目录
用户请求到达实际的服务往往经过多轮的负载均衡,这给问题排查带来了额外的难度。在一个 k8s 集群当中,网关(ingress nginx,kong)以nodeport的形式作为集群外负载均衡的后端。最近遇到的问题业务反馈网关负载均衡效果不好,因此我的方案是在kong节点上分析http报文,这可以帮助我们分析是ipvs -> nodeport还是网关->业务pod的负载均衡问题。我借助了BPF_PROG_TYPE_SOCKET_FILTER实现了一个简单的链路最终工具,抓取kong pod的报文。
Raw Socket
一般的socket编程接收的都是 TCP/UDP 数据,而是用raw socket 可以直接获取到整个报文的内容,因此我们可以从中提取出报文的信息,观测网络。下面语句创建一个row socket,接受所有的链路层帧:
c#include <sys/socket.h>
#include <linux/if_packet.h>
#include <net/ethernet.h> /* the L2 protocols */
s = socket(AF_PACKET,SOCK_RAW,htons(ETH_P_ALL));
对于raw socket,第一个参数只能为AF_PACKET,第二个参数还可以取SOCK_DGRAM它将packet里的链路层header移除。第三个参数指定了我们所关注的是哪些协议,htons(ETH_P_ALL)表示接受所有协议的报文,其他取值可以看头文件 <linux/if_ether.h>。这种类型的socket(packet socket)可以捕获到机器上所有发送和接受到的packet(这里的捕获有些歧义,实际上操作的是原始报文的拷贝)。默认情况下,raw socket处理所有设备上的packet,可以使用bind来指定某一个设备。
BPF_PROG_TYPE_SOCKET_FILTER 和 tcpdump 息息相关,它可能是最早出现的BPF程序类型。一种BPF程序类型,需要关注的是它提供的参数、如何挂载、何时被调,我们可以从内核代码中照葫芦画瓢,这份代码的作用是以ipv4 header中 protocol作为index来统计收到的每种类型的报文的数量。
cint bpf_prog1(struct __sk_buff *skb)
{
int index = load_byte(skb, ETH_HLEN + offsetof(struct iphdr, protocol));
long *value;
if (skb->pkt_type != PACKET_OUTGOING)
return 0;
value = bpf_map_lookup_elem(&my_map, &index);
if (value)
__sync_fetch_and_add(value, skb->len);
return 0;
}
参数struct __sk_buff *skb是一个简化版struct sk_buff,程序中所访问的skb的结构体会被BPF verifier转为struct sk_buff中实际的结构体。如果要访问packet中的数据,可以使用bpf_skb_load_bytes函数,从linux 4.7 开始访问 packet 的数据可以直接使用direct packet access,不过我没有在 socket filter中尝试使用这种方法,TC BPF 是有这种用法的,可以参考我之前的文章。load_byte 等一系列函数(还有loadword,loadhalf)是LLVM提供的几个函数,可以看作和bpf_skb_load_bytes等效,这些函数的源码:
cunsigned long long load_byte(void *skb, unsigned long long off) asm("llvm.bpf.load.byte");
unsigned long long load_half(void *skb, unsigned long long off) asm("llvm.bpf.load.half");
unsigned long long load_word(void *skb, unsigned long long off) asm("llvm.bpf.load.word");
如何挂载 socket filter,这部分也可以参考内核代码:
cprog_fd = bpf_program__fd(prog);
map_fd = bpf_object__find_map_fd_by_name(obj, "my_map");
// open_raw_sock 核心的就是 socket(AF_PACKET,SOCK_RAW,htons(ETH_P_ALL)); 创建这样一个socket
sock = open_raw_sock("lo");
assert(setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd,
sizeof(prog_fd)) == 0);
挂载该类型 BPF 程序关键代码是setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd,sizeof(prog_fd)) == 0,第二个参数SOL_SOCKET表示我们要改变socket本身的一些属性,SO_ATTACH_BPF表示要加载一个bpf程序,&prog_fd被加载的bpf程序 fd。
BPF_PROG_TYPE_SOCKET_FILTER的返回值为0表示将这个packet丢弃,小于原先的报文则表示将packet truncate。不过,socket filter操作的并不是实际的packet,原始的packet还是会到达目的socket,我们实际操作的是packet是供raw socket观测的。下面引用自参考文档一:
Note that we're not trimming or dropping the original packet which would still reach the intended socket intact; we're working with a copy of the packet metadata which raw sockets can access for observability.
