目录
iptables一直不懂,对它的一些概念望而生畏,写一篇文档记录。iptables最直观的作用就是防火墙,在内核里边设置一些包过滤规则,内核会基于这些规则来实现各种各样的功能 NAT 转发,包的丢弃,IP包转发过程中的TTL的修改等。
基础
iptables中关键的两个概念是链(chain)和表(table),两者在概念上有些交集所以理解起来不够直观。iptables底层是内核的netfilter,iptables只是用于给netfilter设置一些规则,它根据这些规则行动。那么很显然,我们可以根据一个网络包在一台机器上的几个阶段来进行插入不同的规则:
- PREROUTING: 路由前的规则,这和我们普通的liunx用户差的有些远。不过我们将主机想象为路由器(openwrt就是被广泛用于在路由器里边的linux系统)。这所谓的路由前(pre-routing)意思是网络包被接受进来了,不过还没有做任何的路由决定(是发出去呢?还是传给当前主机呢?)。我们知道NAT的作用是网络地址转换,将公网IP依据端口转发转为内网IP,NAT的规则就是作用在路由前。
- INPUT: 已经知道了包就是给当前主机了。那么当前主机可以做一些事情是: 判断这个网络包是否合法,起到防火墙的作用,比如说我们设置一些规则丢弃来自某一网段的网络包。
- FORWARD: 既然前面说过了有路由前的规则,前提是网络包不是发给当前主机。那么就要转发出去,这里就是设置一些转发出去的规则,我们知道ip报文在经过一个路由器以后TTL减1,实际上就可以在这里做。
- OUTPUT: out和in是相对的,当前主机要把数据发出去就要经过这儿。比如说,我们设一些防火墙规则是针对出去的,数据对于某一个网段的IP不能出去(就好像GFW)
- POSTROUTING: 还是那个大前提数据,要从当前机器出去了(不论是转发的数据还是当前主机发出去的数据),这里可以设置一些规则进行NAT转换,比如说将内网IP设置为公网IP。
结合上一段描述来说,数据包到达一个主机主要两个方向: 1. 是否为当前主机 2. 是否为转发。上述的规则就在不同的道路上发挥着自己的作用,示意图如下,图来自这里:
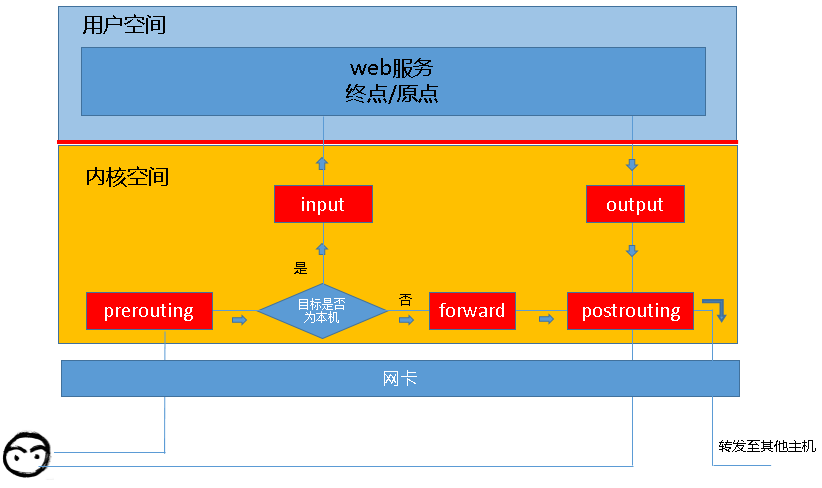
总结一下:
对于目标主机就是当前主机的网络包,经过的路径是: PREROUTING-> INPUT
对于要转发的网络包,从当前主机经过的路径是: PREROUTING->FORWARD->POSTROUTING
从当前主机出去的数据包:OUTPUT->POSTROUINT
话又说话来,上面的描述我们提到一些规则的作用点存在一些共性,比如说NAT发生在在POSTROUTING和POSTROUTING,防火墙过滤可以发生在INPUT和OUTPUT,那么对于规则就有另外一种组织方式,我们以功能(也就是iptables概念中的表)来组织规则(chain)。换个角度说,表的指代的是功能,而chain的功能则是在何处去发挥这些功能。 iptbales 有几张内置的表,如下:
- filter 表: 用的最多的表,用于判断网络数据能否顺利的到达当前主机某个程序,INPUT,FORWARD,OUTPUT这三条chain可以作用在这。
- NAT 表: 进行 NAT 转发的表,PREROUTING,OUTPUT,POSTROUTING 这三条chain作用在这。
- mangle 表: 对报文进行修改,修改 ip 报文的 TTL 字段,链路拥塞就设置 ECN 字段。PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING 的规则都可以插入到这。
- raw 表: 不是特别了解,按照这里描述。因为 iptables 是有状态的,也就是内核会注意到数据包之间的联系(比如说同一个 TCP 链接之间的网络包)。raw表的规则会先于内核进行状态追踪之前就生效.INPUT,FORWARD,OUTPUT
可以看到某些规则同时多个表内都存在,比如说我们可以在 nat和mangle内都设置PREROUTING规则,那么这俩规则哪个先被经过呢?这没啥好说的,死记硬背吧,当一种类型的链同时处于多张表的时候,它们的遍历顺序为:
raw –> mangle –> nat –> filter
