目录
namespace 与 cgroup 是容器的两个基本技术,namespace的作用是保证资源的隔离,不同进程之间所看到的资源是完全独立的,譬如说一台物理机可以实现多个绑定在80端口的web服务,这是容器常见的一种应用。而cgroup的作用是资源的限定,可以对某一组进程限定它们可使用的 CPU 而避免CPU被独占。cgroup的简介可以参考wiki-cgroup。
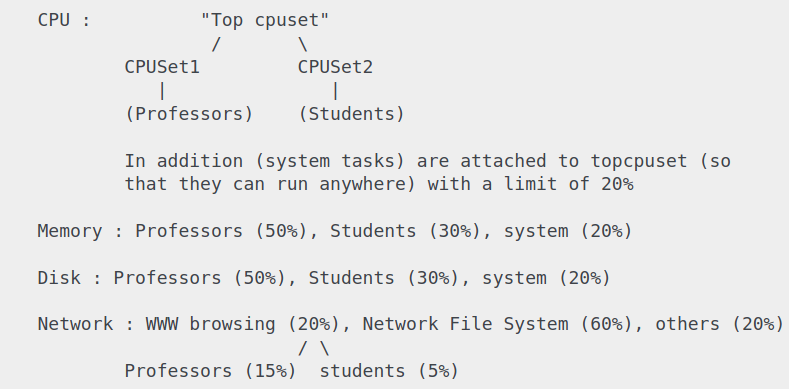
一个cgroup指的是多个进程或者线程,一个subsystem是用于约定cgroup内进程行为的模块,子系统可以实现限定 CPU 使用时间、挂起和恢复进程的执行(freezer)、限定内存的使用等功能,subsystem又成为控制器(resources controller)。子系统的定义有些晦涩,直观的理解子系统就是各种硬件资源。各个cgroup之间存在层次结构(想象为一颗树状结构),位于高层的cgroup限定了低层cgroup可用的资源,换而言之底层的cgroup不能超过高层cgroup所限定的资源。下图是一个样例,来自:
cgroup v2在linux 4.5被合并到了内核,v1 与 v2 是支持混用的。使用cat /proc/filesystem | grep cgroup查看系统所支持的cgruop版本,使用mount| grep cgroup查看系统所挂载的cgroup版本,下面表示cgroup v1 与 v2 混用。
shell$ mount | grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/unified type cgroup2 (rw,nosuid,nodev,noexec,relatime)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)
# 省略了一些内容
在一些比较新的系统当中已经默认采用了cgroup v2,这里列举了默认采用 cgroup v2 的系统版本。如果需要回退到 cgroup v1,修改/etc/default/grub文件的GRUB_CMDLINE_LINUX添加参数:
shellsystemd.unified_cgroup_hierarchy=0 # 如果该值为1表示启动了cgroup v2
然后更新grub,reboot即可。
使用cgroup
cgroup 以虚拟文件系统的形式存在,一般来说cgroup的挂载点都是在/sys/fs/cgroup目录下,取决于不同的内核版本,查看该目录下的内容就显示了所有挂载的控制器。
shell$ mount -t cgroup -o cpu none /sys/fs/cgroup/cpu
上述命令表示将 cpu controller 挂载到了/sys/fs/cgroup/cpu,这里的none指代的意思不太明确,这里说none是指挂载点不具有实际的物理分区。v1文档提到这里的none将原样出现在/proc/mounts中,因此这应该是一个提示性的名词。
一次性挂载多个controller,不过影响就是cgroup内的进程(cgroup.procs)或者线程(tasks)会同时受到这两种controller的影响。
shell$ mount -t cgroup -o cpu,cpuacct none /sys/fs/cgroup/cpu,cpuacct
进入到cpu,cpuacct目录下查看,可以看到两种类型的controller 配置文件都位于该目录下,这代表着cgroup.procs 文件内(它表示哪个进程位于该cgroup)会受到两种controller的影响。

一个目录挂载多个controller称为comount,这种情况下将其中一种类型的controller挂载到其他目录都是不允许的(比如说将已经挂载的cpu,cpuacct中的cpu单独拎出来在重新挂载)。不过现有的controller可以被挂载多次,但是在各个目录下所看到的东西是完全相同的。
上图的cgroup.procs和tasks分别表示位于该cgroup内的进程和线程,如果要限定一个进程的CPU使用率,那么我们在/sys/fs/cgroup/cpu目录下新建任意一个目录,并且然后进入到该目录将要被限速进程的 pid 写入到 cgruop.procs。其他的controller使用方法完全相同,使用样例网上已经很多,不多赘述。
使用umount来取消cgroup的挂载,再使用rmdir将挂载点的目录移除就彻底地移除了cgroup,如果有任何进程仍然处于cgroup内(v2的文档说僵尸进程的pid不会出现在cgroup.procs文件内),那么无法取消挂载。
controllers
下面列举controllers以及它们的作用,至于每种controller下各种文件是什么作用,这有篇十分详细的文档。
cpu
保证了在系统CPU繁忙的情况下一个cgroup进程可用的CPU的下限。关键的几项配置:
-
cpu.shares: 确保了在CPU繁忙的时候至少可用的CPU利用率,默认为1024,如果三个cgroup该值都是1024,因此每个cgroup都可以获得33%的CPU利用率
-
cpu.cfs_period_us: 是cpu的调度周期(默认值为10 0000 us,100ms,该值一般不会修改)。
-
cpu.cfs_quota_us:限定在一个调度周期内cgroup可以占用cpu的时间(单位为us),该值为-1则表示没有任何CPU时间的限制。如10000us(10ms)就表示可以占用10%的cpu利用率。
-
cpu.stat: 内记录的是一些统计信息
注意: k8s pod manifest 中 cpu request 设置的是cpu.share,cpu limit设置的是cfs_quota_us。因此,从概念来说pod manfiest中定义的 pod cpu request并不是限制了cpu的利用率,文档的描述是 request 只是一个权重,代表着在cpu繁忙的场景中不同pod被分配到的cpu时间不同。
The CPU request typically defines a weighting. If several different containers (cgroups) want to run on a contended system, workloads with larger CPU requests are allocated more CPU time than workloads with small requests.