socket filter 的hook 点在sock_queue_rcv_skb函数,内核源码如下:
cint sock_queue_rcv_skb(struct sock *sk, struct sk_buff *skb)
{
err = sk_filter(sk, skb); // 执行 BPF 代码,这里返回的 err 表示对这个包保留前多少字节(trim)
if (err) // 如果字节数大于 0
return err; // 跳过接下来的处理逻辑,直接返回到更上层
// 如果字节数等于 0,继续执行内核正常的 socket receive 逻辑
return __sock_queue_rcv_skb(sk, skb);
}
网上文档和源码来看似乎socket filter只能用于inbound traffic,那为什么tcpdump可以同时抓包到处和入的流量呢? 这部分我没有很深入的琢磨,我想原因还是在于raw socket吧。
实现链路追踪
BPF 程序
我的目的是用 socket filter抓取 kong网关上的 HTTP 报文,这个repo有个相类似的实现,可以作为参考。工具实现要做的是:
- bpf程序从
struct __sk_buff中解析出各层header,根据端口放行我们所关注的报文 - raw socket程序负责报文的解析(因为raw socket收到的还是链路层帧),提取出 HTTP 报文。
- 给测试用的 HTTP 报文增加额外的header,将 HTTP 报文区分开
如何知道哪些报文是kong pod发出的?这实际上和集群的CNI有关,我们集群用的都是 calico 的cross subnet模式,即同子网直连,跨子网用IPIP。我们在kong节点上按照目的 pod的端口抓包即可,下面是示例程序:
cif (ip.protocol == IPPROTO_TCP) {
if (bpf_skb_load_bytes(skb,offset,&tcp,sizeof(struct tcphdr)) < 0) {
return DROP;
}
// 只保留目标端口的报文,其他的全部丢弃
if (target_port == -1 || bpf_ntohs(tcp.dest) == target_port || bpf_ntohs(tcp.source) == target_port) {
return KEEP;
}
} else if (ip.protocol == IPPROTO_IPIP) {
// IPIP v4
struct iphdr inner_ip_hdr;
if (bpf_skb_load_bytes(skb,offset,&inner_ip_hdr,sizeof(struct iphdr)) < 0) {
return DROP;
}
offset += inner_ip_hdr.ihl * 4;
if (bpf_skb_load_bytes(skb,offset,&tcp,sizeof(struct tcphdr)) < 0) {
return DROP;
}
if (target_port == -1 || bpf_ntohs(tcp.dest) == target_port || bpf_ntohs(tcp.source) == target_port) {
return KEEP;
}
}
// 丢弃其他所有不相关的报文
return DROP;
用户态程序
ebpf-go是可以让我们用go来编写ebpf 程序,相当方便。这个仓库有一个PR提交了关于 socket filter的示例,虽然没有被合并,可以作为参考。挂载 ebpf 程序和C程序没有区别,只不过以 go 的形式:
gosockFD, err = syscall.Socket(syscall.AF_PACKET, syscall.SOCK_RAW|syscall.SOCK_CLOEXEC, int(htons(syscall.ETH_P_ALL)))
if err != nil {
return -1, err
}
if err = syscall.SetsockoptInt(sockFD, syscall.SOL_SOCKET, unix.SO_ATTACH_BPF, ebpfProgFD); err != nil {
return -1, err
}
// 设置所要绑定的设备
sll := syscall.SockaddrLinklayer{
Ifindex: netInterface.Index,
Protocol: htons(syscall.ETH_P_ALL),
}
raw socket 读取到的是链路层帧,对于任何上层协议的解析都需要我们自己实现,可以使用gopacket来帮我们解析报文。解析报文一个棘手的地方是重新构建TCP流,gopacket提供了assembler来离散的IP报文重新拼接为完整的HTTP报文,这块用法我也没深究。我的想法是测试所用发送的http报文都很短,一个MTU就可以涵盖,所以不需要进行重组似乎也可以。下面是gopacket的一个使用示例:
gofor {
buf := make([]byte, 65535)
// 从 raw socket 读取数据放到buf
n, _, err := syscall.Recvfrom(fd, buf, 0)
if err != nil {
log.Fatalf("read data from socket error:%v", err)