其实不尽然,更加完善的说法可以参考这篇文档。另外同一条chain上的规则是被逐个遍历的,直到找到一条可满足的规则进行处理,如果都不满足就采用默认设置的规则。最后总结一下表和规则之间的关系,图来自:
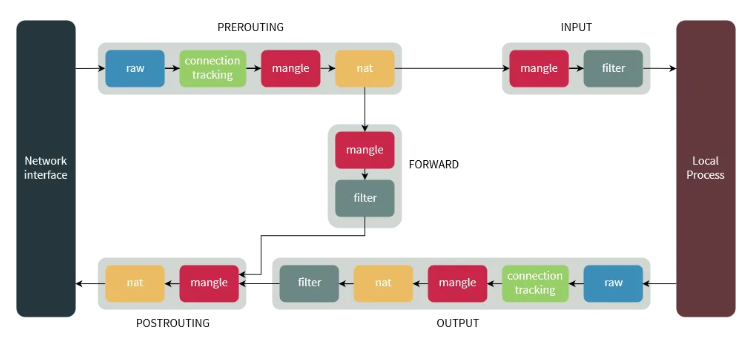
进而的问题是,当网络包满足某条匹配规则的时候应该如何处理?这在 iptables 的术语中称为 target(下文就称为动作),iptables 将targets分为两个大类,分别是: terminating targets and non-terminating targets:
- Terminating targets: 当某条规则被满足以后,这种类型的 target 会结束iptables的evaluation过程,将控制权返回给netfilter,取决于target的动作,假如是允许接收,那么就去下一个地方。比如说接收时,报文经过
PREROUTING是可以接收的,接着就去INPUT继续判断。加入PREROUTING时不能被接收,被直接丢弃,那么至少这条报文是不能进入当前主机的。这类 target 主要有: accept,drop,reject - Non-terminating targets: 某条规则无论是否满足都不会影响这条报文的在当前主机的状态,比如说iptables 设置一条规则,它的target是log。那么这条规则就是non-terminating ,它的作用就是在内核日志中将他记录。不过无论报文最终还是要被terminating targets 所处理。
小试牛刀
接下来我们要对 iptables 尝试插入自己的一些规则,在这之前介绍 iptables 对于规则修改所支持的基本增删改查操作:
-A: 往chain后面追加一条或者多条规则-D: 根据规则的定义或者是规则的行号删除-I: 根据行号插入一条规则,如果没有指定行号,那么默认从最开始的地方插入-R: 根据规则的定义或者行号进行替换-F: 将某张表上某条链的规则都清空
查看规则
使用sudo iptables -L就可以看到现有的规则,如果我们没有指定某张表,默认为filter表,如果没有进行任何的设置,通常一台主机上的filter 表都为:
shellChain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination
这表示filter表上对于INPUT,FORWARD,OUTPUT 这三条chain的策略都是接受。target是动作,prot是规则所针对的协议,opt是选项,source和destination分别是规则的作用的IP源和目标IP。对于规则的查看还有一些其他的参数,具体可以参考man iptables,下面选了一部分作为示例:
-t: 操作某一张具体的表,如iptables -t nat -L查看 nat表的规则-L:列出规则-n:iptables -L默认列出规则是会进行反向DNS解析的,-n参数的作用是直接以IP地址的形式展示规则,就是将网络报的IP转为域名是一个相当耗时的过程,因此推荐-L和-n一起使用。-v: verbose,显示规则的详细情况,会包括规则作用的网卡名称,链所处理的网络包的数量和经过字节数(单位是k,m,g这样的形式)等。-x: 显示某一条链上的数据的网络包数量,所处理的字节数,而不是k,m,g这种形式的。--line-numbers: 显示规则的行号-S: 显示某表上的所有规则-P: 设置某条chain的规则
更加细节的操作直接查看sudo iptables -h即可。
操作协议
暴力的直接将拒绝所有的TCP链接,示例:
shellsudo iptables -A INPUT -p tcp -j DROP
操作IP
实验环境最好用虚拟机,推荐vagrant好用又便捷。
使用如下命令在8080端口创建一个http服务器:
pythonpython3 -m http.server 8080
屏蔽来自宿主机的流量,往 filter 表加入以下规则,意思是任何以 10.219.201.12作为源IP地址的网络包都将被丢弃。
shell$ sudo iptables -t filter -I INPUT -s 10.219.201.12 -j DROP
