子,来自:
shell$ tc qdisc add dev eth0 handle ffff: ingress
$ tc filter add dev eth0 parent ffff: u32 \
match u32 0 0 \
police rate 1mbit burst 100k
netem
netem(Network Emulator)可以用于模拟网络中的各种情况,延迟、丢包、重复等。这儿有篇较全的文档演示了netem的一些用法,下面介绍基本示例。
shell$ sudo tc qdisc add dev eth0 root netem delay 100ms # 延迟 100ms
$ sudo tc qdisc change dev eth0 root netem delay 100ms 10ms # 延迟 100-110ms
$ sudo tc qdisc change dev eth0 root netem delay 100ms 20ms distribution normal # 正态分布的100-120ms的延迟
$ sudo tc qdisc change dev eth0 root netem loss 0.1% # 千分之一的丢包率
$ sduo tc qdisc change dev eth0 root netem duplicate 1% # 百分之一的重复率
$ sudo tc qdisc change dev eth0 root netem corrupt 0.1% # 千分之一的bit错误
其他的一些qdisc的比较复杂,如codel,fq_codel就略过了,毕竟我一开始想掌握tc的目的是学下tc-bpf。
classful qidsc
HTB
HTB( Hierarchical Token Bucket)结合TBF的基本思想,也因此具备了限流的功能,除此以外HTB还能够实现不同优先级的调度。htb也比较复杂,更加完善的文档可以参考这儿。HTB目的是替换CBQ(一个更加复杂的qdisc),与TBF 相比,HTB 引入了一个borrowing的概念,作用时一个子类可以速率可以超过所限定的rate,如果它的token不够用可以从父类获取token直到达到上限(ceil),HTB的概念也比较多,没有完全明白。具体的使用可以参考下面的文档。
- https://tldp.org/HOWTO/Adv-Routing-HOWTO/lartc.qdisc.classful.html
- https://wiki.debian.org/TrafficControl
- http://luxik.cdi.cz/~devik/qos/htb/manual/userg.htm
htb所创建的class内部默认qdisc为pfifo,实际可以以其他高级的qdisc进行替换(sfq,tbf)等。下面是一个HTB 使用的基本示例:
shell$ tc qdisc add dev eth0 root handle 1: htb default 12
上述命令表示在egress方向创建了htb qdisc,default 12表示不能满足任何filter匹配条件的packet都会被转发到 id 为1:12的class。
shell$ tc class add dev eth0 parent 1: classid 1:1 htb rate 100kbps ceil 100kbps
$ tc class add dev eth0 parent 1:1 classid 1:10 htb rate 30kbps ceil 100kbps
$ tc class add dev eth0 parent 1:1 classid 1:11 htb rate 10kbps ceil 100kbps
$ tc class add dev eth0 parent 1:1 classid 1:12 htb rate 60kbps ceil 100kbps
因为 htb 是classful qdisc,所以可以包含多个class。上述命令创建了三个htb类型的class。注意,如果没有指定qdisc,htb class默认的qdisc就是pfifo。
shell$ tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 \
match ip src 1.2.3.4 match ip dport 80 0xffff flowid 1:10
$ tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 \
match ip src 1.2.3.4 flowid 1:11