return
}
buf = buf[:n]
// 将链路层帧解析为以太网帧
packetSource := gopacket.NewPacket(buf, layers.LayerTypeEthernet, gopacket.Default)
if packetSource.NetworkLayer() == nil {
return
}
// 其他方面也差不多,照葫芦画瓢解析出各层的内容
}
解析到 TCP 报文以后,它的数据部分就是 HTTP 报文的内容,直接使用http包帮我们解析 HTTP 报文的内容:
goreader := bufio.NewReader(bytes.NewReader(tcpPacket.Payload))
if isHttpRequest(tcpPacket.Payload) {
// 解析 http header
httpReq, err := http.ReadRequest(reader)
}
最后是脚本的运行截图,我要捕捉的是kong pod往后端pod(29090)端口转发的所有报文:
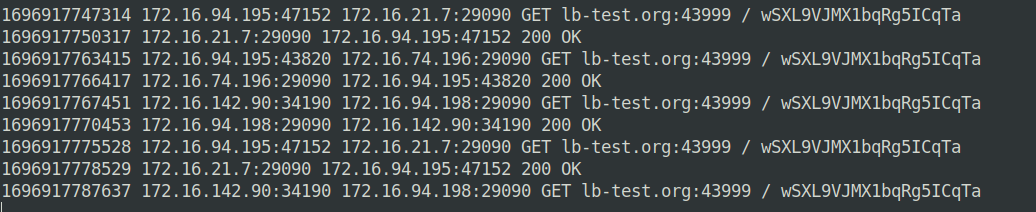
kong pod往往很多个,收集日志很麻烦,可以额外增加一个中心节点,专门用于收集日志。
遇到的问题
BPF相关的资料都零零散散,一开始参考内核代码遇到了不少问题
编译内核示例 bpf 程序的命令的命令:
shell# -g 是必要的,用于产生 BTF section
clang -target bpf -g -c -O2 bpf_sock_kern.c -o bpf_sock_kern.o
# or
clang -O2 -emit-llvm -c -g bpf_sock_kern.c -o - | \
llc -march=bpf -mcpu=probe -filetype=obj -o bpf_sock_kern.o
# must specify use libbpf
gcc -o bpf_sock bpf_sock_user.c -lbpf
# 运行程序
sudo su
./bpf_sock
# 程序运行结果
TCP 0 UDP 0 ICMP 0 bytes
TCP 0 UDP 0 ICMP 196 bytes
TCP 0 UDP 0 ICMP 392 bytes
TCP 0 UDP 0 ICMP 588 bytes
TCP 0 UDP 0 ICMP 784 bytes
下面对这些下面是问题记录:
- 提示找不到
bpf_object__open_file,但是相关头文件已经引入。问题原因是编译没有链接libbpf,在gcc后面加上-lbpf即可。参考自这里 - 找不到
bpf_object__next_program函数,这是因为通过apt install libbpf-dev所安装的libbpf缺失该函数,解决办法是从github的libbpf 仓库拉Libbpf手动编译安装 - 编译找不到
asm/types.h,该头文件位于/usr/include/x86_64-linux-gnu/asm,使用ln -s /usr/include/x86_64-linux-gnu/asm asm在user/include目录下创建symbolic link即可 libraries: libbpf.so.1找不到。 这应该和ld默认的链接库search path有关,ld是从哪儿开始寻找的暂时没有深究,至少/usr/lib64不是ld的默认路径之一。参考这儿。解决方法就是,要么指定shared library的路径,或者是在环境变量加上export LD_LIBRARY_PATH=/usr/lib64:$LD_LIBRARY_PATH(不知道为什么加载home下的.zshrc无效,我直接加到了/etc/bash.bashrc内)。- mem limit导致bpf map创建失败,因为非root进程的mem是有限的,所以直接
sudo su运行该程序就完了,该问题参考这儿。 - 提示 No BTF 错误,但是ubuntu 22.04 内核是有BTF 支持,实际上该问题是因为编译的时候没有产生 debug info,在
clang命令加上-g。参考这儿。 - clang 编译warning 提示没有
load_byte,一般情况下我对于 warning都是忽略的,这直接导致了后面bpf程序无法经过verifier。原因暂时未知,不过直接从内核复制一份相关的代码出来就行。我在程序中就是这样做的,内核源码地址。
参考资料
https://blogs.oracle.com/linux/post/bpf-a-tour-of-program-types 介绍了一些BPF程序类型
https://ebpf-docs.dylanreimerink.nl/linux/program-type/BPF_PROG_TYPE_SOCKET_FILTER/ 作者是一个bpf大佬,他正在维护一个bpf相关的文档
https://medium.com/@c0ngwang/understanding-struct-sk-buff-730cf847a722 介绍了struct __sk_buff的内容
http://arthurchiao.art/blog/bpf-advanced-notes-1-zh/ 介绍了各种BPF程序类型
本文作者:strickland
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!