$ sudo iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
DROP all -- 10.219.201.12 anywhere # 屏蔽来自10.219.201.12的流浪
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
此时如果从宿主机 curl 10.219.204.164:8080是无法访问的,使用-v选项可以看到这条规则确实将我们发送的网路包都丢弃了,结果显示丢弃了3个网络包,丢弃了180字节的数据。
shell$ sudo iptables -L -v
Chain INPUT (policy ACCEPT 1770 packets, 267K bytes)
pkts bytes target prot opt in out source destination
3 180 DROP all -- any any 10.219.201.12 anywhere
最后使用如下命令将刚才的规则清楚,从新用curl访问这个网站验证效果:
shellsudo iptables -t filter -F INPUT
上面的规则还是稍微扩展一下,iptables 支持 CIDR 来屏蔽整个网段,下面这命令表示将以10.219.201.x的IP都进行屏蔽
shellsudo iptables -t filter -I INPUT -s 10.219.201.12/24 -j DROP
使用-d将发往某个IP的流浪丢弃.
shelliptables -A OUTPUT -d 31.13.78.35 -j DROP
DROP和REJECT有什么区别呢?从实际的使用角度来说:
DROP: 直接将packet 丢弃,并且不会返回任何错误信息
REJCT : 网络包也会被丢弃,但是会返回一些网络信息
还是以上边的8080端口的 http 服务为例,当 target 为 REJECT 时,效果如下:
shell$ curl 10.219.204.164:8080
curl: (7) Failed to connect to 10.219.204.164 port 8080 after 0 ms: Connection refused
而DROP会让HTTP持续阻塞。
操作端口
有时候操作整个 IP 太大了,操作端口是更细粒度的控制,就一上一小节的例子,我们可以只屏蔽发往 8080端口的流量。那么效果就是 HTTP 请求不可达,但是 ICMP 请求仍然可达。注意,如果需要指定端口号那么还需要使用-p参数指定协议,毕竟端口号只有在TCP和UDP才有意义。
shellsudo iptables -t filter -I INPUT -p tcp --dport 8080 -j REJECT
或者是,将IP与端口号放一起,下面表示收到来自192.168.0.1的报文且目标端口为8080的报文都被REJECT
shellsudo iptables -t filter -I INPUT -p tcp --dport 8080 -s 192.168.0.1 -j REJECT
还可以同时匹配多个端口,下面表示将发向 22 和 8080 的报文全部都 DROP.参数-m表示加载某个模块,至于模块的内容后面再描述。注意 multiport 只能用在TCP与UDP 协议。
shellsudo iptables -t filter -I INPUT -p tcp -m multiport --dports 22,8080 -s 59.45.175.0/24 -j DROP
除了dport表示目的端口,自然的也有sport表示源端口,使用方式类似,不多赘述。
操作网卡
我们可以屏蔽任何来自非loopback的流量,如下,感叹号!的意思是对逻辑取反,就如同 编程语言中那样,还有相当多的选项支持取反的操作,文档有很详细的描述。
shellsudo iptables -t filter -A INPUT ! -i lo -j REJECT
危险! 这命令一敲完,ssh 就无法在访问我的虚拟机了,因为ssh也不是来自loopback的流量。不过好在之前的操作对于 iptables 都是临时的,只要重新启动机器以后这些配置就会被重设.
