目录
之所以学习 tc-bpf 是之前想编写一个流量监控的组件,使用的方案是分别在流量的出入口使用kprobe挂载 eBPF 程序,挂载点选取的是__dev_queue_xmit(往外发送流量),在当时遇到的问题是接受流量的挂载点没有找到合适的,参考了这篇文章以后选取了几个挂载点都无效(实际上该问题还是因为挂载点的选取问题),在stackoverflow 上提问有好心人提示可以用 tc-bpf来实现。
对于 tc-bpf描述较为完善的文档只有这篇博客,本文的大部分内容也是参考该文并且实现了一个demo项目,目的是用tc-bpf监控网卡上出入流量的字节数。学习tc-bpf最好先对tc 有基本认识,否则很难理解相关概念。
基本概念
tc本身是一个复杂的工具,它的基本作用是设置基于各种算法实现策略来实现流量控制。基本概念包括:
- qdisc: 简单的理解为一个队列,packet将会进入到qdisc等待被发送。
- classes: 根据预先定义的分类器(filter或称为classifiier)将流量存放到各个class
- classifier: 分类器,根据各种预定义的条件对流量分类。
- action: filter 除了对流量进行分类转发以外,还可以丢弃(police),转发(mirred)等操作。
从linux 4.1 开始支持使用 bpf 程序作为 classifier,对于ebpf classifier而言,它的返回值决定了流量会被如何分类。
-
0: 不匹配,跳转到下一个filter如果有的话
-
-1: 将流量转发到filter所配置的默认class,默认的class是由
tc filter命令的flowid所配置的。文档的描述为:denotes the default classid configured from the command line
-
任何其他取值都将会被认为是目标class id。
bpf action
action 的返回值决定了如何去处理packet,对于 bpf action,可选的返回值如下:
- TC_ACT_UNSPEC(-1): 使用tc 命令所配置的 action(和classifier相类似)。
- TC_ACT_OK(0): 放行,结束整个处理流程(processing pipeline),虽然未实际验证,这里暗示的应该是后续的filter都不会被经过。
- TC_ACT_RECLASSIFY(1): 结束处理流程,重新classification,未实际验证,不过猜想的场景是直接修改了packet的数据然后在去进行分类。
- TC_ACT_SHOT(2):结束处理流程并且将packet丢弃
- TC_ACT_PIPE(3):去往下一个action,如果存在的话。
direct-action
总的来说,tc filter 的功能分为两个部分classifier用于区分流量,action(如果有)则如何去处理流量。eBPF 的功能十分强大,人们逐渐意识到 eBPF 程序内已经可以对packet进行各种处理,这种情况下 action的作用显得很多余,不过classifier的返回值是classid,不能直接让内核去丢弃packet,这就是direct-action的由来。direct-action(da)将作为参数传递给tc filter命令,这将告诉内核filter的返回值应该被认为是action。这也就意味着classifier也可以返回TC_ACT_OK,TC_ACT_SHOT让内核放行或者丢弃packet。就性能而言,direct-action因为省略了额外的action调用具有了更好的性能,使用direct-action模式的tc-bpf是最简单的,也是目前最值得推荐的方法。
那么,既然classifier也能实现action同样的功能,这是否意味着 bpf action 没用了? 从使用这角度来说,这确实是的,da 模式下的 tc bpf 程序功能已经十分强大。不过 bpf action 仍然是有用的,例如与 u32 filter 结合。
另外一个问题是,bpf classifier 的返回值不再作为 classid,那么这是否代表着 bpf classifier 已经失去了流量分类的功能?答案是否定的,struct __skb_buff(该结构体是传递给tc bpf 程序的唯一参数s)内的tc_classid将作为classid告诉内核如何分发流量,在后文我们在结合内核源码来说明。
clsact qdisc
在direct-action引入后的几个月,在linux 4.6当中出现了一种新的qdisc称为clsact,它与 ingress qdisc相类似,我们可以往ingress qdisc 使用 da模式的bpf程序,这也是 ingress qdisc的局限性,它只能用于进入当前主机的流量。clsact 对ingress进行了扩展,它可以在egress方向上也附着da模式bpf程序。
更多关于 clsact qdisc 信息见 commit log 和 Cilium Guide,限于只是水平对于链接的内容还是有不少没理解的地方。
示例程序
示例程序使用ebpf-go和tc-bpf相结合实现流量统计的功能(发送与接收)。核心代码参考:
cstatic __always_inline int parse(struct __sk_buff *skb, int mode) {
void *data_end = (void *)(unsigned long long)skb->data_end;