pod的manifest 设置的 cpu:200m会被等同于设置cpu.shares:200。
实验模拟也十分简单,可以参考这儿。分别在 cpu controlller下创建两个不同的cgroup,将cpu利用率高的程序写入到cpu.procs,分别将两个cgroup的cpu.shares修改为1024和512,在查看此时的CPU利用率,两者比率恰好是: 66% :33%。

cpuacct
提供一些统计信息,如cpuacct.stat内表明分别有多少时间用于user和system,注意这两个时间单位是USER_HZ。其他的文件是什么作用都很直观了,不过多解释。
cpuset
cpuset的作用是限制cgroup内的进程可以访问的cpu和memory node,因为现代的服务器多cpu和多内存是很常见的,距离cpu远的内存肯定访问要慢,cpuset目的就是为了这个。
- cpuset.cpus: 限定了可用的 cpu ,比如说
0-2,16表示cpu0,1,2和16可供cgroups使用。 - cpuset.mems: 限定了可用的 memory node,表示方法同上.
如果一个进程被限定使用哪些cpu和memory node,查看/proc/$PID/status这些信息就会得到体现。
memory
用于配置cgroup内进程内存相关的配置
-
memory.limit_in_bytes: 限定进程可以使用的内存
-
memory.usage_in_bytes: 显示当前所使用的内存
-
memory.soft_limit_in_bytes: 该配置单主要场景是在内存竞争繁忙的情况下,内核会尽可能的将cgroup所使用的内存缩减到它的soft limit,也就是说soft limit确保了cgroup可用的内存下限。因此soft_limit的设置必须低于
imit_in_bytes。如果查看现有的system.slice和user.slice下的
memory.limit_in_bytes,它们的值都是9223372036854771712(该值为INT64_MAX),这表明默认情况下没有给进程设置内存上限。
net_cls
将从cgroup出去的流量都放到qdisc当中,该qdisc以net_cls.classid表示。显然该controller可与tc结合在一起使用,实现容器限速的功能,下面是一个示例,将所有的cgroup流量都转到了0x10:1的qdisc。
shell$ tc qdisc del dev eth0 root
$ tc qdisc add dev eth0 root handle 10: htb default 12
# 创建了一个id为 10:1,类型为 htb,限速到 1500kb 的qdisc
$ tc class add dev eth0 parent 10: classid 10:1 htb rate 1500kbit ceil 1500kbit burst 10k
# red这个cgroup内的流量全都转发到0x100001,0x100001等同于 0x10:0001
$ echo 0x100001 > /cgroup/net_cls/red/net_cls.classid
blkio
blk限制的是io操作,主要分为两个方面: 按权重分配io操作以及限制io操作。
-
blkio.weight: 设置io操作的权重(linux的IO请求基于CFQ调度),具体的未深究,不过应该权重越高调度的几率越高。
-
blkio.weight_device: 用于设置具体某个设备的IO权重,设置了该配置会覆盖上一项配置的值。
-
blkio.throttle.read_bps_device: 限定某个设备每秒读取的字节数,如下示例表示将
8:0的读取限速为10 MBps.shell$ echo "8:0 10485760" > /cgroup/blkio/test/blkio.throttle.read_bps_device8:0是linux对于设备的一种表示(major numer : minor number),直接进入到/dev使用ls -l查看:shell$ ls -l brw-rw---- 1 root disk 8, 0 1月 31 20:22 sda brw-rw---- 1 root disk 8, 1 1月 31 20:22 sda1 brw-rw---- 1 root disk 8, 2 1月 31 20:29 sda2 brw-rw---- 1 root disk 8, 3 1月 31 20:22 sda3 brw-rw---- 1 root disk 8, 4 1月 31 20:22 sda4 brw-rw---- 1 root disk 8, 5 1月 31 20:22 sda5那两列数字就表示了major number 和minor number。
-
blkio.throttle.read_iops_device: 限定每秒可以进行的 IO 操作次数。
shell$ echo "8:0 10" > /cgroup/blkio/test/blkio.throttle.read_iops_device
表示对于8:0设备每秒只能进行10次io读取操作。
docker 与 k8s
cgroup的各种controller已经完全被docker所支持,docker run文档中的各类参数就是直接转为了docker 容器的controller配置。默认的docker容器都会位于docker这个cgruop下,而k8s pod位于kubepods这个cgruop下,使用lscgroup可以查看到所有的cgroup信息。
对于docker配置参数的详细描述信息可以参考:https://docs.docker.com/config/containers/resource_constraints/
k8s 和 docker 所设置的内存和 cpu如何影响着 cgroup 这些参数设置,可以参考如下两篇文档:
https://medium.com/@betz.mark/understanding-resource-limits-in-kubernetes-memory-6b41e9a955f9
https://www.cnblogs.com/sunsky303/p/11544540.html
参考资料
https://docs.kernel.org/admin-guide/cgroup-v1/index.html cgroup v1 的内核文档
https://www.cnblogs.com/sammyliu/p/5886833.html 列举了一些常见的controller 的示例
本文作者:strickland
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!