注意-i参数作用的指定进入的网卡,它只能作用于PREROUTING和FORWARD 链。与之相对应的是-o指定出去的网卡,它只能作用于FORWARD与OUTPUT链,使用方法相类似,不多赘述。
多规则满足
如果一个报文同时满足多条规则,iptables 会如何处理? 实验来验证结果,还是以8080端口的 HTTP 服务器为例子,分别增加一条ACCEPT和DROP 规则:
shell$ sudo iptables -t filter -A INPUT -p tcp --dport 8080 -j REJECT
$ sudo iptables -t filter -A INPUT -p tcp --dport 8080 -j ACCEPT
$ sudo iptables -L
target prot opt source destination
REJECT tcp -- anywhere anywhere tcp dpt:http-alt reject-with icmp-port-unreachable
ACCEPT tcp -- anywhere anywhere tcp dpt:http-alt
然后测试,发现是无法访问的。显然 iptables的规则在遇到一条结果成立以后就直接返回了,而不会遍历所有规则:
shell$ curl 10.219.204.164:8080
curl: (7) Failed to connect to 10.219.204.164 port 8080 after 0 ms: Connection refused
扩展
前面针对的都是 iptables 的基本功能,实际上 iptables 的功能很大程度上来源于它的扩展功能,分别是 match extension 和 target exntension,这些扩展功能被广泛地用在 Docker 以及 K8s 中。正式对这些扩展功能介绍介绍-j参数,在之前的例子中我们只使用-j来DROP,ACCEPT,REJECT,不过它还支持跳转到自定义链和被扩展动作(target extension)处理。使用参数-m来指定我们所使用的扩展。值得一提的是,先前的例子使用-p tcp来表示我们操作的是TCP,实际上已经默认的将tcp模块加载了。
Match extension
匹配扩展的作用引入了额外的匹配选项。
-
addrtype: 对地址类型进行匹配,常见的类型有: Local,UNSPECT,BROADCAST等
-
account: 用于统计网络流量
shelliptables -A INPUT -p tcp --dport 80 -m account --aname mywwwserver --aaddr 192.168.0.0/24 --ashort上述例子表示将目标IP为
192.168.0.0/24:80流量记录到mywwwserver中,记录的数据使用如下命令查看:shellcat /proc/net/ipt_account/mynetwork # cat /proc/net/ipt_account/mywwwserver -
comment: 对一条规则做注释
shelliptables -A INPUT -s 192.168.0.0/16 -m comment --comment "A privatized IP block" -
connlimit: 限制对某个IP的TCP 连接数量
shelliptables -p tcp --syn --dport 23 -m connlimit --connlimit-above 2 -j REJECT上述命令表示如果对于端口23的TCP链接数量超过了2就将
syn报文丢弃,于是TCP链接再也不能建立了。 -
conmmark: 匹配那些被打了标记的链接的报文。那么谁来对一个网络连接打标记呢?是target CONNMARK 后面会介绍,这个扩展功能被k8s使用到了。
-
conntrack: 如果我们以ssh登录到了一台机器,然后设置了一条规则将22端口的流量全给DROP了,这会直接导致我们此时的ssh连接的流量也被完全丢弃,只能重启机器(iptables的修改如果没有保存将会在重启之后被重置)。iptables是有状态的,我们可以根据此时的网络状态对报文进行操作。以ssh为例,可以设置对于已经建立的网络连接的packet一律放行。iptables 所支持的状态如下:
下面是所支持的模块:
- NEW: 链接的第一个packet,我们可以设置将每个连接的第一个 packet 放行
- ESTABLISHED: packet 是处于现存的一些网络连接的,以前面的ssh为例,我们就可以设置对于现存的ssh连接的packet都通通放行
- RELATED: 此时的网络连接与一个处于established 状态的网络连接是相关的。