void *data = (void *)(unsigned long long)skb->data;
}
首先来看参数,上述函数的参数struct __sk_buff是struct sk_buff的镜像(mirror),BPF verifier 会在加载bpf程序的时候将它内部的结构体翻译为 struct sk_buff。对于struct __sk_buff的文档描述相当少,有价值的可以参考这篇,具体的内核源码是bpf_convert_ctx_access函数,如下代码作为示例:

分别将len和protocol翻译为了 struct sk_buff与之对应的结构体。
在以前,如果要从skb_buff内获取packet的内容,要借助bpf_skb_load_bytes。不过从linux 4.7 开始支持以direct packet access,即直接使用指针就可以访问到packet的内容,如果有 XDP 编程经验应该会对这个过程相当熟悉,但是这里似乎与 XDP 还是有一些差别的,后边讨论该内容。data与data_end分别指向packet的第一个和最后一个字节,操作data指针就直接访问到了packet的内容。如下代码演示了如何获取 eth header:
cvoid *cursor = data;
if (cursor + sizeof(struct ethhdr) > data_end) {
return TC_ACT_SHOT;
}
struct ethhdr *eth = cursor;
cursor += sizeof(struct ethhdr);
这一点与 XDP 程序是十分相似的。相类似的,我们只要逐层的拆开报文的header,提取出 ip地址信息即可。不过因为 ipv4 header是边长的,递增cursor的时候需要根据 ipv4 的 ihl字段,如下:
cif (cursor + sizeof(struct iphdr) > data_end) {
return TC_ACT_SHOT;
}
struct iphdr *ip4_hdr = cursor;
cursor += ip4_hdr->ihl * 4;
后续的工作就是提取出ipv4 header的tot_len字段,存放到 ebpf map当中,这部分程序的逻辑十分简单不过多描述。因为我们需要用 ebpf-go 程序去读取map的内容,但是实际加载 ebpf 程序的是tc,所以我们只能将 map 设置为pinning,这需要用到LIBBPF_PIN_BY_NAME选项,然而该选项在老的map定义中并不可用,具体的:
cstruct bpf_map_def SEC("maps") xdp_stats_map = {
.type = BPF_MAP_TYPE_PERCPU_ARRAY,
.key_size = sizeof(__u32),
.value_size = sizeof(struct datarec),
.max_entries = XDP_ACTION_MAX,
};
要使用如下形式才可以支持pinning map。对于这两种形式的map定义形式的讨论可以参考这里。
cstruct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, struct ip_key_t);
__type(value, __u64);
__uint(max_entries, 10240);
__uint(pinning, LIBBPF_PIN_BY_NAME); // pinning map
} received_map SEC(".maps");
pinning map将会存在于/sys/fs/bpf目录下,在本例中 map 存在与/sys/fs/bpf/tc/globals目录下,可以直接使用cat 打开这些文件的内容,其实就是kv数据,如下:
{182175776,223982344,}: 2509 {182175776,4026531834,}: 1608 {182175776,2398801006,}: 11596 {182175776,2398801731,}: 28799 // 省略了一些数据 ....
然后在 ebpf-go 当中读取map的数据并且输出,ebpf-go 需要读取map在ebpf文件当中的定义,所以还需要在源码中对map重新声明一次,核心代码直接参考源码吧。使用如下命令编译、加载、移除 tc bpf 程序
shell# 编译
clang -O2 -g -Wno-everything -emit-llvm -c tc-bpf.c -o - | \
llc -march=bpf -mcpu=probe -filetype=obj -o tc-bpf.o
# 加载
sudo tc qdisc add dev eno1 clsact
sudo tc filter add dev eno1 egress bpf da obj tc-bpf.o sec egress
sudo tc filter add dev eno1 ingress bpf da obj tc-bpf.o sec ingress
# 移除
sudo tc qdisc del dev eno1 clsact
最后程序的输出结果如下:
10.219.200.32 13.89.179.8 2509 # 10.219.200.32往13.89.179.8发送2508字节 10.219.200.32 239.255.255.250 1608 10.219.200.32 142.250.204.110 11596 10.219.200.32 142.250.207.67 28799
Note:
在示例源码中的if (!is_IPv4(eth->h_proto))是必须的,否则遇到ARP报文会解析出不正确的 ip 地址。
问题记录
以我有限的tc使用经验来说,每个设备只能存在一个qdisc,clsact 有一些意外,暂时没有找到对于这点的文档描述,添加clsact设备以后,qdisc有两个:
shell$ sudo tc qdisc show dev eno1
qdisc fq_codel 0: dev eno1 root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
qdisc clsact ffff: dev eno1 parent ffff:fff1
加载 tc bpf 程序中的 egress和ingress指代的是什么?一般来说 filter 都需要设置一个parent参数来表明它所绑定到的是哪个qdisc,如果在clsact的ingres指代的是ingress qdisc,那么应该egress也应该是指代qdisc,不过又没有找到这样的信息。因此,我暂且将这里认为是:原理未知,但是只要这样做就可以达到效果。另外一个角度来说,这里的ingress和egress可能是表示网络的流量(出和入)。
如果有过xdp的编程经验,就知道xdp程序需要进行内存访问的限制,所以如下的判断语句十分重要,关于xdp的内容可以参考这里。
cif (nh->pos + sizeof(struct iphdr) > data_end) {
return -1;
}
访问超过该判断语句以外的内存区域都是不合法的。但是这一点在 tc bpf当中似乎不是这样,下面代码也可以正常的被加载:
cif (cursor + 1 > data_end) { // 如果在xdp当中,该语句会让verifier限定只能访问一个字节的数据
return TC_ACT_SHOT;
}
struct ethhdr *eth = cursor;
cursor += sizeof(struct ethhdr);
bpf_printk("dest:%d",eth->dest);
结构体访问
struct __sk_buff内包含的成员也相当多,包括了ip,端口等。但是这些成员并不是供所有的程序可访问的,内核对可访问的结构体是有限制的。对于tc bpf程序类型为BPF_PROG_TYPE_SCHED_CLS(使用bpftool prog list可以查看bpf程序的具体类型),相关内核代码如下:
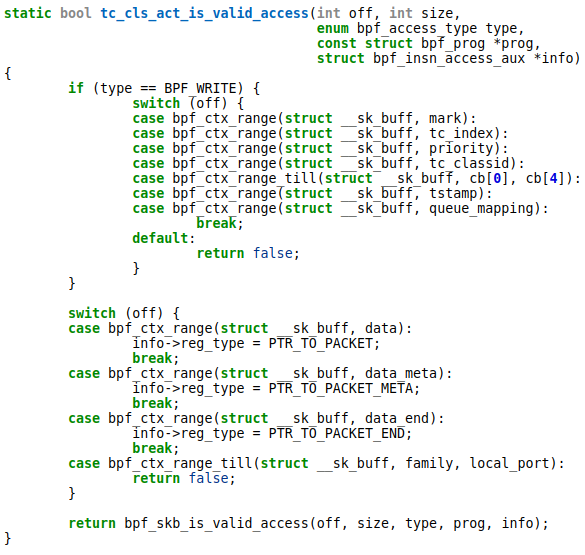
上边代码表示,对于mark,tc_index,tc_classid,priority等字段 tc bpf 程序是可写的,bpf_ctx_range_till表示从family到local_port(包括这俩)成员都是不可访问的,源码注释也提示这这一块内容是给BPF_PROG_TYPE_sk_skb所使用的。
c/* Accessed by BPF_PROG_TYPE_sk_skb types from here to ... */
__u32 family;
__u32 remote_ip4; /* Stored in network byte order */
__u32 local_ip4; /* Stored in network byte order */
__u32 remote_ip6[4]; /* Stored in network byte order */
__u32 local_ip6[4]; /* Stored in network byte order */
__u32 remote_port; /* Stored in network byte order */
__u32 local_port; /* stored in host byte order */
/* ... here. */
所以,要知道各层报文的数据只能手动去解析packet。如果尝试访问这些成员,verifier会提示如下的错误信息:
invalid bpf_context access off=80 size=4
对于bpf 程序访问struct __sk_buff的访问限制可以参考
https://stackoverflow.com/questions/67402772/bpf-verifier-rejects-when-try-to-access-sk-buff-member
https://stackoverflow.com/questions/61702223/bpf-verifier-rejects-code-invalid-bpf-context-access
helper function
也不是所有的bpf helper function 都是可用的,我一开始想在 tc bpf 程序内使用bpf_get_current_comm,verifier 会提示:
unknown func bpf_get_current_comm#16
即使我也已经引用了定义该函数点头文件bpf/bpf_helpers.h。事实上每种类型BPF程序可使用的helper函数是有限制的,使用bpftool feature可用的helper函数,结果显示tc bpf 是无法调用bpf_get_current_comm的。