最后使用filter将流量特征将流量分发到class。
PIRO
PRIO的原理没什么花哨的地方,就是多个不同优先级的队列(band)结合在一起,出队顺序按照队列的优先级分先后。可以看做是高级版的pfifo_fast,只不过PRIO包含了多个class,可以使用前面提到的qdisc加入到这些class,如果没有指定这些class默认的qdisc都是pfifo。示意图如下,图来自:

pfifo_fast与PIRO比较关键的参数priomap,如果没有进行额外的filter设置,该参数和IPv4报文的TOS结合决定了报文被发送到哪个bands。TOS字段如下:
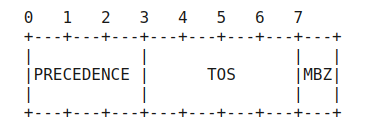
上图的MBZ代表的是Must Be Zero,中间四个bit分别代表着:
Binary Decimal Meaning 1000 8 Minimize delay (md) 0100 4 Maximize throughput (mt) 0010 2 Maximize reliability (mr) 0001 1 Minimize monetary cost (mmc) 0000 0 Normal Service
因为MBZ位于TOS四个bit的右边,相当于补充了一个bit,因此TOS 字段实际的值相当于乘2。TOS四个取值是可以相互组合的,如Minimize delay(md)+Maximize throughput(mt)组合得到值为12,这会被放入到band 1,具体的取值如下与band之间的映射关系如下:
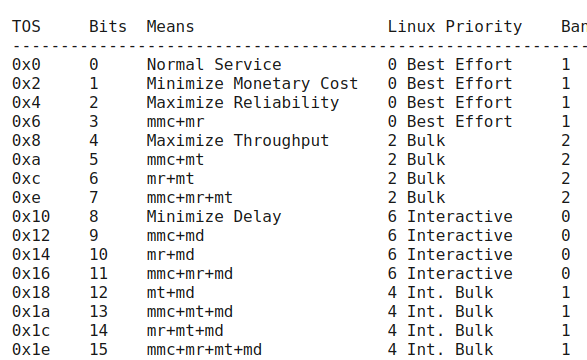
下面是默认的PRIO 默认的 priomap:
shell1, 2, 2, 2, 1, 2, 0, 0 , 1, 1, 1, 1, 1, 1, 1, 1
没有特别明白这里的顺序是代表着什么,是否代表着 TOS 的取值? man page直接就说从上面表示 priority 4 会被映射到 band 1,不明白是如何推断出来的。下面是常用协议的预设的TOS值:
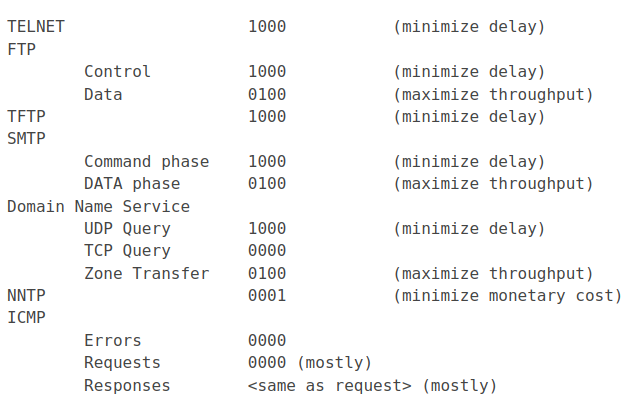
Filter
classifier
filter被用在classful qdisc 来决定流量要被发送到哪一个subclass,所有附着到class的filter都将会被调用,直到遇到条件匹配的filter。filter 可以分为两个部分,一个是分类器(classfier)用于判决packet往哪个class发送,另外一个是action,action是可选的。
filter命令的基本格式为:
shelltc filter add dev IF [ protocol PROTO ] [ (preference|priority) PRIO ] [ parent CBQ ]
protocol 指代filter处理的报文类型,prio(perf)指代filter的优先级,因为一个class上可以附着多个filter,优先级越高的(prio值越低)先被遍历。filter中最常用的是u32,这里就大概的介绍一下u32的作用,其他的filter 可以参考 man tc。 u32 filter参数众多,功能也很复杂。这段内容参考自这里。
u32 filter 支持相当多类型的选择器,有u32,u16,u8,ip,tcp,udp等。u32 选择器示例如下:
shell$ tc filter add dev eth0 protocol ip parent 1:0 pref 10 u32 \
match u32 00100000 00ff0000 at 0 flowid 1:10
参数解释:
- parent 1:0: filter 所附着的class handle
- perf 10: filter 的优先级,等同于prio
- u32: filter 类型
- match u32 00100000 00ff0000 : 使用的是u32选择器,u32选择器的参数为 [PATTERN MASK],该例子表示匹配ip报文的前四个字节,掩码为00ff0000,意思是只保留第二个字节的数据(TOS字段),并且只匹配值为0x10(low delay)
- at : 表明从哪儿开始匹配
- flowid 1:10 : 匹配的packet往哪个class转发。man-u32中示例的classid看起来了flowid的效果是同样的。
另外一个例子:
shell$ tc filter add dev eth0 protocol ip parent 1:0 pref 10 u32 \