- INVALID: packet的状态不正确
- DNAT: 这状态指代的是一个网络报已经经过 nat 表进行目的网络地址转换
- SNAT: 类似DNAT,表示packet已经被 nat 源地址转换
- UNTRACKED: 表明这个网络包已经经过 raw 表并且 raw 表对其的处理动作是 NOTRACK。
下面是一些示例,表示对处理
ESTABLISHED和RELATED状态的包全部放行:iptables -A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT丢弃任何处于
INVALID状态的packet:shelliptables -A INPUT -m conntrack --ctstate INVALID -j DROP -
mark: 匹配一个打了标记的报文,注意与connmark进行区分。target MARK 的作用就是给报文打上标记。
-
iprange: 匹配 IP 地址范围。
其他的匹配扩展还有很多,查阅文档即可。如果你好奇kube-porxy是如何使用iptables的,可以参考这篇文档,kube-proxy所用的一些扩展在 man 里边没找到。
Target extension
除了DROP,REHECT,ACCEPT这几个基础的target以外,还有相当多的扩展 target,下面也是一些举例。
-
CONNMARK: 对一个网络连接打标记。与 match extension 的 conmmark 搭配使用。
-
DNAT: 对目标网络地址进行重写,它只能用在 nat 表的 PREROUTING 和 OUTPUT 链,以及从这两个中可以跳转到的用户自定义链。它只有一个选项
--to-destination表示要重写为的IP地址以及端口,DNAT使用场景是外部流量到达内部网络的场景。 -
LOG: 被匹配的报文会让内核输出一条日志信息就像
syslog所作的。注意,这个 target 是 non terminating target。 -
MARK: 对满足匹配规则的网络包打上一个标记,它只能被用在mangle 表中。
-
MASQUERADE: 作用是进行 SNAT,不过对于出去的流量是动态绑定的,取决于流量会从哪个IP出去,这对于随机分配IP的情况是很有用的,因为一台机器的IP会随着重启或者是IP过期等情况而导致它的IP地址变化。这只能用在nat表的 POSTROUTING 链。示例:
shelliptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE表示将任何从eth0网卡出去的网络包都进行SNAT。
-
REDIRECT: 作用是将一个网络包的目的地址重写为机器本身,这就是HTTP代理的功能。比如说访问一个example.com的流量就被redirect当前主机的8080端口,然后proxy可以进行一些处理在发出去。它只能用于nat 表的 PREROUTING和OUTPUT链。示例如下:
shelliptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080将目标端口为80的利郎转发到8080端口,这就是端口转发的基本例子。注意这不同于 docker 的端口转发。
-
TTL: 用于设置 IPv4 header的 TTL字段。
-
RETURN: RETURN means stop traversing this chain and resume at the next rule in the previous (calling) chain。结束在当前链上的旅途,回到调用规则所属的调用链的下一条规则。这里的意思是:在链A的一条规则跳到了链B,B当中的规则的处理动作是RETURN,处理完了以后就回到了A的调用规则的下一条规则,就如同编程语言的return一样。
Docker 与 iptables
当docker安装好了以后,会在 nat 和 filter 表内插入一些规则。我们主要探究的是 iptables 在 docker 容器与宿主机的端口转发、外部网络之间起到什么作用。首先是查看安装docker以后所加入的规则。至于容器与容器之间的流量是怎么走的,其实所有的工作都被docker0承担了,这并不是本篇的主要内容,略。
另外回顾一下数据包在一台机器上的路途:
对于目标主机就是当前主机的网络包,经过的路径是: PREROUTING-> INPUT
对于要转发的网络包,从当前主机经过的路径是: PREROUTING->FORWARD->POSTROUTING
从当前主机出去的数据包:OUTPUT->POSTROUINT