kprobe无效的原因
最初我选取了__netif_receive_skb_core来作为流量接收方向的挂载点,然而捕捉不到任何数据,这是因为ubuntu下正确的挂载点应该是__netif_receive_skb_core.constprop.0(该函数名比较诡异,可能是GCC 编译内核的时候一些优化),可以使用该示例程序(修改挂载函数名)来验证函数是否为正确的挂载点。
解决上述问题的思路来源于这份(作者是(Daniel Borkman),里面展示了 tc bpf的hook点:
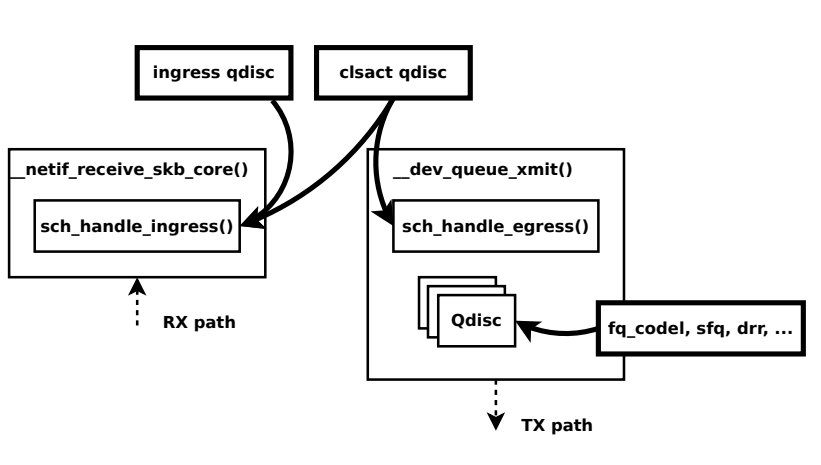
不过暂时遇到的问题是挂载ebpf到__netif_receive_skb_core.constprop.0解析struct sk_buff的数据有些问题,以后再琢磨。另外,pdf文件内还提到da模式下设置tc_classid来转发流量。
In DA, eBPF prog sets skb->tc classid, returns action code
源码解析
这儿源码的作用介绍下tc bpf 程序是如何转发流量的,源码地址,关键的代码如下:
cTC_INDIRECT_SCOPE int cls_bpf_classify(struct sk_buff *skb,
const struct tcf_proto *tp,
struct tcf_result *res)
// 省略了一些代码
if (tc_skip_sw(prog->gen_flags)) {
filter_res = prog->exts_integrated ? TC_ACT_UNSPEC : 0;
} else if (at_ingress) {
/* It is safe to push/pull even if skb_shared() */
__skb_push(skb, skb->mac_len);
bpf_compute_data_pointers(skb);
filter_res = bpf_prog_run(prog->filter, skb);
__skb_pull(skb, skb->mac_len);
} else {
// egress
bpf_compute_data_pointers(skb);
// 调用 bpf 程序
filter_res = bpf_prog_run(prog->filter, skb);
}
if (unlikely(!skb->tstamp && skb->mono_delivery_time))
skb->mono_delivery_time = 0;
if (prog->exts_integrated) {
res->class = 0;
// 这儿将 tc_classid 从 struct __sk_buff 中获取
res->classid = TC_H_MAJ(prog->res.classid) |
qdisc_skb_cb(skb)->tc_classid;
ret = cls_bpf_exec_opcode(filter_res);
if (ret == TC_ACT_UNSPEC)
continue;
break;
}
}
commit 045efa82ff56提供了tc_classid简单示例,用于分别转发arp,ip,ipv6 报文到不同的class,程序如下:
cint cls_bpf_prog(struct __sk_buff *skb)
{
/* classify arp, ip, ipv6 into different traffic classes and drop all other packets */
switch (skb->protocol) {
case htons(ETH_P_ARP): skb->tc_classid = 1; break;
case htons(ETH_P_IP): skb->tc_classid = 2; break;
case htons(ETH_P_IPV6): skb->tc_classid = 3; break;
default: return TC_ACT_SHOT;
}
return TC_ACT_OK;
}
参考资料
https://qmonnet.github.io/whirl-offload/2020/04/11/tc-bpf-direct-action/ 介绍direct-action,也是本文内容的来源之一
https://arthurchiao.art/blog/understanding-tc-da-mode-zh/ 翻译了上一遍文章,并且加入了一些源码解释
https://liuhangbin.netlify.app/post/ebpf-and-xdp/ 演示了 tc-bpf程序的demo
https://docs.cilium.io/en/latest/bpf/progtypes/#tc-traffic-control cilium对于direct-action的一些描述,不好懂
https://medium.com/@c0ngwang/understanding-struct-sk-buff-730cf847a722 仅有的struct __sk_buff描述的文档
本文作者:strickland
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!