match u32 00000016 0000ffff at nexthdr+0 flowid 1:10
总体与上面相类似,只不过使用了nexthdr+0(注意这里的nexthdr+是必须的)来将u32匹配的位置移动到传输层header(tcp),示例的命令是匹配所有端口为22(ssh)tcp报文。
u32选择器功能固然强大,可以从任意地方匹配报文的任何字节,不过不够直观。因此实际中使用的更多的应该是直接面向报文的选择器,如ip,udp,tcp等,使用下面语句同样实现了上面示例的tos匹配:
shell$ tc filter add dev ppp0 parent 1:0 prio 10 u32 \
match ip tos 0x10 0xff \
flowid 1:4
该命令可以使用画u8进行重写,match u8 0x10 0xff at 1,从命令的形势来看这暗示着具体类型的规则内部是使用u8,u32这种最普通的选择器实现的。**正因为如此,实际上tcp和udp是无法区分的,**假设我们要匹配tcp报文,那么要在ip层根据protocol字段进行选择,如下的命令展示该用法,目的是匹配所有的dns报文。
shell$ tc filter add dev ppp0 parent 1:0 prio 10 u32 \
match tcp dst 53 0xffff \
match ip protocol 0x6 0xff \
flowid 1:2
0xffff 和0xff都是表示mask,再强调一次ip和tcp等选择器底层实际上使用等还是u32等通用选择器,如果没有mask就无法正确地选取我们所需要的值。
action
action的直接作用是,一旦满足classfier匹配原则,就采取一些额外的动作,例如将匹配的packet直接丢弃(police的功能)。注意,action对于packet的处理优先于对packet的分类。比较常用的action就是police,例子如下,来自:
shell$ tc qdisc add dev eth0 handle ffff: ingress
$ tc filter add dev eth0 parent ffff: u32 \
match u32 0 0 \
police rate 1mbit burst 100k
上面的语句表示调用了police实现了对ingress的限速,暂时不清楚burst参数的意思,man page的描述也十分简陋。语句的 超过了1mbit的数据都将会被直接丢弃。将上述稍微改下,变成如下的形式:
shell$ tc filter add dev eth0 parent ffff: u32 \
match u32 0 0 \
action police rate 1mbit burst 100k
多了一个action,该形式的目的是能够同时设置多个action。如下命令表示将超过1mbit的packet转发到lo设备:
shell$ tc filter add dev eth0 parent ffff: u32 \
match u32 0 0 \
action police rate 1mbit burst 100k conform-exceed pipe \
action mirred egress redirect dev lo
conform-execeed pipe表示超出rate限制的packet交给下一条action处理,mirred是一个用于转发packet的action,egress的意思表示所处理的packet将会出现在lo设备的egress方向,所以这暗示着应该可以被lo设备的qdisc所处理(未验证)。
其他一些action:
- bpf: bpf程序不仅可以用在action当中,也可以用在classifier,参考tc-bpf
- mirred: 可以对packet复制或者转发,参考tc-mirred
- police: 可以实现限速,将超过所设定速率的packet直接丢弃,详细的用法参考tc-police
结语
tc总体来说还是比较复杂的,主要是各种类型的qdisc、各种类型的filter不能一一完全学习明白。所可以参考的资料并不多或者是太长not easy to follow。
参考资料
https://lartc.org/lartc.html 本篇文档长且全就是读起来耗时间
https://tldp.org/HOWTO/Traffic-Control-HOWTO/intro.html 简单一些,但是在概念上阐述有些地方不是那么好懂
本文作者:strickland
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!