安装docker以后nat表的规则如下,nat 表上默认的链为: PREROUTING,OUTPUT,POSTROUTING
shell$ sudo iptables -t nat -S
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-N DOCKER
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
逐行解释这些内容。
- 前几行的
-P PREROUTING ACCEPT是nat 表的默认策略都是 ACCEPT 没啥好说的 -N DOCKER创建了一条名为 DOCKER 的自定义链-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER匹配任何目标地址为LOCAL的报文,这里目标地址为指代的是当前机器上任何网络设备所绑定的IP,包括eth0,loopback。这些网络包都会被DOCKER这条自定义链所处理-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER对于出去的流量,且目标IP不是127.x.x.x的流量,都给DOCKER链处理-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE对于任何源IP为127.17.x.x并且不是从docker 0出去的(意思是走向外部网络的流量)都进行 SNAT(MASQUERADE的意思可以等同于SNAT)。-A DOCKER -i docker0 -j RETURN往 DOCKER 这条chain加一条规则,但是啥也没干直接RETURN,后续的操作交给PREROUTING
回想一个最基本的问题,docker 容器是如何访问外部网络的? 很显然,经过了iptables处理以后源IP被NAT为了当前主机上的物理网卡。剩下一个问题是,当外部外部流量回到容器内的,稍后介绍。
安装docker以后filter表的内容如下,filter表上有的链为: INPUT,FORWARD,OUTPUT
shell$ sudo iptables -t filter -S
-P INPUT ACCEPT
-P FORWARD DROP
-P OUTPUT ACCEPT
-N DOCKER
-N DOCKER-ISOLATION-STAGE-1
-N DOCKER-ISOLATION-STAGE-2
-N DOCKER-USER
-A FORWARD -j DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION-STAGE-1
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
-A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
-A DOCKER-USER -j RETURN
- 开始几行内容很简单,插入了几条自定义链:
DOCKER,DOCKER-ISOLATION-STAGE-1,DOCKER-ISOLATION-STAGE-2,DOCKER-USER - 后面两条规则都表示任何流量到达的时候都会先经过
DOCKER-USER和DOCKER-ISOLATION-STAGE-1。不过此时这两条自定义连啥规则也没有,都是RETURN。 -A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT根据状态来放行流量,也是在这里进行了返回容器访问外部网络以后所返回的网络包的DNAT,相关内容参考这里。FORWARD -o docker0 -j DOCKER再被Docker这条自定义链的规则处理。目前也也没有任何相关规则-A FORWARD -i docker0 ! -o docker0 -j ACCEPT对于来自docker0,但是出去的网卡不是docker0的流量一律放行-A FORWARD -i docker0 -o docker0 -j ACCEPT对于来自docker0,但是出去的网卡是docker0的流量一律放行- 后面几条规则都没什么内容了,就是是链的跳转和return
端口转发
使用nginx来做实验,使用宿主机进行端口映射:
shell$ docker run --name mynginx1 -p 80:80 -d nginx
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0ba99d308c44 nginx "/docker-entrypoint.…" 51 seconds ago Up 51 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp mynginx1
$ docker inspect -f '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' mynginx1
172.17.0.2
$ curl localhost:80
# 省略了nginx的输出结果
整个过程分为两部分,从宿主机发消息给nginx已经nginx将信息返回,一来一回。可以遇见的是,首先需要将发送给localhost:80记性端口以及目的IP替容器的端口和IP。这发生在 nat 表,当我们执行了端口转发 docker 就往 Docker 这条自定义链加入了一条新的规则:
shell-A DOCKER ! -i docker0 -p tcp -m tcp --dport 80 -j DNAT --to-destination 172.17.0.2:80
就和先前的描述一样,它的意思是: 将来自非 docker0的容量(走的是eth0),目标端口为80的tcp流量进行DNAT,重写为172.17.0.2:80。
nat表中还有一条新增规则是:
shell-A POSTROUTING -s 172.18.0.2/32 -d 172.18.0.2/32 -p tcp -m tcp --dport 6379 -j MASQUERADE
这一条的作用不是特别明确,看字面意思就是对容器到容器之间的流量进行SNAT,不明白这样做的目的是啥。
与容器的直接通信
在宿主机上,直接使用ping容器也是可行的,因为在宿主机的路由表当中已经配置了相关路由:
shell172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
不过除此意外 iptables 也有额外的操作,filter表中加入了一条:
shell-A DOCKER -d 172.17.0.2/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 80 -j ACCEPT
表示不是从docker0进入的,不过是从docker0出去的,目标地址为172.17.0.2/32的网络包直接放行。我们发起ping的时候出去的网卡应该是eth0(不确定,至少不是docker0),然后路由查表得到这条流量要走docker0出去,后面就是nat表的工作了。一个小疑问是: 路由查表到底是位于iptables之前还是之后,按照wiki对于上iptables一幅图,路由决策是发生在iptables之前的。
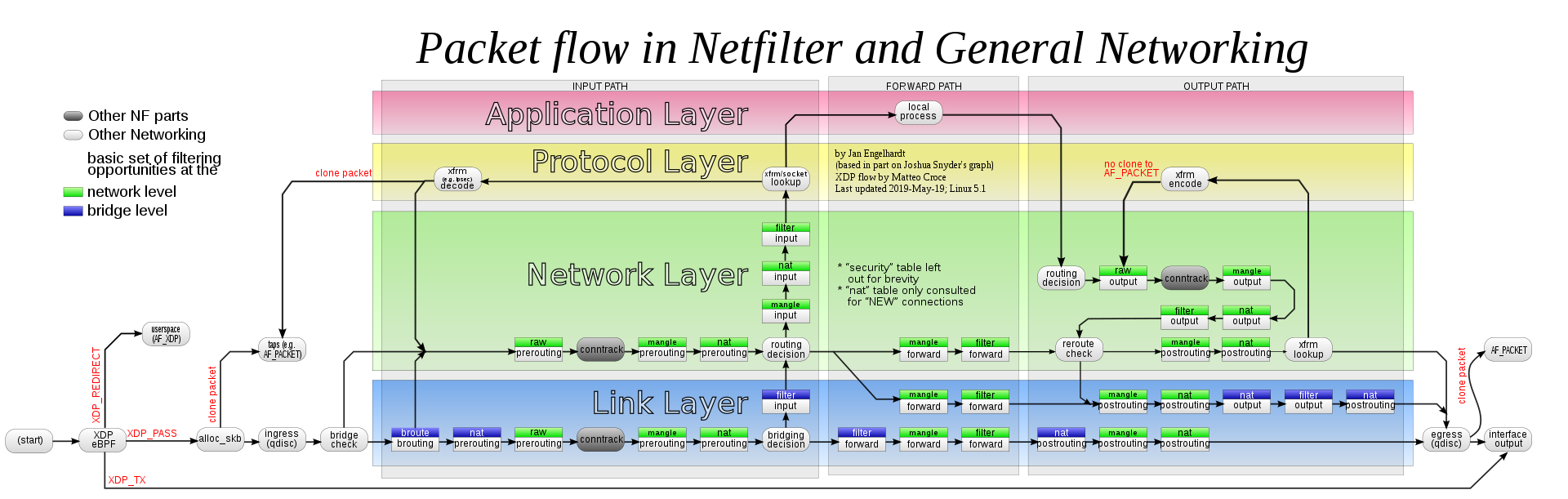
一个问题是: 为什么 docker 的规则都设置在了filter表的 forward 链 ?
我一开始的理解是,容器怎么说也是当前主机的进程,不会经过 forward 链毕竟这是转发网络流量才需要的链。暂时未找到官方文档的说明,我自己的理解是对于返回到容器的流量是需要被 DNAT下一步才是进行路由决策(参考上图)。经过DNAT之后内核会发现目标IP与当前主机上任何一个网络设备的IP都不符,所以应该会认为这不是只想宿主机的流量,路由查表以后就把流量转发到 docker 0 bridge了。
经查证,因为容器的流量都要经过docker0(它是一个网桥)转发,网桥(bridge)的流量转发都需要经过iptables的FORWARD,参考stackoverflow。
结语
写这篇文章的初衷是在学习k8s网络中发现 iptables 在实现service 当中很有作用,直接查看 iptables 不少内容不懂,就开了一片文章进行系统的学习。最后稍微过了一下docker是如何基于实 iptables 实现宿主机到容器的端口转发的。至于 k8s 网络打算专门开长文学习并且介绍 cni 和 k8s 网络相关内容。
参考资料
https://linux.die.net/man/8/iptables
https://manpages.debian.org/unstable/iptables/iptables-extensions.8.en.html
https://thiscute.world/posts/iptables-and-container-networks
https://www.zsythink.net/archives/category/%e8%bf%90%e7%bb%b4%e7%9b%b8%e5%85%b3/iptables
https://www.booleanworld.com/depth-guide-iptables-linux-firewall/
本文作者:strickland
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!